TiDB数据库架构——TiDB Server
TiDB Server架构
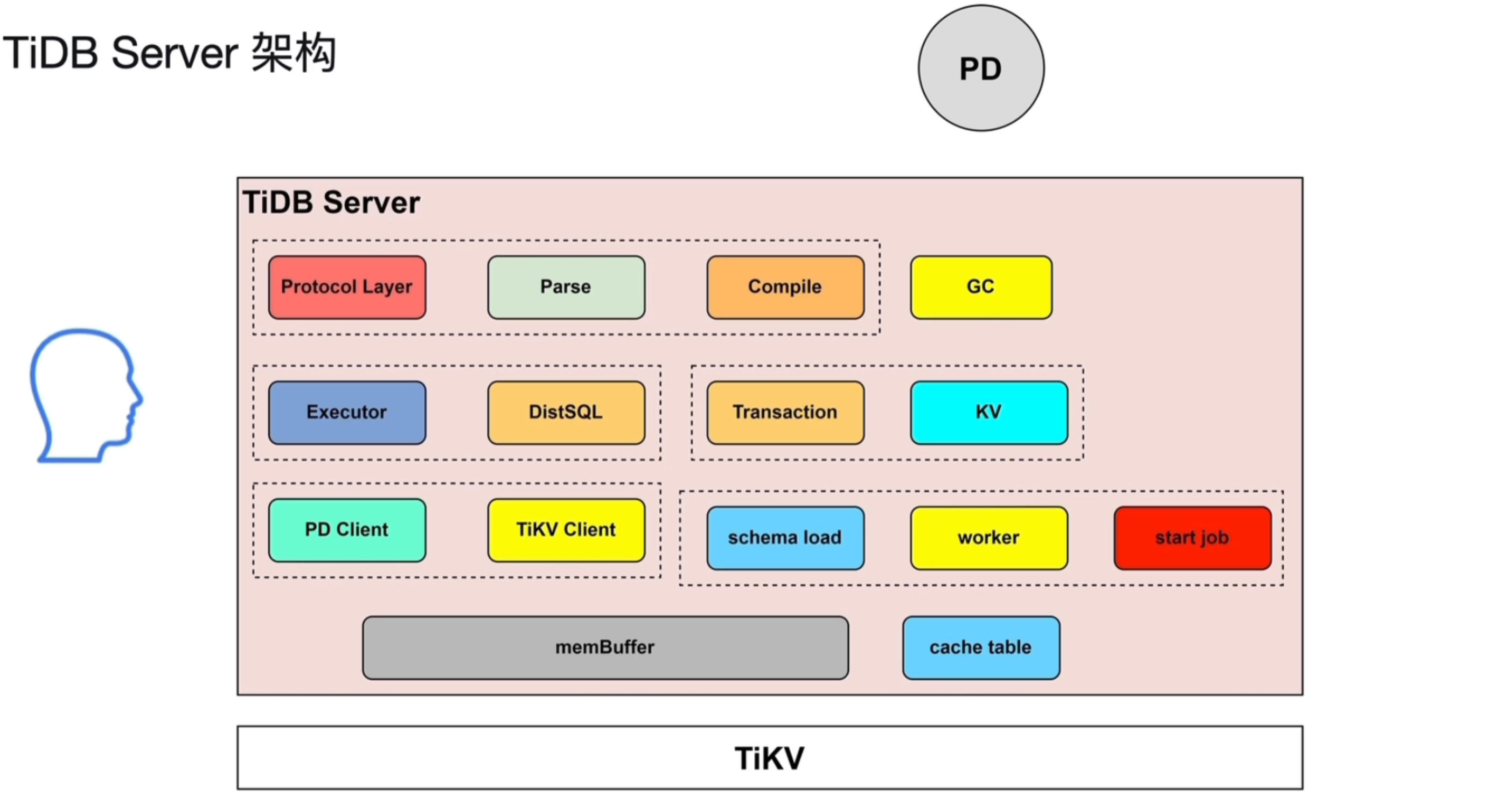
TiDB Server 是SQL层,无状态,启动多个TiDBServer,均匀分摊,解析SQL,获取真实数据。
Protocol Layer、:负责客户端的连接。
Parse、Compile:负责SQL语句的解析和编译,生成SQL语句的执行计划。交给下面的Executor
Transaction、KV:负责事务的处理,
PD Client、TiKVClient:负责连接
schema load、worker、start job:负责online DDL语句的执行,建表,建索引
memBuffer:缓冲区,比如登入信息
cache table:实现热点小表缓存,提高表的吞吐量
TiDB Server 主要功能
- 处理客户端的连接
- SQL语句的解析和编译
- SQL语句的解析和编译
- 关系型数据与KV的转化
- SQL语句的执行
Online DDL的执行- 垃圾回收
- 热点小表缓存V6.0
SQL语句的解析和编译
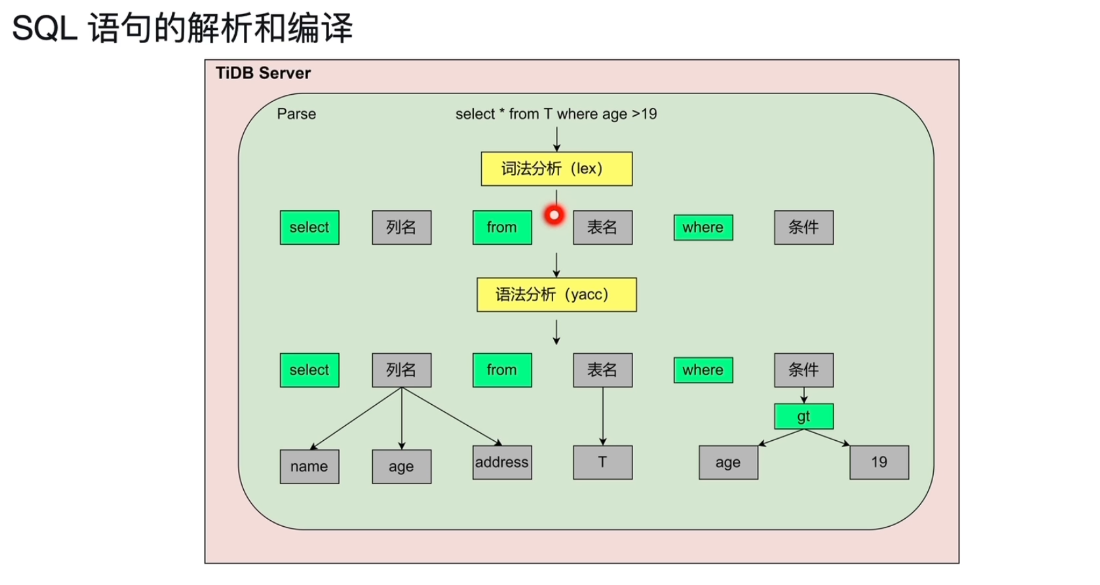
生成AST语法树传递给Compiler模块,树形结构,进行编译和优化
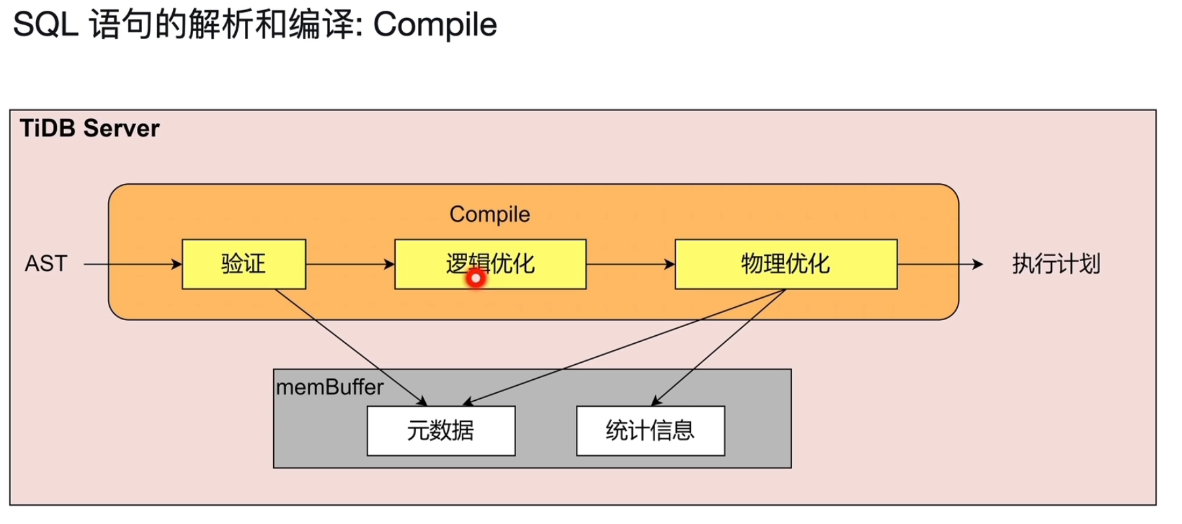
物理优化:走索引还是全表扫描,通过统计信息,进行一个优化
KV的转化
聚簇表:
KEY:表号+主键
VALUE:数据
非聚簇表:使用主键作为KEY

一个region,默认96MB,超过144MB,会进行分裂操作。
SQL读写相关模块
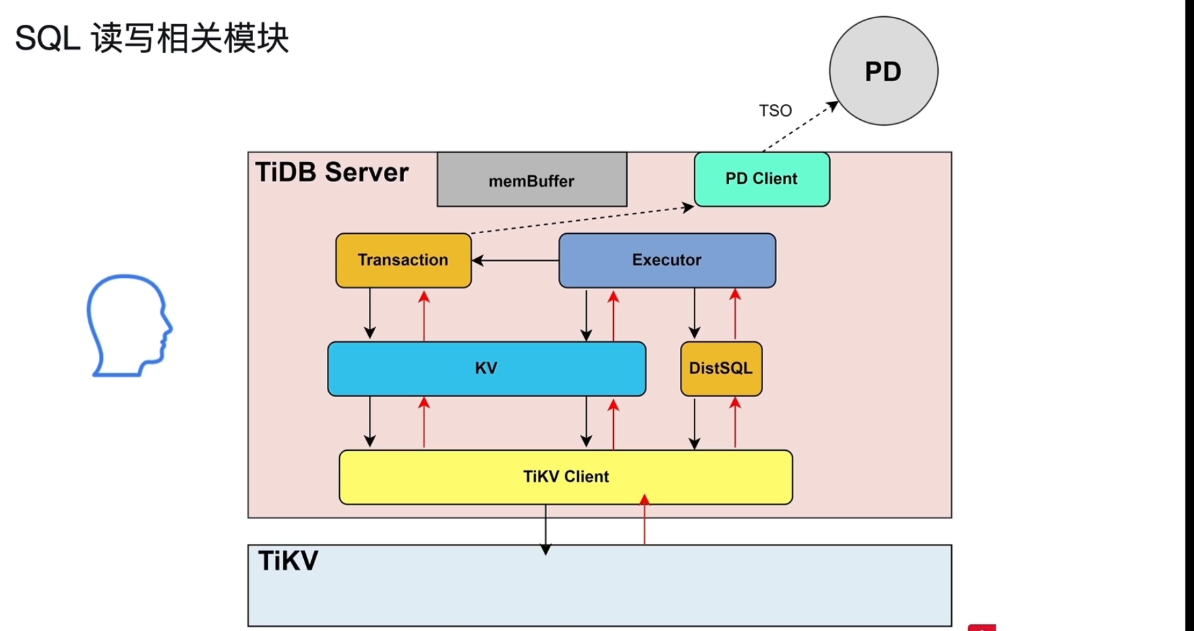
DistSQL:为了减少耦合度过高的问题。复杂SQL经过DistSQL都会变成单表的SQL语句,然后发送到TiKV。
KV:只查一行或者0行,点查,走KV模块,复杂SQL走DistSQL。
TiKV Client:通过这个将解析之后的SQL发送给TiKV
PD Client:发送TSO
在线DDL相关模块
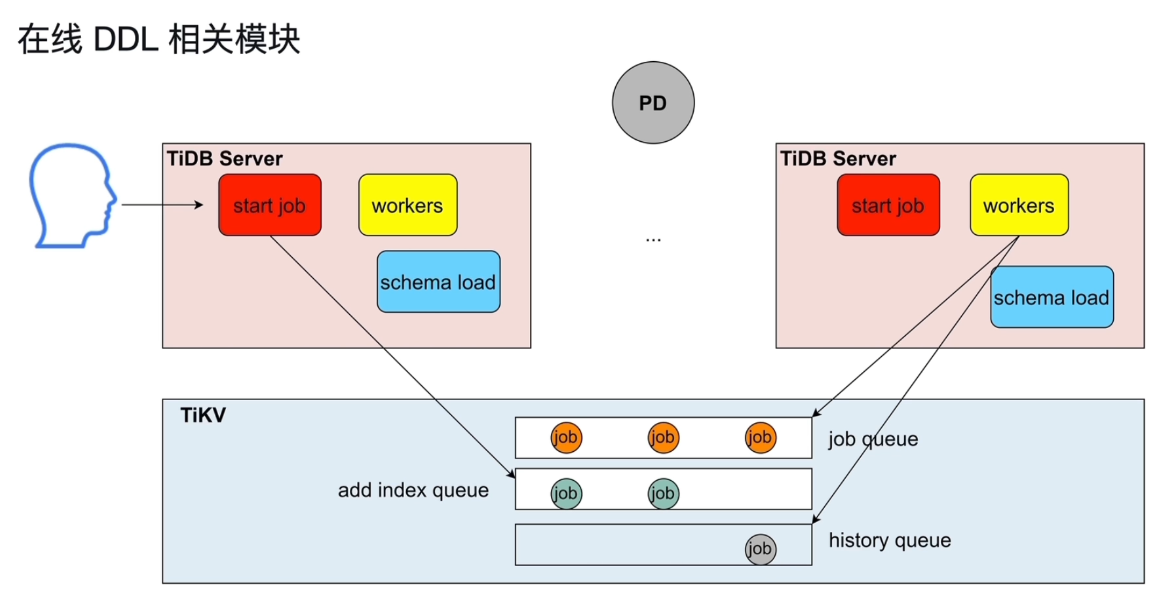
同一时刻只能有一个TIDBServer进行操作
DDL语句由start job接收,放入 TiKV job队列当中,所有的start job都可以接收,都放入队列当中,只有一个worker进行操作叫做owner,执行完就放入历史队列当中。在一段时间内是owner,过了这段时间可能会重新发起选举。这一做法可以防止宕机,一个TiDBServer宕机之后,别的TiDBServer可以继续执行DDL语句。
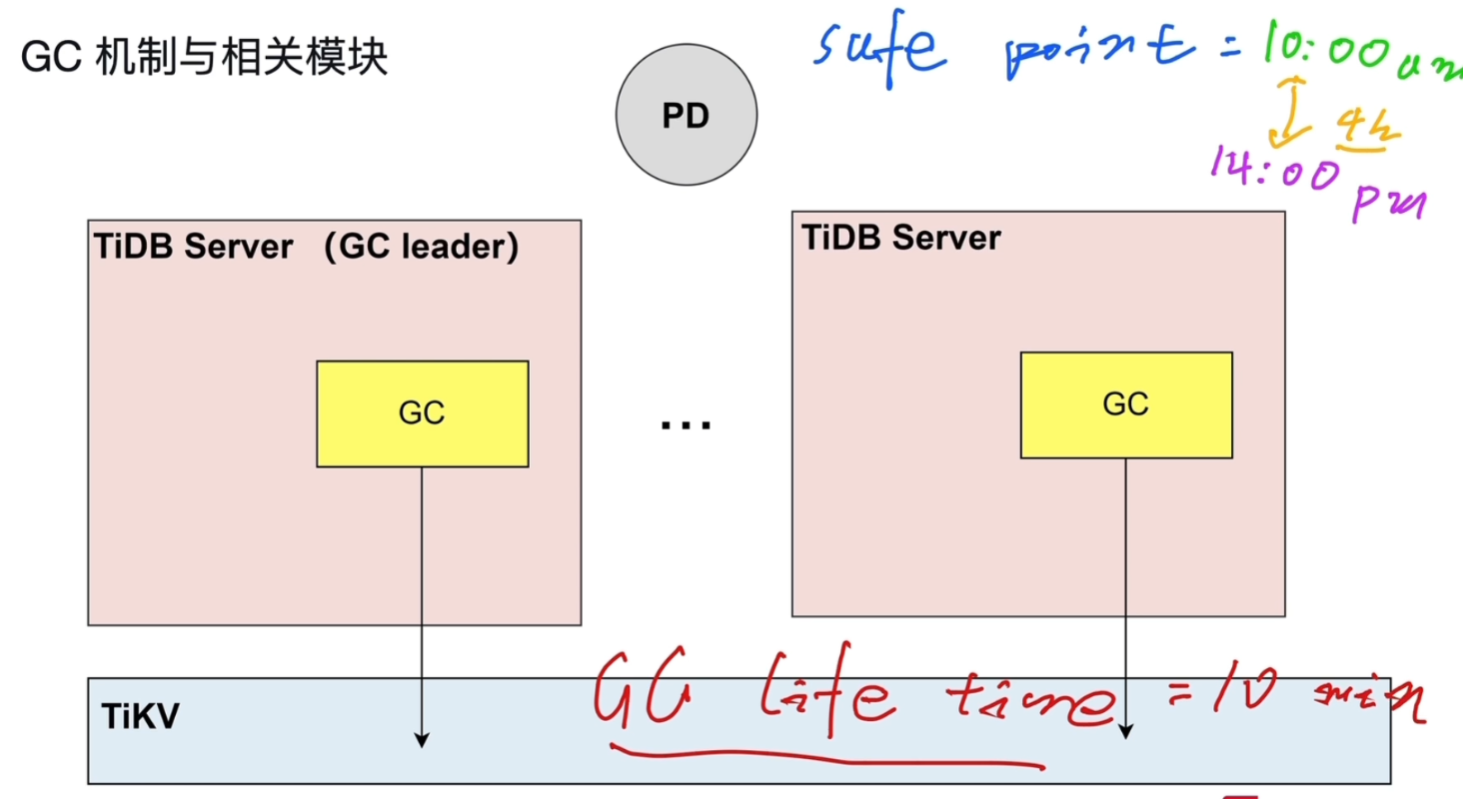
GC 机制与相关模块
GC life time:在所有TiDBServer当中会选举一个GC leader,在一个时间段的历史数据会进行保留,不在在时间段之内的数据就让GC回收。默认十分钟。
TiDB Server的缓存
TiDB Server缓存组成
- SQL结果
- 线程缓存
- 元数据,统计信息
TiDB Server 换粗管理(两个参数)
tidb_mem_qutota_query每条SQL占用缓存的大小oom-action超过大小,返回错误或者记录日志
结果散落在多个节点,将数据放入缓存中,将各个节点的数据回合起来。
热点小表缓存
- 表的数据量不大
- 只读表或者修改不频繁的表
- 表的访问很频繁
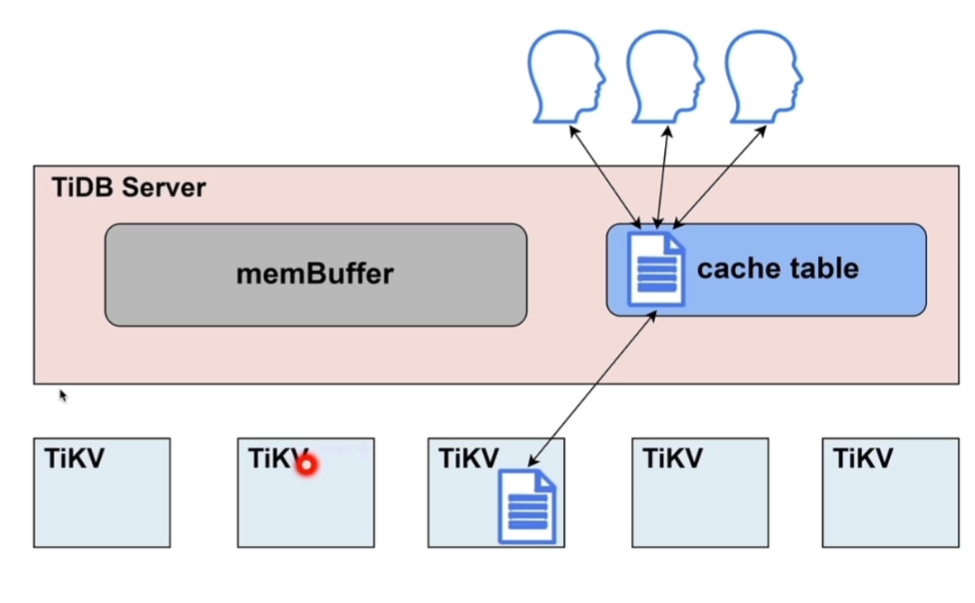
要解决数据不一致的问题。
加入缓存指令:
ALTER TABLE users CACHE;
放缓存内的表的大小只能小于64MB
**租约:tidb_table_cache_lease=5,**在租约之内,其他TiDBServer不能够写入,阻塞写,不会阻塞读,必须在租约结束。租约之外写是直接写在TiKV之内的,读取在TiKV之内读取,速度大打折扣。在租约之内TiKV会重新载入最新的数据,refresh。
应用:
- TiDB对于每张缓存表的大小限制为64MB
- 适用于查询频繁、数据量不大、极少修改的场景
- 在租约时间内,写操作会被阻塞
- 当租约到期时,读性能下降
- 不支持对缓存直接做DDL操作,需要先关闭
- 对于表加载较慢或者极少修改的表,可以适当延长租约,保持读性能稳定。
上一篇:Mac M1 安装 brew
下一篇:VScode