【Netty 从成神到升仙系列 大结局】全网一图流死磕解析 Netty 源码
- 👏作者简介:大家好,我是爱敲代码的小黄,独角兽企业的Java开发工程师,Java领域新星创作者。
- 📝个人公众号:爱敲代码的小黄
- 📕系列专栏:Java设计模式、数据结构和算法
- 📧如果文章知识点有错误的地方,请指正!和大家一起学习,一起进步👀
- 🔥如果感觉博主的文章还不错的话,请👍三连支持👍一下博主哦
- 🍂博主正在努力完成2022计划中:以梦为马,扬帆起航,2022追梦人
@[Toc]
全网一图流死磕解析 Netty 源码
通过之前介绍的几篇关于 Netty 的文章,相信大家多少对 Netty 有了一点了解,本篇文章主要从整个 Netty 的调用流程图来做一个汇总
往期文章:
- 【Netty 从成神到升仙系列 五】Netty 的责任链真有这么神奇吗?
- 【Netty 从成神到升仙系列 四】让我们一起探索 Netty 中的零拷贝
- 【Netty 从成神到升仙系列 三】Netty 凭什么成为国内最流行的网络通信框架?
- 【Netty 从成神到升仙系列 二】你真的懂 NIOEventLoop 嘛?
- 【Netty 从成神到升仙系列 一】Netty 服务端的启动源码剖析(一)
一、Netty 服务端的启动
Netty 服务端的整个启动流程,我做成了一个流程图:
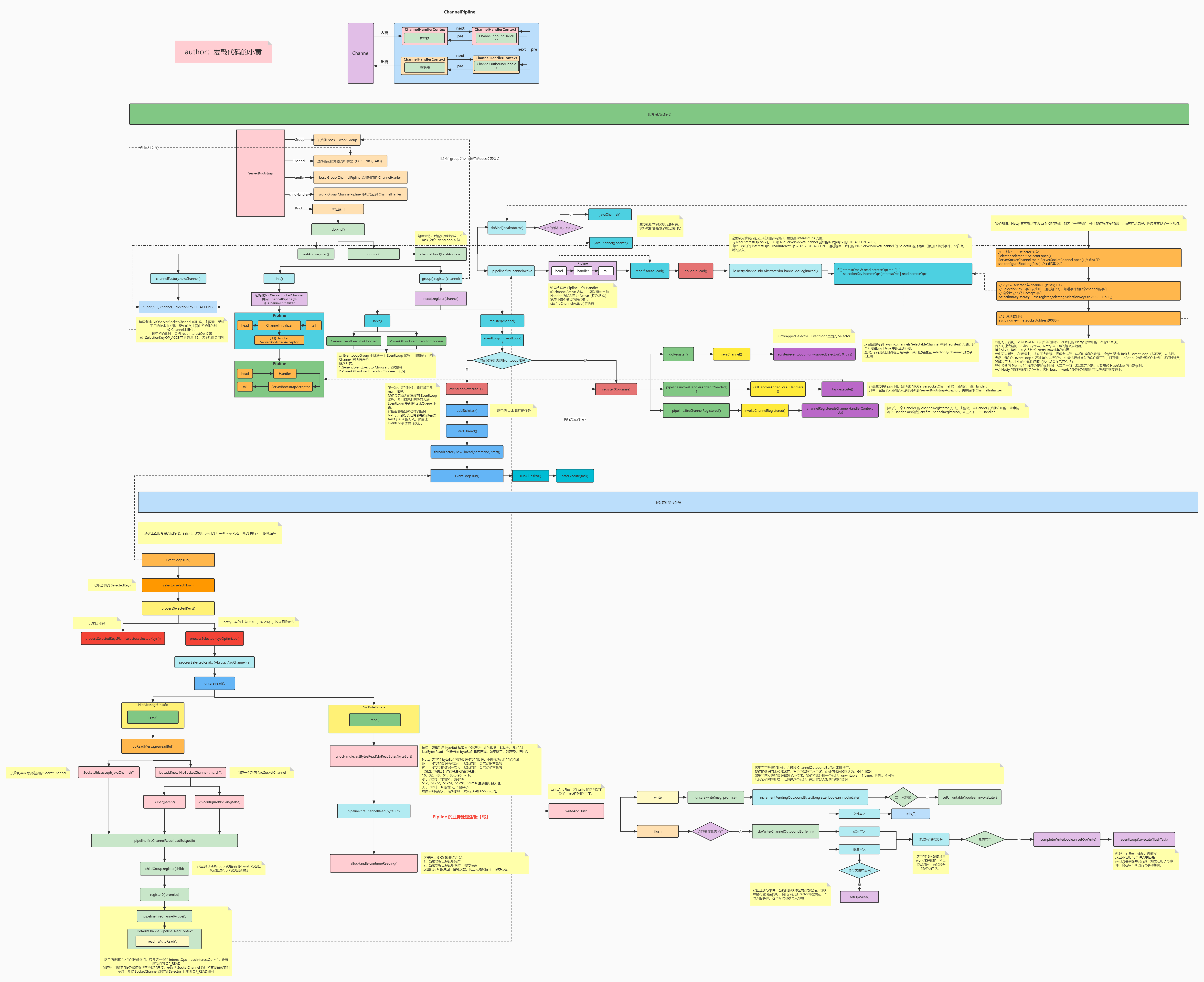
高清的可在公众号 爱敲代码的小黄 回复:Netty,即可获取
这个我们之前讲过,在 【Netty 从成神到升仙系列 一】Netty 服务端的启动源码剖析(一),当时通过源码的角度剖析了下 Netty 的启动流程。
由于当时对于 Netty 整体的把控不太好,有一些细节性的东西选择性的忽略,导致最终整体的连贯性差强人意
后来,学完 Netty 之后,又对服务端的启动做了一些细致化的分析
1. Java NIO 的启动
我们学过 Netty 的都知道,Netty 无非在 Java NIO 的基础上做了一定的优化,使得 I/O 网络的效率大大提高
但从整体来说,Netty 服务端的启动和 Java NIO 的启动基本一模一样,主要集中在以下几方面:
创建一个 selector 对象
Selector selector = Selector.open(); ServerSocketChannel ssc = ServerSocketChannel.open(); // 创建FD-1 ssc.configureBlocking(false); // 非阻塞模式建立 selector 与 channel 的联系(注册)
SelectionKey sscKey = ssc.register(selector, SelectionKey.OP_ACCEPT, null);注册端口号
ssc.bind(new InetSocketAddress(8080));
而我们 Netty 用了好多好多的代码去描述了上述几行代码。
当我看完第一遍 Netty 服务端启动流程,感觉这样写的好处在哪呢,完全没有 GET 到,当我第二遍带着疑惑去看并画清流程图之后,发现 Netty 的源码确实令人耳目一新
具体表现在哪些方面呢,我们可以继续往下看
2. Netty 服务端的启动
我们看到,最核心的当属 Pipline,这里我们也不多介绍了,之前也都讲过。
从整体来看,其实和我们写的业务代码也差不多,但博主感觉比较厉害的一点就是:对于一些我们不需要立即获取结果的处理,全部封装成 Task 交给线程处理,这样会让我们的系统线程的使用率提高并且性能提升。
在轮询处理时,也会使用 ioRatio 控制 I/O 的比例,同时依靠计数器解决了 Epoll 空轮询的BUG。
我们初始化时,分别有 BOSS 和 WORK 两个线程组,我们的 BOSS 线程组主要用来接受客户端的连接事件,而 WORK 线程组用来处理客户端的读事件。
二、Netty 服务端的读写
通过上述 Netty 服务端的启动,我们向我们的 Selector 上注册了 OP_ACCEPT 事件,当有客户端连接到服务端时,就会触发该事件。
1.注册读事件
通过上述的流程图我们可以看到,通过 Channel 的不同来实现不同的 unsafe.read() 的实现
这里 channel 不同主要指的是:NioServerSocketChannel 和 NioSocketChannel 两种
对于 NioServerSocketChannel 来说,负责接受当前客户端的 连接请求,生成 NioSocketChannel 将当前的连接注册到 Work 的线程组上(childGroup.register(child))并向 Selector 上注册 读事件(接受客户端)
2.读数据
而对于 NioSocketChannel,主要负责处理客户端的 读请求
对于读数据来说,主要通过 allocHandle.lastBytesRead(doReadBytes(byteBuf)) 进行读取
这里说下读取及扩容的逻辑:
- 服务端默认接受客户端的
byteBuf是 1024 Netty的byteBuf可以根据接受数据的大小进行动态的扩缩容(SIZE_TABLE),规律如下:- 扩容:当小于
512时,一次性增加64,当大于512时,一次性增加16倍 - 缩容:当小于
512时,一次性减少16,当大于512时,一次性减少一倍 - 当然,源码中扩缩容的前提不同:缩容需要连续两次都小于,而扩容只需要大于一次就可以
byteBuf扩容也是有范围限制的:默认在64和65536之间
- 扩容:当小于
- 什么时候停止数据的读取,主要由
allocHandle.continueReading()控制- 当前的数据已被读取完毕
- 当前的数据被读取16次,需要结束
- 这里规定读取次数的原因:控制次数,防止无限次循环,浪费线程。
3.写数据
上面在读取数据时,会调用 pipeline.fireChannelRead(byteBuf),这里会执行 Pipline 上的各个 Handler 的 channelRead方法,这里我们一般使用 writeAndFlush 和 write,我们分开来讲。
首先,对于 write 的方法,主要由 incrementPendingOutboundBytes(long size, boolean invokeLater) 执行,这里会向 ChannelOutboundBuffer 写入信息并判断当前写入的数据是否超越水位线(默认 64 * 1024)。
如果超越了我们的水位线,我们会给与 ChannelOutboundBuffer 一个标记,将 unwritable = 0(false) 修改为 unwritable = 1(true),这样在我们后续发送的过程中,可以根据此标记让应用自己选择是否发送。
这里的 ChannelOutboundBuffer 主要相当于一个容器,write 向里面写,Flush 往内核发。
4.刷数据
这里的刷数据,指的是用户空间的 Buffer 向内核空间的 Scoket 刷数据,类似:
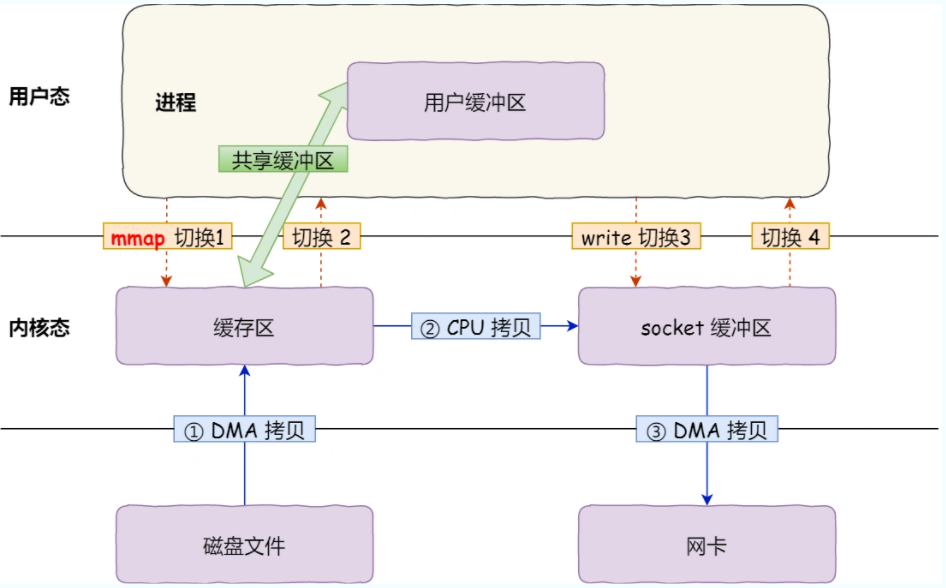
我们的数据会发送到 Socket 缓冲区,由网卡发出。
我们来讲一讲 Netty 的 Flush 流程:
- 判断当前通道是否关闭(防止当前的客户端已经断开连接)
- 刷数据
- case 0:文件数据,通过零拷贝刷,这里之前讲过,参考:【Netty 从成神到升仙系列 四】让我们一起探索 Netty 中的零拷贝
- case 1:单个数据的写入
- default:批量数据的写入:由于批量数据写入,必然存在缓冲区满的问题,当缓冲区满的时候,
Netty会注册一个写事件,当缓冲区有空闲时,触发写事件,交由其他线程处理。
- 如果写了16次数据还没有写完的话,会新起一个
flush任务,让其余的Work线程执行该任务。这里不需要写事件的原因:当前的缓存区是空闲的,如果注册了写事件,会造成不断的有写事件触发。
这里可能有小伙伴们疑惑,为什么一个写事件就能避免批量数据写入的问题,缓冲区满与空闲代表什么?
当我们的服务端收到客户端的请求时,我们会 write 和 flush,我们从整个流程看下: 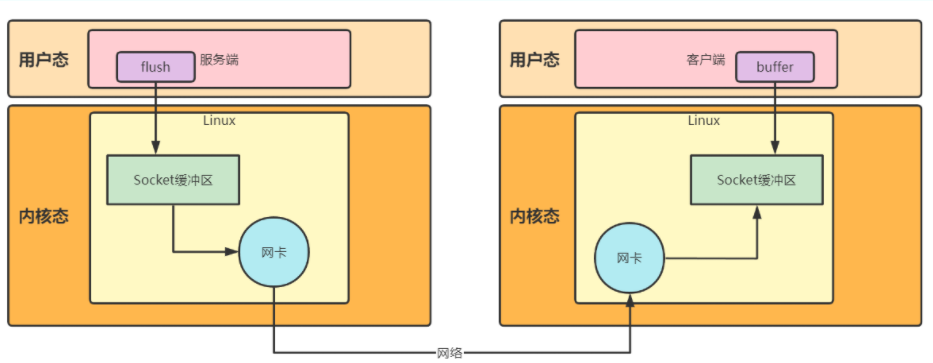
对于服务端来说,我们的 flush 操作会将处理用户态的 buffer 中的数据刷到内核态的 Scoket缓冲区 中
对于客户端来说,会通过网卡接受服务端的数据并刷新到 Scoket缓冲区 中,通过用户态的 buffer 读取
如果我们当前的服务端发送的数据过大,客户端接受的数据过少,就会导致服务端这边的 Scoket缓冲区 阻塞
- 87380 :tcp 接收缓冲区的默认值
- 16384 : tcp 发送缓冲区的默认值
这个时候,我们只能等待 Scoket缓冲区 有空闲时,继续向里面 flush,但这种无疑会把当前的线程阻塞住,违背 NIO 的架构初衷
所以,当批量的数据一次性写入不成功时,我们会向 Selector 注册一个写事件,当 Scoket缓冲区 有空闲时,会触发该事件,并交由其他的 work 线程去处理,这样极大的发挥了 Netty 高效的网络通讯框架的作用。
三、总结
自此,Netty 的章节基本就结束了~
不得不说,学习 Netty 的过程还是挺痛苦的,有一些网络层面的东西,之前都没有接触过,只能慢慢的去补
还有一些学习中的疑惑,也需要大量的时间去消化,比如:
- Netty 为什么能成为最高效的网络 I/O 框架?
- 当你刚学习时,你可能会听说
NIO使Netty变的有效起来
- 当你刚学习时,你可能会听说
- NIO 是什么?为什么会出现 NIO?
- 这个时候你会了解到,主要由于
C10K的经典问题出现,导致了NIO的出现 - NIO 实际上是 Linux 下 IO多路复用的机制,通过 select、poll、epoll三种方式来实现
- 这个时候你会了解到,主要由于
- select、poll、epoll 是什么?
- 了解到每个实现方式的不同以及慢慢的优化,最终采用的
epoll作为当前NIO的实现
- 了解到每个实现方式的不同以及慢慢的优化,最终采用的
- 网络是怎么发送的?Socket 的本质又是什么?
- Linux 网络编程又是如何实现的?
其实,慢慢的思索,好像学习一个知识,会带来一系列的蝴蝶效应,尤其是对下层知识的缺乏,导致自己上层知识的不稳定。
就像我一开始其实是分析的 kafka 的源码,到了通信那一节,看不懂了
于是去看了看 IO,继而又去看 操作系统、计算机网络等
不过用了这么多时间,还算有成效,至少 Netty 可以懂了一点了
本期的内容就到这里,后续的话,可能会出一篇 select、poll、epoll 的文章,其次,后面应该会重新回到 kafka 的源码解析来
我是一名独角兽企业的Java开发工程师,希望可以点个关注呀,有问题可以留言或者私信,我们下期再见!
本文由博客一文多发平台 OpenWrite 发布!
上一篇:超级简单的机器学习入门
下一篇:嵌入式分享合集94