超级简单的机器学习入门
超级简单的机器学习入门
文章目录
- 超级简单的机器学习入门
- 0.写在前面
- 1.机器学习基本概念
- 2.机器学习算法的类型
- 2.1 监督学习
- 2.2 无监督学习
- 2.3 监督学习和无监督学习的对比
- 2.4 强化学习
- 3.机器学习的三个基本要素
- 3.1 模型
- 3.2 学习准则
- 3.2.1 损失函数
- 3.2.2 欠拟合和过拟合(包含正则化)
- 3.3 优化方法
- 3.3.1 梯度下降法(重要!)
- 3.3.2 数据预处理
- 3.3.3 提前停止
- 3.3.4 超参数优化
- 4.线性模型
- 4.1 感知器
- 4.2 Logistic回归
- 4.3 Softmax回归
- 4.4 支持向量机
- 4.4.1 参数学习
- 4.4.2 核函数
- 4.4.3 软间隔
- 4.5 损失函数对比
- 5. 写在最后
0.写在前面
本文大多数内容来自《神经网络与深度学习》(邱锡鹏,神经网络与深度学习,机械工业出版社,https://nndl.github.io/, 2020.)周志华-机器学习,也参考了很多其他笔记博客。仅作为学习记录。
1.机器学习基本概念
① 机器学习是什么?
机器学习就是让计算机从数据中进行自动学习,得到某种知识或规律。
② 样本和数据集
我们可以将一个标记好特征以及标签看作一个样本。
一组样本构成的集合称为数据集。一般将数据集分为两部分:训练集和测试集。
训练集中的样本是用来训练模型的,而测试集中的样本是用来检验模型好坏的。
③ 学习与训练
我们通常用一个𝐷 维向量𝒙=[𝑥1,𝑥2,⋯,𝑥𝐷]T𝒙 = [𝑥_1 , 𝑥_2 , ⋯ , 𝑥_𝐷] ^Tx=[x1,x2,⋯,xD]T 表示所有特征构成的向量,称为特征向量,其中每一维表示一个特征。
假设训练集 𝒟 由 𝑁 个样本组成,其中每个样本都是独立同分布的,计为:𝒟=(𝒙(1),𝑦(1)),(𝒙(2),𝑦(2)),⋯,(𝒙(𝑁),𝑦(𝑁)).𝒟 = {(𝒙^{(1)}, 𝑦^{(1)}), (𝒙^{(2)}, 𝑦^{(2)}), ⋯ , (𝒙^{(𝑁)}, 𝑦^{(𝑁)})}. D=(x(1),y(1)),(x(2),y(2)),⋯,(x(N),y(N)).
我们希望让计算机从一个函数集合F=𝑓1(𝒙),𝑓2(𝒙),⋯ℱ = {𝑓_1 (𝒙), 𝑓_2 (𝒙), ⋯}F=f1(x),f2(x),⋯ 中自动寻找一个“最优”的函数𝑓∗(𝒙) 来近似每个样本的特征向量 𝒙 和标签 𝑦 之间的真实映射关系,找到这个最优函数的过程就叫做学习或训练。
以下给出一个学习的基本流程:
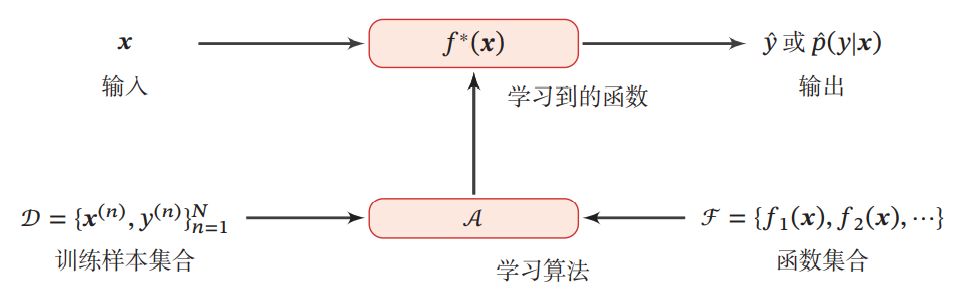
通过训练集,不断识别特征,不断建模,最后形成有效的模型,这个过程就叫“机器学习”!
2.机器学习算法的类型
2.1 监督学习
如果机器学习的目标是建模样本的特征 𝒙 和标签 𝑦 之间的关系,并且训练集中每个样本都有标签,那么这类机器学习称为监督学习。
根据标签类型的不同,监督学习又可以分为回归问题、分类问题和结构化学习问题。
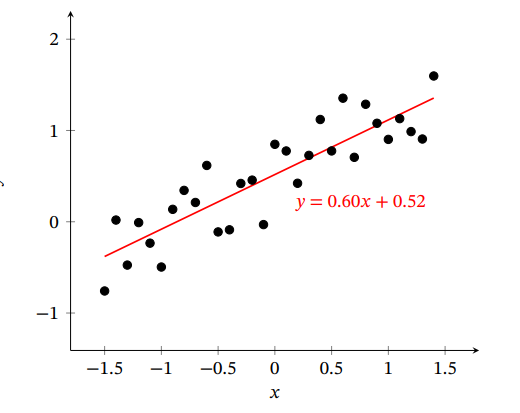
(1) 回归问题中的标签 𝑦 是连续值, 𝑓(𝒙; 𝜃)的输出也是连续值。比如未来几年预测房屋价格的走势,价格是一个连续的值。最后会按照顺序把输出值串接起来,构成一个曲线。
一元线性回归
一元线性回归是最简单,最基础的一种模型,是探究两个变量之间关系的一种统计分析方法。其模型为为:
y=ax+by=ax+by=ax+b其中xxx为自变量,yyy为因变量,aaa和bbb为回归系数
求解方法为最小二乘法
{a=∑i=1n(xi−xˉ)(yi−yˉ)∑i=1n(xi−xˉ)2b=yˉ−axˉ\left\{\begin{array}{l} a=\frac{\sum_{i=1}^{n}\left(x_{i}-\bar{x}\right)\left(y_{i}-\bar{y}\right)}{\sum_{i=1}^{n}\left(x_{i}-\bar{x}\right)^{2}} \\ b=\bar{y}-a \bar{x} \end{array}\right. {a=∑i=1n(xi−xˉ)2∑i=1n(xi−xˉ)(yi−yˉ)b=yˉ−axˉ
多元线性回归
探究一个因变量和多个自变量之间关系的一种统计分析方法,其模型为:
y=alx1+a2x2+…+anxn+by=a_{l} x_{1}+a_{2} x_{2}+\ldots+a_{n} x_{n}+by=alx1+a2x2+…+anxn+b其中yyy为因变量,x1,x2,…,xn为自变量{x_1,x_2,…,x_n为自变量}x1,x2,…,xn为自变量,a1,a2,a3…,an,ba_1,a_2,a_3…,a_n,ba1,a2,a3…,an,b 为回归系数
求解方法类似一元线性回归,使用最小二乘法
利用线性代数的形式,对多元线性回归的误差公式求导为:
∂R(w)∂w=12∂∥y−X⊤w∥2∂w=−X(y−X⊤w)\begin{aligned} \frac{\partial \mathcal{R}(\boldsymbol{w})}{\partial \boldsymbol{w}} &=\frac{1}{2} \frac{\partial\left\|\boldsymbol{y}-\boldsymbol{X}^{\top} \boldsymbol{w}\right\|^{2}}{\partial \boldsymbol{w}} \\ &=-\boldsymbol{X}\left(\boldsymbol{y}-\boldsymbol{X}^{\top} \boldsymbol{w}\right) \end{aligned} ∂w∂R(w)=21∂w∂∥∥y−X⊤w∥∥2=−X(y−X⊤w)令 ∂∂wR(w)=0\frac{\partial}{\partial \boldsymbol{w}} \mathcal{R}(\boldsymbol{w})=0∂w∂R(w)=0 , 得到最优的参数 w∗\boldsymbol{w}^{*}w∗ 为:w∗=(XX⊤)−1Xy\boldsymbol{w}^{*}=\left(\boldsymbol{X} \boldsymbol{X}^{\top}\right)^{-1} \boldsymbol{X} \boldsymbol{y}w∗=(XX⊤)−1Xy
用最小二乘法来进行线性回归参数学习的图示
核心代码from sklearn.linear_model import LinearRegression #调用最小二乘法函数求回归系数 model=LinearRegression() model.fit(x_train,y_train) # 显示斜率 a = model.coef_[0] # 显示截距 b = model.intercept_ # 预测结果 predict = model.predict(x_test)
(2)分类问题中的标签 𝑦 是离散的类别。在分类问题中,学习到的模型也称为分类器。分类问题根据其类别数量又可分为二分类多分类问题。上面提到的猫狗识别例子就是一个二分类的问题,因为它输出的结果不是猫就是狗。
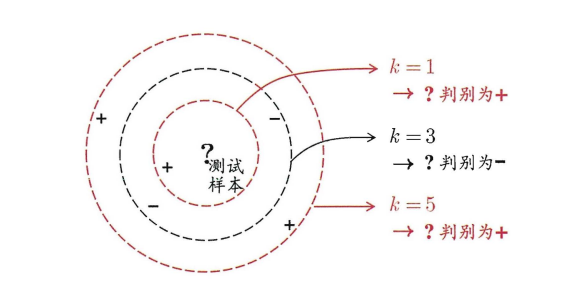
其中分类问题中最常用的算法就是KNN ,(k近邻算法)
KNN
KNN的原理就是当预测一个新的值x的时候,选择它距离最近的k个点,这k个点中属于哪个类别的点最多,x就属于哪个类别
其中K的选择很重要!!!,如图所示,不同的K计算出的结果是不一样的!!
KNN核心代码from sklearn import preprocessing from sklearn import neighbors #数据标准化 scaler = preprocessing.StandardScaler().fit(X_train) X_train = scaler.transform(X_train) X_test = scaler.transform(X_test) 模型计算 # 调用KNN算法包训练模型 knn = neighbors.KNeighborsClassifier(n_neighbors=5) knn.fit(X_train,y_train) # 检验模型 y_pred = knn.predict(X_test)
(3)结构化学习是一种特殊的分类问题。我们之前学习到的学习模型的输入与输出一直以来都是向量,但是在实际问题中,我们的输入输出可能是别的结构。比如,我们可能会需要输入输出是序列、列表或者树。它的输出空间比较大,通常用动态规划的方式解决。(在入门阶段简单了解概念就好)
2.2 无监督学习
无监督学习是指从不包含目标标签的训练样本中自动学习到一些有价值的信息。
- 典型的无监督学习问题有
聚类、密度估计、特征学习、降维等,其中聚类和降维比较常用。
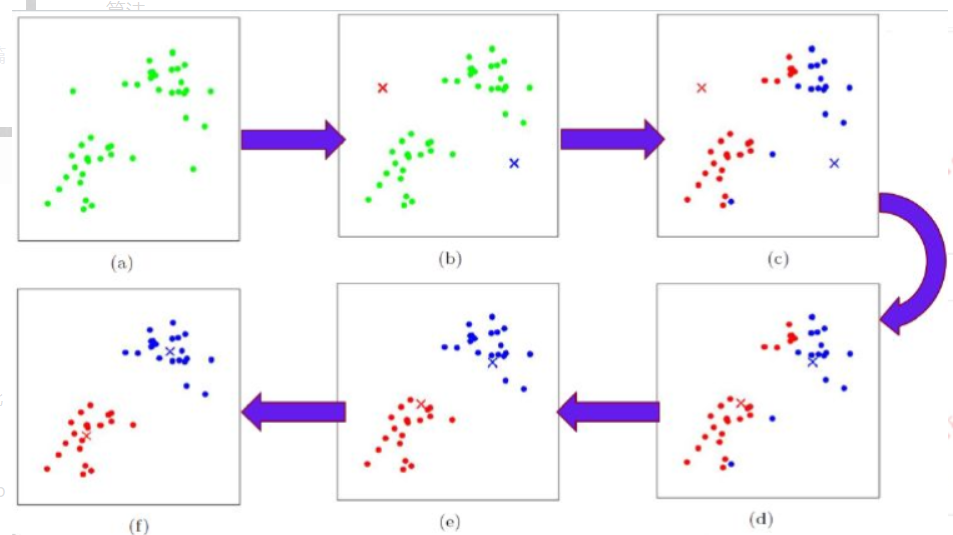
(1)聚类就是按照某个特定标准把一个数据集分割成不同的类或簇。最经典的就是k-means算法聚类,它的流程为:
- 随机地选择k个点,每个点代表一个簇的中心;
- 将其他所有对象根据其与各簇中心的距离,将它赋给最近的簇;
- 重新计算每个簇的平均值,更新为新的簇中心;
- 不断重复2、3,直到准则函数收敛。
以下这个图很好地表示了k-means聚类的过程:
k-means核心代码from sklearn import preprocessing from sklearn.cluster import KMeans # 将属性缩放到一个指定范围,即(x-min)/(max-min) scaler = preprocessing.MinMaxScaler().fit(X_train) X_train = scaler.transform(X_train) 模型计算 # 调用k-means算法包训练模型 model_km = KMeans(n_clusters=3)#指定分类 model_km.fit(X_train) label_pred = model_km.labels_ #获取聚类标签 centroids = model_km.cluster_centers_ #获取聚类中心
(2) 降维一种能在减少数据集中特征数量的同时,避免丢失太多信息并保持/改进模型性能的方法, 其中最常用的一种算法就是PCA, 也称主成分分析法.
PCA
PCA的主要思想是降维,把多指标转化为少数几个综合指标.
我们从几何角度来理解一下降维
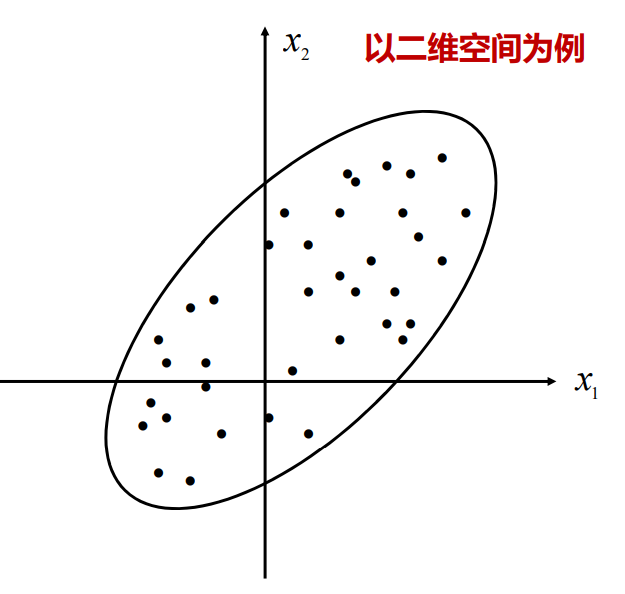
以二维空间为例,有这样一些点分布在直角坐标系中,我们观察可以发现,无论是丢弃x1x_1x1选择x2x_2x2, 还是丢弃x2x_2x2选择x1x_1x1都不能很好地体现这些点的特征.
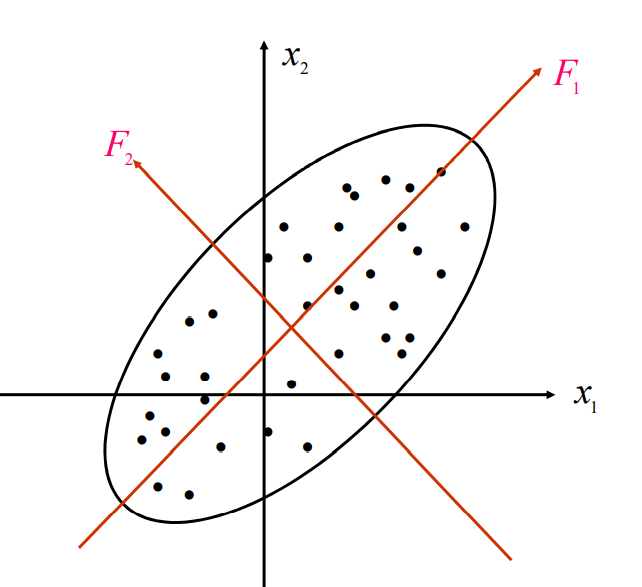
但是,如果我们将x1x_1x1轴和x2x_2x2轴平移和旋转一下, 变成F1F_1F1轴和F2F_2F2轴
{F1=x1cosθ+x2sinθF2=−x1sinθ+x2cosθ\left\{\begin{array}{l} F_{1}=x_{1} \cos \theta+x_{2} \sin \theta \\ F_{2}=-x_{1} \sin \theta+x_{2} \cos \theta \end{array}\right. {F1=x1cosθ+x2sinθF2=−x1sinθ+x2cosθ
观察可以发现, 旋转变换后n个样品点在F1F_1F1轴方向上的离散程度最大, 变量F1F_1F1代表了原始数据的绝大部分信息,在研究某些问题时,即使不考虑变量F2F_2F2也无损大局。
我们将其推广到更高的维度上, 有:
[F1=u11X1+u21X2+⋯+up1XpF2=u12X1+u22X2+⋯+up2Xp⋯⋯Fp=u1pX1+u2pX2+⋯+uppXp\left[\begin{array}{rl} F_{1}= & u_{11} X_{1}+u_{21} X_{2}+\cdots+u_{p 1} X_{p} \\ F_{2}= & u_{12} X_{1}+u_{22} X_{2}+\cdots+u_{p 2} X_{p} \\ & \cdots \cdots \\ F_{p}= & u_{1 p} X_{1}+u_{2 p} X_{2}+\cdots+u_{p p} X_{p} \end{array}\right. ⎣⎡F1=F2=Fp=u11X1+u21X2+⋯+up1Xpu12X1+u22X2+⋯+up2Xp⋯⋯u1pX1+u2pX2+⋯+uppXp其中F1F_1F1被成为第一主成分,F2F_2F2被称为第二主成分, 我们通常选择前k个主成分, 一般保留的信息大于85%.
PCA核心代码from sklearn.preprocessing import MinMaxScaler from sklearn.decomposition import PCA #将属性缩放到一个指定范围,即(x-min)/(max-min) scaler = MinMaxScaler() scale_data = pd.DataFrame(scaler.fit_transform(datanew)) # PCA降维' #选择保留85%以上的信息时,自动保留主成分 pca = PCA(0.85) data_pca = pca.fit_transform(scale_data) #data_pca就是降维后的数据
2.3 监督学习和无监督学习的对比
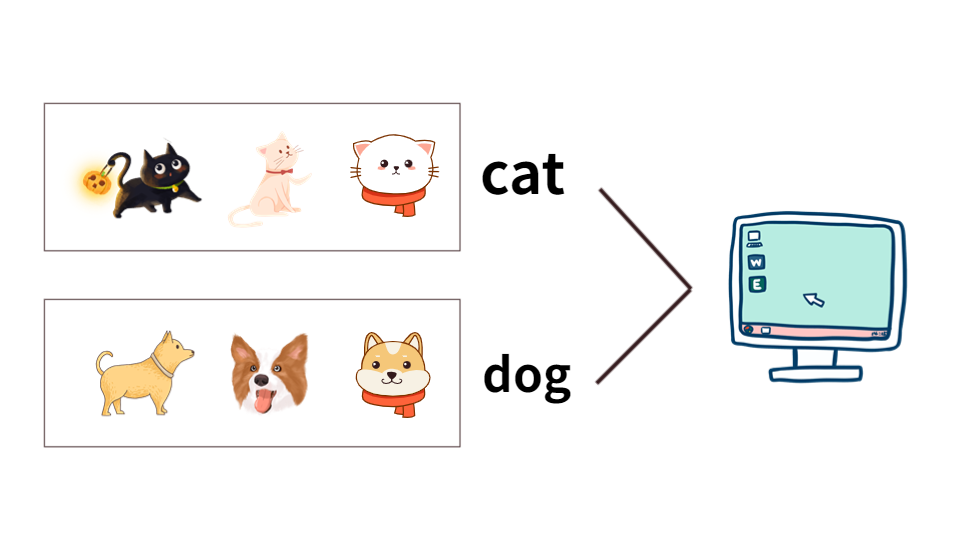
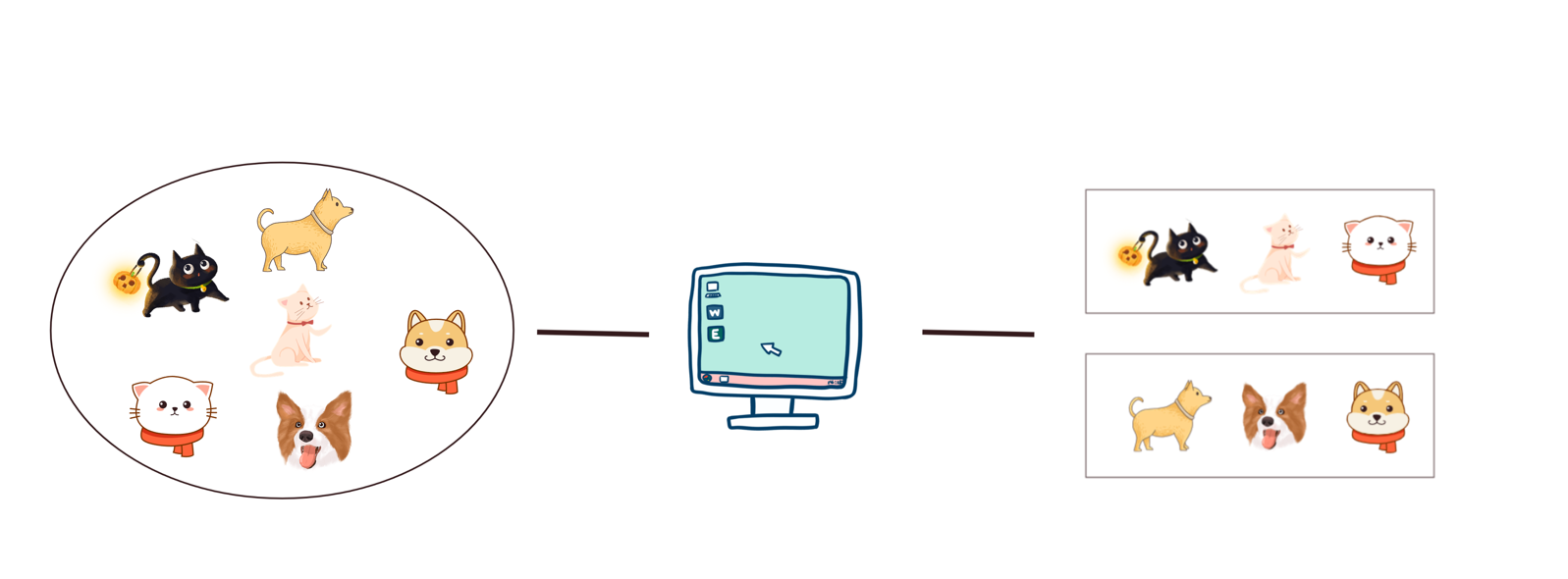
举个监督学习的栗子:
我们把一大堆的猫和狗的照片给机器,让机器识别出哪些是猫哪些是狗。当我们使用监督学习的时候,需要给这些照片打上
标签。
我们给照片打的标签就是“正确答案”,机器通过大量学习,就可以学会在新照片中认出猫和狗。
举个无监督学习的栗子:
我们还是一堆猫和狗的照片给机器,不给这些照片打任何标签,但是我们希望机器能够将这些照片分分类。
通过学习,机器会把这些照片分为2类,一类都是猫的照片,一类都是狗的照片。虽然跟上面的监督学习看上去结果差不多,但是有着本质的差别:
非监督学习中,虽然照片分为了猫和狗,但是机器并不知道哪个是猫,哪个是狗。对于机器来说,相当于分成了 A、B 两类。
- 监督学习是一种目的明确的训练方式,你知道得到的是什么;而无监督学习则是没有明确目的的训练方式,你无法提前知道结果是什么。
- 监督学习需要给数据打标签;而无监督学习不需要给数据打标签。一般而言, 监督学习通常需要大量的有标签数据集,这些数据集一般都需要由人工进行标 注,成本很高。
- 监督学习由于目标明确,所以可以衡量效果;而无监督学习几乎无法量化效果如何。
2.4 强化学习
强化学习是一类通过交互来学习的。它有两个重要的特征:反复实验和延迟奖励。
比如说:你想让小健同学好好学习算法。在这个过程中,要经历很多东西,比如看视频学习,刷题,打练习赛等等,要经过一段时间的ACM正式比赛才能知道小健同学的成果好不好。若正式比赛好成绩作为小健同学学习算法的奖励,这个不是一蹴而成的,需要正式比赛后才能给出反馈这个执行的过程对不对。因此,小健同学要根据比赛的结果多次摸索练习才能获得最优的学习方法。
3.机器学习的三个基本要素
机器学习方法可以粗略地分为三个基本要素:模型、学习准则、优化算法.
3.1 模型
对于一个机器学习任务,首先要确定其输入空间𝒳 和输出空间𝒴.不同机器
学习任务的主要区别在于输出空间不同.在二分类问题中𝒴 = {+1, −1},在𝐶分类问题中𝒴 = {1, 2, ⋯ , 𝐶},而在回归问题中𝒴 = ℝ.
我们假设有一个“最优”的函数
𝑓∗(𝒙)可以描述输入空间𝒳和输出空间𝒴的真实映射关系,在一个我们假设的参数化的函数族ℱ = {𝑓(𝒙; 𝜃)|𝜃 ∈ ℝ𝐷}中取得。其中𝑓(𝒙; 𝜃)是参数为𝜃 的函数,也称为模型,𝐷 为参数的数量。
其中模型大致可以分为线性模型和非线性模型
3.2 学习准则
一个好的模型 𝑓(𝒙, 𝜃∗) 应该在所有 (𝒙, 𝑦) 的可能取值上都与真实映射函数𝑦 = 𝑔(𝒙)一致,即|𝑓(𝒙, 𝜃∗ ) − 𝑦| < 𝜖, ∀(𝒙, 𝑦) ∈ 𝒳 × 𝒴,
这时候,我们还要引入一个很重要的概念:损失函数
3.2.1 损失函数
损失函数是一个非负实数函数,用来量化模型预测和真实标签之间的差异。下面介绍几种常用的损失函数。
0-1 损失函数
最直观的损失函数是表现模型在训练集上的错误率,即0-1 损失函数:
当预测值和真实值相等时,结果为0,否则为1
L(y,f(x;θ))={0if y=f(x;θ)1if y≠f(x;θ)\begin{aligned} \mathcal{L}(y, f(\boldsymbol{x} ; \theta)) &=\left\{\begin{array}{cc} 0 & \text { if } y=f(\boldsymbol{x} ; \theta) \\ 1 & \text { if } y \neq f(\boldsymbol{x} ; \theta) \end{array}\right.\\ \end{aligned} L(y,f(x;θ))={01 if y=f(x;θ) if y=f(x;θ)
优点: 能够客观地评价模型的好坏
缺点: 不连续且导数为0,难以优化
平方损失函数
平方损失函数经常用在预测标签𝑦为实数值的任务中,定义为
L(y,f(x;θ))=12(y−f(x;θ))2\mathcal{L}(y, f(\boldsymbol{x} ; \theta))=\frac{1}{2}(y-f(\boldsymbol{x} ; \theta))^{2}L(y,f(x;θ))=21(y−f(x;θ))2
平方损失函数一般不适用于分类问题.
交叉熵损失函数
对于两个概率分布,一般可以用
交叉熵来衡量它们的差异.
𝒚和模型预测分布𝑓(𝒙; 𝜃)之间的交叉熵为
L(y,f(x;θ))=−y⊤logf(x;θ)=−∑c=1Cyclogfc(x;θ)\begin{aligned} \mathcal{L}(\boldsymbol{y}, f(\boldsymbol{x} ; \theta)) &=-\boldsymbol{y}^{\top} \log f(\boldsymbol{x} ; \theta) \\ &=-\sum_{c=1}^{C} y_{c} \log f_{c}(\boldsymbol{x} ; \theta) \end{aligned} L(y,f(x;θ))=−y⊤logf(x;θ)=−c=1∑Cyclogfc(x;θ)
比如对于三分类问题,一个样本的标签向量为𝒚=[0,0,1]T𝒚 = [0, 0, 1]^Ty=[0,0,1]T,
模型预测的标签分布为 f(x;θ)=[0.3,0.3,0.4]⊤f(\boldsymbol{x} ; \theta)=[0.3,0.3,0.4]^{\top}f(x;θ)=[0.3,0.3,0.4]⊤,
则它们的交叉熵为−(0×log(0.3)+0×log(0.3)+1×log(0.4))=−log(0.4)−(0 × log(0.3) + 0 ×log(0.3) + 1 × log(0.4)) = − log(0.4)−(0×log(0.3)+0×log(0.3)+1×log(0.4))=−log(0.4)
Hinge 损失函数
对于二分类问题,假设 𝑦 的取值为 {−1, +1},𝑓(𝒙; 𝜃) ∈ ℝ.
Hinge损失函数为
L(y,f(x;θ))=max(0,1−yf(x;θ))\mathcal{L}(y, f(\boldsymbol{x} ; \theta))=\max (0,1-y f(\boldsymbol{x} ; \theta))L(y,f(x;θ))=max(0,1−yf(x;θ))
3.2.2 欠拟合和过拟合(包含正则化)
欠拟合:泛化能力差,训练样本集准确率低,测试样本集准确率低。
过拟合:泛化能力差,训练样本集准确率高,测试样本集准确率低。
合适的拟合程度:泛化能力强,训练样本集准确率高,测试样本集准确率高
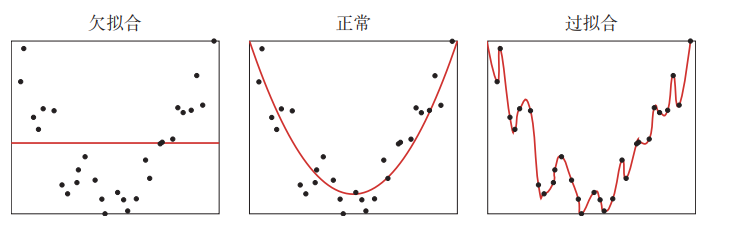
欠拟合问题往往是由于模型复杂度过低,特征量过少造成的,可以采用提高样本数量和提高模型复杂度等方法解决。
过拟合问题往往是由于训练数据少和噪声以及模型能力强等原因造成的.为了解决过拟合问题,一般会引入参数的正则化。
这时候我们又要引入一个很常见的概念了,什么是正则化?
我们引入一条公式来举例子
hw(x)=w0+w1x1+w2x22+w3x33+w4x44h_{w}(x)=w_{0}+w_{1} x_{1}+w_{2} x_{2}^{2}+w_{3} x_{3}^{3}+w_{4} x_{4}^{4}hw(x)=w0+w1x1+w2x22+w3x33+w4x44
我们可以看到,这条公式中的参数太多了,这就会导致如上图三出现的那种弯弯曲曲的情况
其实,像上图二,用公式hw(x)=w0+w1x1+w2x22h_{w}(x)=w_{0}+w_{1} x_{1}+w_{2} x_{2}^{2}hw(x)=w0+w1x1+w2x22就能很好地拟合了
当然也可以写成hw(x)=w0+w1x1+w2x22+0x33+0x44h_{w}(x)=w_{0}+w_{1} x_{1}+w_{2} x_{2}^{2}+0x_{3}^{3}+0 x_{4}^{4}hw(x)=w0+w1x1+w2x22+0x33+0x44
这时候正则化就能派上用场了
假设我们的预测值yprei=wixiy_{pre_i}=w_{i} x_{i}yprei=wixi
再假设我们本来求误差的方式是这样的:
J(x)=∑i=1N(wixi−yi)2.J(x)= \sum_{i=1}^{N}\left(w_{i} x_{i}-y_{i}\right)^{2}.J(x)=∑i=1N(wixi−yi)2.
我们当然想要求得一个minJ(x)minJ(x)minJ(x)
下面我们就要利用正则化改进这个误差公式,对这些参数进行约束了,也就是一种对参数的惩罚
正则化又很多种,常见的有l1l_1l1正则和l2l_2l2正则
以下是l1l_1l1正则,以l1l_1l1范数为约束
{min∑i=1N(wixi−yi)2∣w1∣+∣w2∣+…∣wN∣⩽m\left\{\begin{array}{l} \min \sum_{i=1}^{N}\left(w_{i} x_{i}-y_{i}\right)^{2} \\ \left|w_{1}\right|+\left|w_{2}\right|+… \left|w_{N}\right|\leqslant m \end{array}\right. {min∑i=1N(wixi−yi)2∣w1∣+∣w2∣+…∣wN∣⩽m
假设我们现在只有w1w_1w1和w2w_2w2两个系数,画成图是酱紫的以下是l2l_2l2正则,以l2l_2l2范数为约束
{min∑i=1N(wixi−yi)2w12+w22+…wN2⩽m\left\{\begin{array}{l} \min \sum_{i=1}^{N}\left(w_{i} x_{i}-y_{i}\right)^{2} \\ w_{1}^2+w_{2}^2+…w_{N}^2\leqslant m \end{array}\right. {min∑i=1N(wixi−yi)2w12+w22+…wN2⩽m
假设我们现在只有w1w_1w1和w2w_2w2两个系数,画成图是酱紫的
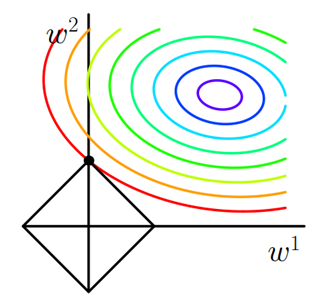
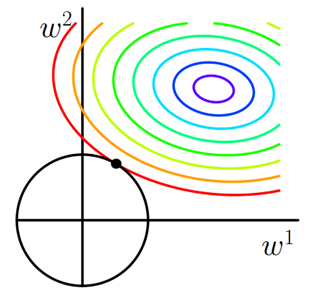
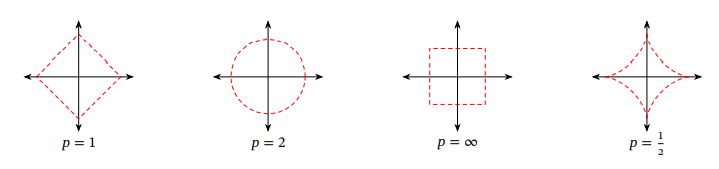
聪明的你应该能看出来l1l_1l1和l2l_2l2正则的区别叭!!!
当然,它们的共同点,也是最重要的点,就是在第二个不等式把参数限制在了一定的范围内啦,这样就可以防止一些参数过多过大了
在上图中的几何意义就是,在取一个点在左下角黑框图形的范围内(包括边界),使它和右上角图形的中心的距离最小,那么这个点一定在两个图形相切的地方取到!!!也就是彩色等值线与黑色图形首次相交的地方!!!
这时候我们引入一个系数λ\lambdaλ表示左下角黑框图形的大小,这个λ\lambdaλ的取值完全由我们来决定(λ≥0\lambda \ge 0λ≥0)。
λ越小,L图形越大,参数可以取得的范围就越广;λ 越大,图形就越小,参数取得的范围就越小。
因此,在有约束条件的情况下:
l1l_1l1正则化等价于求∑i=1N(wixi−yi)2+λ((∣w1∣+∣w2∣+…∣wN∣)−m)\sum_{i=1}^{N}\left(w_{i} x_{i}-y_{i}\right)^{2}+\lambda((\left|w_{1}\right|+\left|w_{2}\right|+… \left|w_{N}\right|)-m)∑i=1N(wixi−yi)2+λ((∣w1∣+∣w2∣+…∣wN∣)−m)导数为0的点
l2l_2l2正则化等价于求∑i=1N(wixi−yi)2+λ((w12+w22+…wN2)−m)\sum_{i=1}^{N}\left(w_{i} x_{i}-y_{i}\right)^{2}+\lambda((w_{1}^2+w_{2}^2+…w_{N}^2)-m)∑i=1N(wixi−yi)2+λ((w12+w22+…wN2)−m)导数为0的点
为啥可以这么等价呢???
设式子的第一个部分为f(x)f(x)f(x),式子的第二个部分为λg(x)\lambda g(x)λg(x),整个式子导数为0的点是∇f(x)+λ∇g(x)=0\nabla f(x) + \lambda \nabla g(x) = 0∇f(x)+λ∇g(x)=0 的点,也就是两个式子导数互为相反数的点。在满足这个条件下,这个点就位于两个图形相切的地方。这是几何上的直观证明,数学公式证明我们后面再来和大家详细说说。
那么l1l_1l1正则化和l2l_2l2正则化有什么区别呢??
l1l_1l1函数更利于稀疏化(更多的参数取得0值),l2l_2l2函数处处可导,更易计算。
为什么l1l_1l1函数更利于稀疏化呢??比较直观一点理解,因为l1l_1l1函数有很多突出的角(二维情况下四个,多维情况下更多),误差函数与这些角接触的机率会远大于与L其它部位接触的机率,而在这些角上,会有很多权值等于0(比如图中的w1w_1w1等于0),这就是为什么L1正则化可以产生稀疏模型,进而可以用于特征选择。
下面再来看给大家看看不同范数的图示叭
3.3 优化方法
如何找到最优的模型𝑓(𝒙, 𝜃∗) 就成了一个最优化问题.机器学习的训练过程其实就是最优化问题的求解过程.
3.3.1 梯度下降法(重要!)
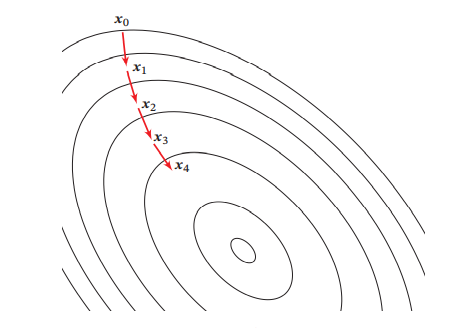
在机器学习中,最简单、常用的优化算法就是梯度下降法,我们可以不断往负梯度的方向搜索(也就是导数或者偏导数的相反方向),直到达到最低点。
梯度下降可以理解为你站在山的某处,想要下山,此时最快的下山方式就是你环顾四周,哪里最陡峭,朝哪里下山,一直执行这个策略,在第N个循环后,你就到达了山的最低处。
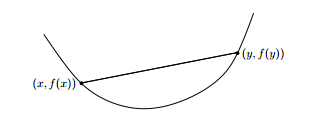
可以看出梯度下降有时得到的是局部最优解,如果损失函数是凸函数,梯度下降法得到的解就是全局最优解。
凸函数只有一个最低点,也就是极值点就是最值点,任意两点的连线必然在函数的上方,而非凸函数有多个极值点。
在二维中表示梯度下降的流程是这样子的:
在三维中表示梯度下降的流程是这样子的:
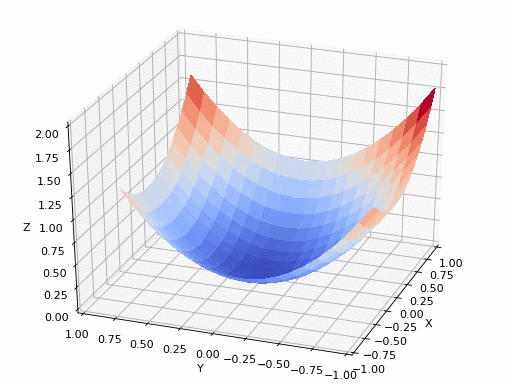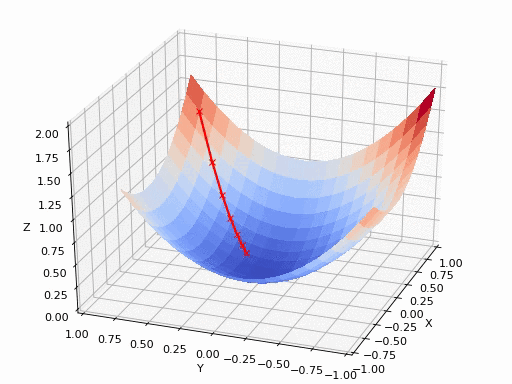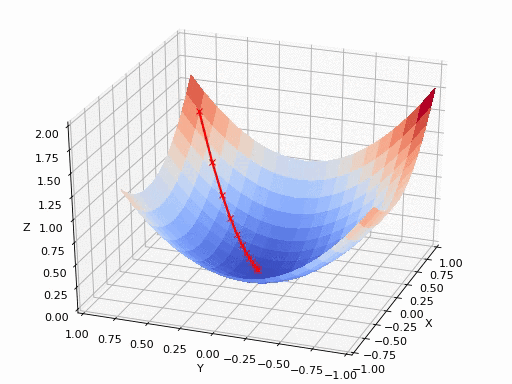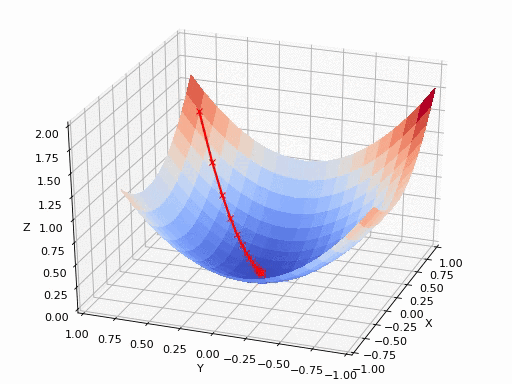
比如下面这幅图非凸函数可能找到的就是局部最优解,而不是全局最优解。
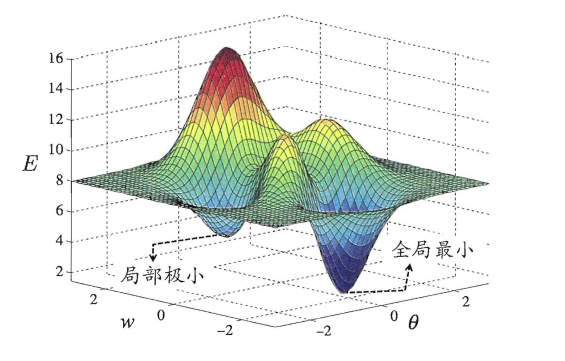
在高维空间中,非凸优化的难点并不在于如何逃离局部最优点,而是如何逃离鞍点,鞍点的梯度是0,但是在一些维度上是最高点,在另一些维度上是最低点,如图所示:
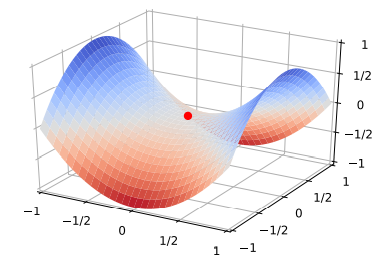
解决这个的方法通常为通过在梯度方向上引入随机性
但幸好,我们上面提到的平方损失函数就是凸函数,可以找到全局最优解。
损失函数的迭代公式为
Θ1=Θ0−α∇J(Θ)\Theta^{1}=\Theta^{0}-\alpha \nabla J(\Theta)Θ1=Θ0−α∇J(Θ)
其中Θt\Theta^{t}Θt 为第 𝑡 次迭代时的参数值,𝛼为搜索步长.在机器学习中,𝛼一般称为学习率。
这个学习率的大小是很有讲究的,如果学习率太小,要很慢才能到达最低点;如果学习率太大,很容易错过最低点。
以下这幅图展现了不同学习率的情况。
所以,选择一个合适的学习率是很重要的!!!‘
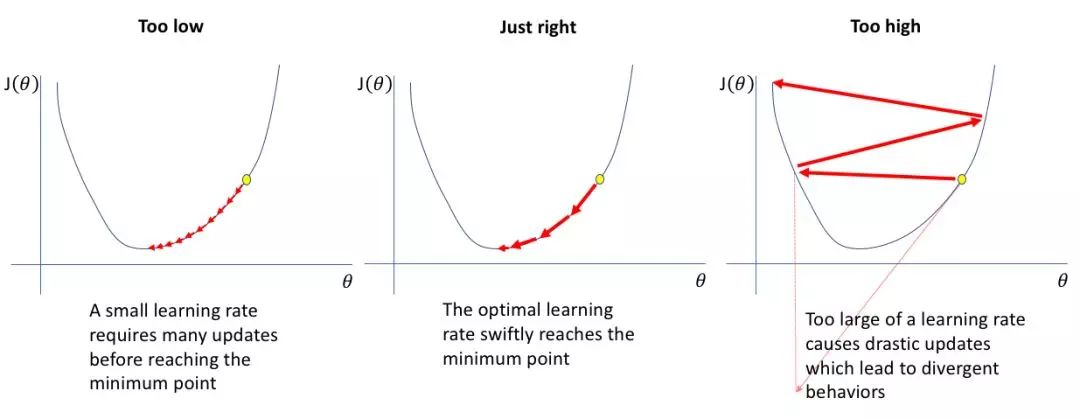
通常,这个学习率是不断调整的,学习率在一开始要保持大些来保证收敛速度,在收敛到最优点附近时要小些以避免来回振荡。
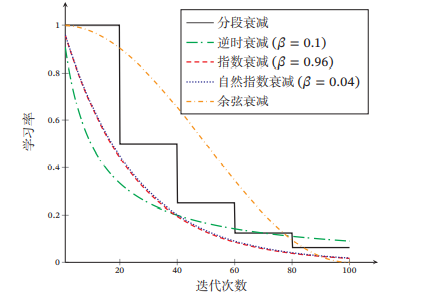
常见的学习率衰减的方法有:分段常数衰减,逆时衰减,指数衰减,自然指数衰减,余弦衰减
① 分段常数衰减:通俗易懂地理解为阶梯衰减,即每经过 𝑇1,𝑇2,⋯,𝑇𝑚𝑇_1, 𝑇_2, ⋯ , 𝑇_𝑚T1,T2,⋯,Tm 次迭代将学习率衰减为原来的 β1,β2,⋯,β𝑚\beta_1, \beta_2, ⋯ , \beta_𝑚β1,β2,⋯,βm 倍,其中 𝑇𝑚𝑇_𝑚Tm 和 β𝑚<1\beta_𝑚 < 1βm<1 为根据经验设置的超参数.
② 逆时衰减
αt=α011+β×t, \alpha_{t}=\alpha_{0} \frac{1}{1+\beta \times t} \text {, } αt=α01+β×t1, 其中𝛽为衰减率
③ 指数衰减:
αt=α0βt,\alpha_{t}=\alpha_{0} \beta^{t}, αt=α0βt,其中𝛽 < 1为衰减率.
④ 自然指数衰减:
αt=α0e(−β×t)\alpha_{t}=\alpha_{0} e^ {(-\beta \times t)} αt=α0e(−β×t)其中𝛽 为衰减率.
⑤ 余弦衰减:
αt=12α0(1+cos(tπT)),\alpha_{t}=\frac{1}{2} \alpha_{0}\left(1+\cos \left(\frac{t \pi}{T}\right)\right), αt=21α0(1+cos(Ttπ)),其中𝑇为总的迭代次数
说了这么多学习率衰减的方法,是不是有点头晕呢?那我们来看看不同学习率衰减的图示叭!(假设学习率初始为1)
其实呢,
学习率衰减只是调整学习率中比较常见简单的一种方法,其它调整学习率的方法还有:学习率预热,周期性学习率调整,自适应学习率,等,这里就不一一介绍辽,给大家看看一些常见的优化方法叭:
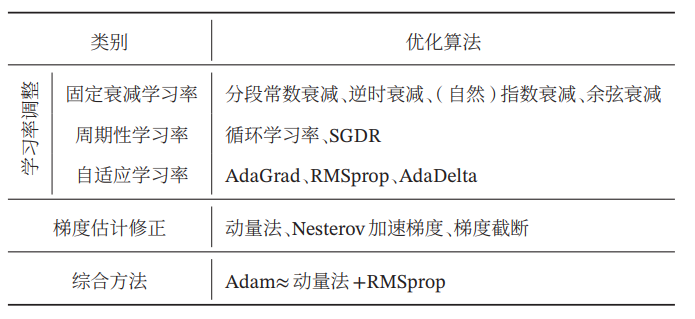
3.3.2 数据预处理
下面,我们将介绍一种特别常见的数据预处理方法:归一化
归一化方法泛指把数据特征转换为相同尺度的方法,比如把数据特征映射到[0, 1]或[−1, 1]区间内,或者映射为服从均值为0、方差为1的标准正态分布.
通俗易懂一点理解,为什么要归一化呢?
比如说我们要衡量一个人,Ta有三个特征: 年龄(岁)、身高(厘米)、体重(千克)
小明 = [18, 185, 80] 小红 = [13, 156, 50]
很明显可以看出,每个数值的单位是不一样的,它们的数据范围也不一样,所以数值的大小没有可比性,所以要把某个特征(某一列)统一压缩映射到一个范围才有计算和比较的意义。
下面介绍几种经常使用的归一化方法:
最小最大值归一化、标准化
最小最大值归一化
最小最大值归一化是一种非常简单的归一化方法,将训练集中某一列数值特征(假设是第 i 列)的值缩放到0和1之间,公式为:
xi−min(xi)max(xi)−min(xi)\frac{x_{\mathrm{i}}-\min \left(\mathrm{x}_{\mathrm{i}}\right)}{\max \left(\mathrm{x}_{\mathrm{i}}\right)-\min \left(\mathrm{x}_{\mathrm{i}}\right)} max(xi)−min(xi)xi−min(xi)
标准化
标准化也叫Z值归一化,来源于统计上的标准分数.将每一个维特征都调整为均值为0,方差为1
对于每一维特征xxx,它的均值为:μ=1N∑n=1Nx(n)\mu=\frac{1}{N} \sum_{n=1}^{N} x^{(n)}μ=N1∑n=1Nx(n),它的方差为:σ2=1N∑n=1N(x(n)−μ)2\sigma^{2}=\frac{1}{N} \sum_{n=1}^{N}\left(x^{(n)}-\mu\right)^{2}σ2=N1∑n=1N(x(n)−μ)2
然后,将特征x(n)x^{(n)}x(n) 减去均值,并除以标准差,得到新的特征值 x^(n)\hat{x}^{(n)}x^(n):
x^(n)=x(n)−μσ\hat{x}^{(n)}=\frac{x^{(n)}-\mu}{\sigma}x^(n)=σx(n)−μ 其中标准差 𝜎 不能为 0.如果标准差为 0,说明这一维特征没有任何区分性,可以直接删掉.
3.3.3 提前停止
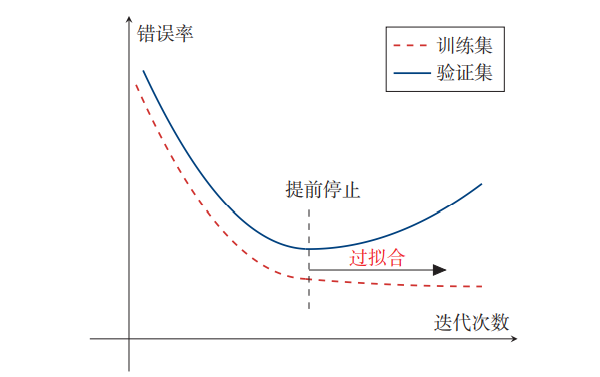
为了防止过拟合问题。除了训练集和测试集之外,有时也会使用一个验证集来进行模型选择,测试模型在验证集上是否最优.在每次迭代时,把新得到的模型 𝑓(𝒙; 𝜃) 在验证集上进行测试,并计算错误率.如果在验证集上的错误率不再下降,就停止迭代。 这种策略叫提前停止 。
下图是提前停止的示例
3.3.4 超参数优化
在机器学习中,优化又可以分为参数优化和超参数优化.模型𝑓(𝒙; 𝜃)中的𝜃 称为模型的参数,可以通过优化算法进行学习.除了可学习的参数𝜃 之外,还有一类参数是用来定义模型结构或优化策略的,这类参数叫作超参数。
常见的超参数包括:
聚类算法中的类别个数、梯度下降法中的步长、正则化分布的参数.项的系数、神经网络的层数、支持向量机中的核函数等.超参数的选取一般都是组合优化问题,很难通过优化算法来自动学习.因此,超参数优化根据人的经验不断试错得到.
4.线性模型
线性模型是机器学习中应用最广泛的模型,指通过样本特征的线性组合来进行预测的模型.给定一个 𝐷 维样本𝒙=[𝑥1,⋯,𝑥𝐷]T𝒙 = [𝑥_1, ⋯ , 𝑥_𝐷]^Tx=[x1,⋯,xD]T,其线性组合函数为
f(x;w)=w1x1+w2x2+⋯+wDxD+b=w⊤x+b\begin{aligned} f(\boldsymbol{x} ; \boldsymbol{w}) &=w_{1} x_{1}+w_{2} x_{2}+\cdots+w_{D} x_{D}+b \\ &=\boldsymbol{w}^{\top} \boldsymbol{x}+b \end{aligned} f(x;w)=w1x1+w2x2+⋯+wDxD+b=w⊤x+b
其中 𝒘=[𝑤1,⋯,𝑤𝐷]T𝒘 = [𝑤_1, ⋯ , 𝑤_𝐷]^Tw=[w1,⋯,wD]T 为 𝐷 维的权重向量,𝑏 为偏置。
在分类问题中,由于输出目标 𝑦 是一些离散的标签,而 𝑓(𝒙; 𝒘) 的值域为实数,因此无法直接用 𝑓(𝒙; 𝒘) 来进行预测,需要引入一个非线性的决策函数𝑔(⋅)来预测输出目标,其中𝑓(𝒙; 𝒘)也称为判别函数。
y=g(f(x;w))y=g(f(\boldsymbol{x} ; \boldsymbol{w}))y=g(f(x;w))
一个线性分类模型或线性分类器,是由一个(或多个)线性的判别函数 𝑓(𝒙;𝒘)=𝒘T𝒙+𝑏𝑓(𝒙; 𝒘) =𝒘^T𝒙 + 𝑏f(x;w)=wTx+b 和非线性的决策函数 𝑔(⋅) 组成。
这时候,可能很多同学又有一个问题了,为什么引入了一个非线性的决策函数 𝑔(⋅) ,还要说它是线性模型呢?
其实,区分线性模型和非线性模型主要是看它的决策边界是否为线性的,所谓决策边界就是能够把样本正确分类的一条边界。如图所示:
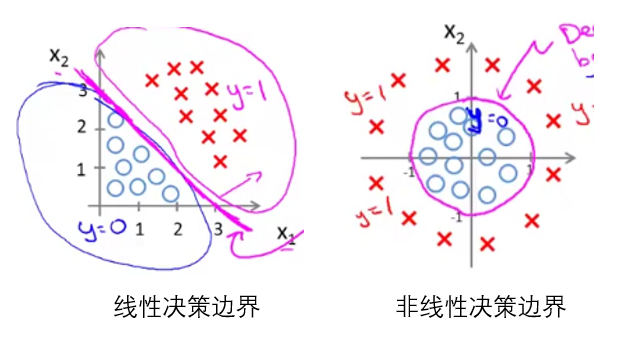
接下来我们继续讲分类问题,其中分类问题大致可以分为
二分类和多分类问题,二分类问题的类别标签 𝑦 只有两种取值,通常可以设为 {+1, −1} 或 {0, 1}.多分类问题是指分类的类别数 𝐶 大于 2.
下面介绍四种不同线性分类模型:感知器、Logistic回归、Softmax回归和支持向量机,这些模型的区别主要在于使用了不同的损失函数.
4.1 感知器
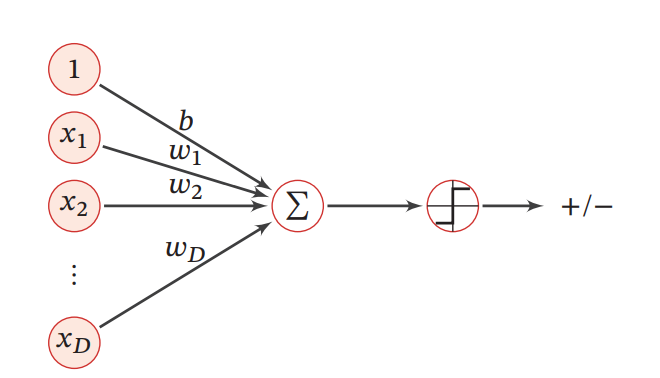
感知器是一种广泛使用的线性分类器,可谓是最简单的人工神经网络,只有一个神经元。
它的分类准则是一个简单的符号函数:
g(f(x;w))=sgn(f(x;w))≜{+1if f(x;w)>0−1if f(x;w)<0\begin{array}{l} g(f(\boldsymbol{x} ; \boldsymbol{w}))=\operatorname{sgn}(f(\boldsymbol{x} ; \boldsymbol{w}))\\ \triangleq\left\{\begin{array}{cl} +1 & \text { if } \quad f(\boldsymbol{x} ; \boldsymbol{w})>0 \\ -1 & \text { if } \quad f(\boldsymbol{x} ; \boldsymbol{w})<0 \end{array}\right. \end{array} g(f(x;w))=sgn(f(x;w))≜{+1−1 if f(x;w)>0 if f(x;w)<0
当𝑓(𝒙; 𝒘) = 0时不进行预测,它的结构图如下所示:
给定 N 个样本的训练集: {(x(n),y(n))}n=1N,\left\{\left(\boldsymbol{x}^{(n)}, y^{(n)}\right)\right\}_{n=1}^{N} ,{(x(n),y(n))}n=1N, 其中 y(n)∈{+1,−1}y^{(n)} \in\{+1,-1\}y(n)∈{+1,−1}, 感知器学习算法试图找到一组参数 w∗\boldsymbol{w}^{*}w∗ , 使得对于每个样本 (x(n),y(n))\left(\boldsymbol{x}^{(n)}, y^{(n)}\right)(x(n),y(n)) 有y(n)w∗⊤x(n)>0,∀n∈{1,⋯,N}y^{(n)} \boldsymbol{w}^{*^{\top}} \boldsymbol{x}^{(n)}>0, \quad \forall n \in\{1, \cdots, N\}y(n)w∗⊤x(n)>0,∀n∈{1,⋯,N}
因此感知器的损失函数为:
L(w;x,y)=max(0,−yw⊤x)\mathcal{L}(\boldsymbol{w} ; \boldsymbol{x}, y)=\max \left(0,-y \boldsymbol{w}^{\top} \boldsymbol{x}\right) L(w;x,y)=max(0,−yw⊤x)
采用梯度下降法进行更新,其每次更新的梯度为:
∂L(w;x,y)∂w={0if yw⊤x>0−yxif yw⊤x<0\frac{\partial \mathcal{L}(\boldsymbol{w} ; \boldsymbol{x}, y)}{\partial \boldsymbol{w}}=\left\{\begin{array}{ll} 0 & \text { if } \quad y \boldsymbol{w}^{\top} \boldsymbol{x}>0 \\ -y \boldsymbol{x} & \text { if } \quad y \boldsymbol{w}^{\top} \boldsymbol{x}<0 \end{array}\right. ∂w∂L(w;x,y)={0−yx if yw⊤x>0 if yw⊤x<0
下图给出了感知器参数学习的更新过程,其中被圈中的点为随机选取的要学习的点,红色实心点为正例,蓝色空心点为负例.黑色箭头表示当前的权重向量,红色虚线箭头表示权重的更新方向.
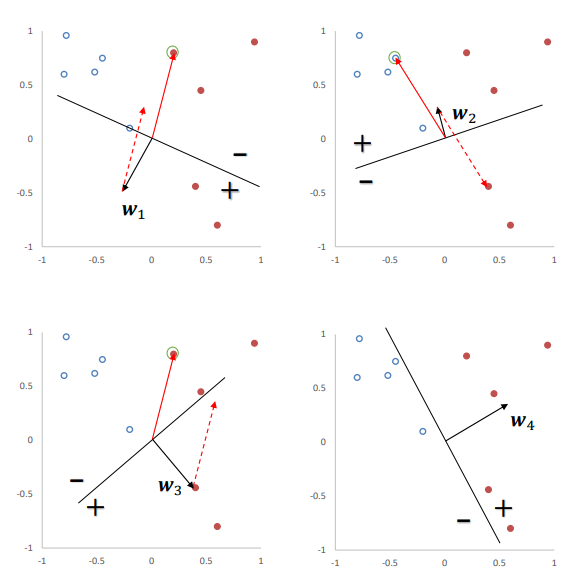
4.2 Logistic回归
Logistic 回归是一种常用的处理二分类问题的线性模型。我们将采用𝑦 ∈ {0, 1}以符合Logistic回归的描述习惯.
为了把线性函数的值域从实数区间“挤压”到了(0, 1)之间,可以用来表示概率,我们将使用一个激活函数𝑔(⋅)
p(y=t∣x)=g(f(x;w))p(y=t \mid \boldsymbol{x})=g(f(\boldsymbol{x} ; \boldsymbol{w})) p(y=t∣x)=g(f(x;w))
在Logistic回归中,我们使用
Logistic函数来作为激活函数
为什么要用Logistic函数呢?
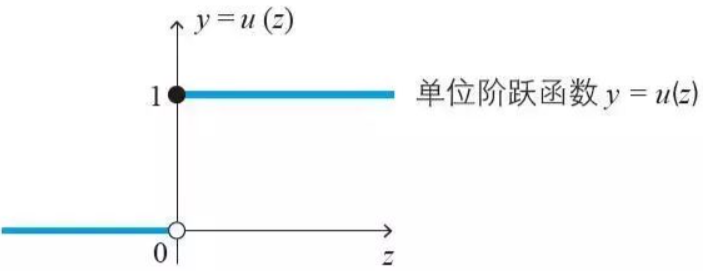
在分类问题中,我们可以用最简单的单位阶跃函数来作为激活函数𝑔(⋅):
y={0,z<00.5,z=01,z>0y=\left\{\begin{array}{cc} 0, & z<0 \\ 0.5, & z=0 \\ 1, & z>0 \end{array}\right.y=⎩⎨⎧0,0.5,1,z<0z=0z>0它长这个样子:
但是很可惜,它有一个很大的缺点:该函数在跳跃点上从0瞬间跳跃到1(不连续、不可微),所以我们想找到一个在一定程度上近似单位阶跃函数的“替代函数”,并希望它单调可微。
这时候,
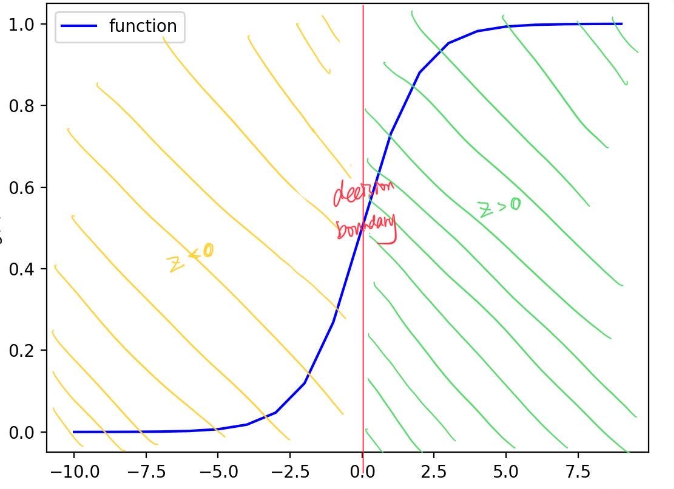
Logistic函数就登场了,其公式为:
σ(z)=11+e−z\sigma(z)=\frac{1}{1+e^{-z}} σ(z)=1+e−z1
它长酱紫, 它在z=0z=0z=0附近变化会很陡:
其导数为:
σ′(z)=σ(z)(1−σ(z))\sigma^{\prime}(z)=\sigma(z)(1-\sigma(z)) σ′(z)=σ(z)(1−σ(z))
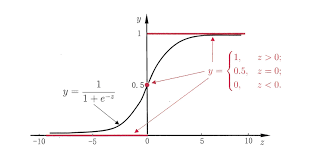
我们来对比一下
单位阶跃函数和Logistic函数:
长相和效果还蛮像的对叭

标签𝑦 = 1(也就是正例)的后验概率为:
p(y=1∣x)=σ(w⊤x+b)≜11+e−(w⊤x+b),\begin{aligned} p(y=1 \mid \boldsymbol{x}) &=\sigma\left(\boldsymbol{w}^{\top} \boldsymbol{x}+b\right) \triangleq \frac{1}{1+e^{- \left(\boldsymbol{w}^{\top} \boldsymbol{x}+b\right)}}, \end{aligned} p(y=1∣x)=σ(w⊤x+b)≜1+e−(w⊤x+b)1,
标签𝑦 = 0(反例)的后验概率为
p(y=0∣x)=1−p(y=1∣x)=e−(w⊤x+b)1+e−(w⊤x+b)\begin{aligned} p(y=0 \mid \boldsymbol{x}) &=1-p(y=1 \mid \boldsymbol{x})=\frac{e^{-\left(\boldsymbol{w}^{\top} \boldsymbol{x}+b\right)}}{1+e^{- \left(\boldsymbol{w}^{\top} \boldsymbol{x}+b\right)}} \end{aligned} p(y=0∣x)=1−p(y=1∣x)=1+e−(w⊤x+b)e−(w⊤x+b)
然后给大家变个魔法,把上面的式子变形一下可以得到:
w⊤x=logp(y=1∣x)1−p(y=1∣x)=logp(y=1∣x)p(y=0∣x)\boldsymbol{w}^{\top} \boldsymbol{x}=\log \frac{p(y=1 \mid \boldsymbol{x})}{1-p(y=1 \mid \boldsymbol{x})} =\log \frac{p(y=1 \mid x)}{p(y=0 \mid x)} w⊤x=log1−p(y=1∣x)p(y=1∣x)=logp(y=0∣x)p(y=1∣x)
我们仔细看看,其中 p(y=1∣x)p(y=0∣x)\frac{p(y=1 \mid x)}{p(y=0 \mid x)}p(y=0∣x)p(y=1∣x) 为样本𝒙为正反例后验概率的比值,称为几率,几率的对数称为对数几率,因此 Logistic 回归可以看作预测值为“标签的对数几率”的线性回归模型。
Logistic 回归采用交叉熵作为损失函数,并使用梯度下降法来对参数进行优化.
设一个样本标签为1的预测概率为:
y^(n)=σ(w⊤x(n)+b),\hat{y}^{(n)}=\sigma\left(\boldsymbol{w}^{\top} \boldsymbol{x}^{(n)}+b\right), y^(n)=σ(w⊤x(n)+b),
设一个样本标签为1的真实概率为:
pr(y(n)=1∣x(n))=y(n)p_{r}\left(y^{(n)}=1 \mid x^{(n)}\right)=y^{(n)} pr(y(n)=1∣x(n))=y(n)
使用交叉熵损失函数,假设有N个样本,公式为:
R(𝒘)==−1N∑n=1N(y(n)logy^(n)+(1−y(n))log(1−y^(n))).R(𝒘) = =-\frac{1}{N} \sum_{n=1}^{N}\left(y^{(n)} \log \hat{y}^{(n)}+\left(1-y^{(n)}\right) \log \left(1-\hat{y}^{(n)}\right)\right) .R(w)==−N1n=1∑N(y(n)logy^(n)+(1−y(n))log(1−y^(n))).
ℛ(𝒘)关于参数𝒘的偏导数为:
∂R(w)∂w=−1N∑n=1N(y(n)y^(n)(1−y^(n))y^(n)x(n)−(1−y(n))y^(n)(1−y^(n))1−y^(n)x(n))=−1N∑n=1N(y(n)(1−y^(n))x(n)−(1−y(n))y^(n)x(n))=−1N∑n=1Nx(n)(y(n)−y^(n)).\begin{aligned} \frac{\partial \mathcal{R}(\boldsymbol{w})}{\partial \boldsymbol{w}} &=-\frac{1}{N} \sum_{n=1}^{N}\left(y^{(n)} \frac{\hat{y}^{(n)}\left(1-\hat{y}^{(n)}\right)}{\hat{y}^{(n)}} \boldsymbol{x}^{(n)}-\left(1-y^{(n)}\right) \frac{\hat{y}^{(n)}\left(1-\hat{y}^{(n)}\right)}{1-\hat{y}^{(n)}} \boldsymbol{x}^{(n)}\right) \\ &=-\frac{1}{N} \sum_{n=1}^{N}\left(y^{(n)}\left(1-\hat{y}^{(n)}\right) \boldsymbol{x}^{(n)}-\left(1-y^{(n)}\right) \hat{y}^{(n)} \boldsymbol{x}^{(n)}\right) \\ &=-\frac{1}{N} \sum_{n=1}^{N} \boldsymbol{x}^{(n)}\left(y^{(n)}-\hat{y}^{(n)}\right) . \end{aligned} ∂w∂R(w)=−N1n=1∑N(y(n)y^(n)y^(n)(1−y^(n))x(n)−(1−y(n))1−y^(n)y^(n)(1−y^(n))x(n))=−N1n=1∑N(y(n)(1−y^(n))x(n)−(1−y(n))y^(n)x(n))=−N1n=1∑Nx(n)(y(n)−y^(n)).
𝑦̂ 为 Logistic 函 数,求导公式在上面。这时的 logloglog 是以 eee 为底的
然后我们就采取梯度下降法进行迭代更新了,初始化 𝒘0 ← 0,然后通过下式来迭代更新参数:
wt+1←wt+α1N∑n=1Nx(n)(y(n)−y^wt(n)),\boldsymbol{w}_{t+1} \leftarrow \boldsymbol{w}_{t}+\alpha \frac{1}{N} \sum_{n=1}^{N} \boldsymbol{x}^{(n)}\left(y^{(n)}-\hat{y}_{w_{t}}^{(n)}\right), wt+1←wt+αN1n=1∑Nx(n)(y(n)−y^wt(n)),
4.3 Softmax回归
Softmax 回归,也称为多项或多类的Logistic回归,是Logistic回归在多分类问题上的推广.
对于多类问题,类别标签𝑦 ∈ {1, 2, ⋯ , 𝐶}可以有𝐶 个取值.给定一个样本𝒙,Softmax回归预测的属于类别𝑐的条件概率为
p(y=c∣x)=softmax(wc⊤x+b)=e(wc⊤x+b)∑c′=1Ce(wc′⊤x+b),\begin{aligned} p(y=c \mid \boldsymbol{x}) &=\operatorname{softmax}\left(\boldsymbol{w}_{c}^{\top} \boldsymbol{x}+b\right) \\ &=\frac{e^{ \left(\boldsymbol{w}_{c}^{\top} \boldsymbol{x}+b\right)}}{\sum_{c^{\prime}=1}^{C}e^{ \left(\boldsymbol{w}_{c^{\prime}}^{\top} \boldsymbol{x}+b\right)}}, \end{aligned} p(y=c∣x)=softmax(wc⊤x+b)=∑c′=1Ce(wc′⊤x+b)e(wc⊤x+b),
Softmax回归的决策函数可以表示为:
y^=argmaxCc=1p(y=c∣x)=argmaxCc=1(wc⊤x+b).\begin{array}{l} \hat{y}=\underset{c=1}{\overset{C}{\arg \max }} p(y=c \mid \boldsymbol{x})\\ =\underset{c=1}{\overset{C}{\arg \max }}\left( \boldsymbol{w}_{c}^{\top} \boldsymbol{x}+b\right) . \end{array} y^=c=1argmaxCp(y=c∣x)=c=1argmaxC(wc⊤x+b).
这时候你可能又要问了,这个argmax到底是个什么东西呀?
根据定义,argmax()是一种函数,是对函数求参数(集合)的函数,也就是求自变量最大的函数。
举个例子:
f(x=1)=20f(x=1)=20f(x=1)=20 f(x=2)=25f(x=2)=25f(x=2)=25 f(x=3)=22f(x=3)=22f(x=3)=22
可以得出:
y=max(f(x))=25y=\max (f(x))=25y=max(f(x))=25
y=argmax(f(x))=2y=\operatorname{argmax}(f(x))=2y=argmax(f(x))=2
回归到问题本身,我们为什么用argmax而不用max呢?
因为我们要得到的答案是这个样本是哪一类的,而不是它属于这一类的概率是多少,所以我们要用argmax来得到概率最大值的自变量。
采用交叉熵损失函数,Softmax回归模型的风险函数为:
R(W)=−1N∑n=1N(y(n))⊤logy^(n)\begin{aligned} \mathcal{R}(\boldsymbol{W}) &= -\frac{1}{N} \sum_{n=1}^{N}\left(\boldsymbol{y}^{(n)}\right)^{\boldsymbol{\top}} \log \hat{\boldsymbol{y}}^{(n)} \end{aligned} R(W)=−N1n=1∑N(y(n))⊤logy^(n)风险函数ℛ(𝑾 )关于𝑾 的梯度为
∂R(W)∂W=−1N∑n=1Nx(n)(y(n)−y^(n))⊤\frac{\partial \mathcal{R}(\boldsymbol{W})}{\partial \boldsymbol{W}}=-\frac{1}{N} \sum_{n=1}^{N} \boldsymbol{x}^{(n)}\left(\boldsymbol{y}^{(n)}-\hat{\boldsymbol{y}}^{(n)}\right)^{\top} ∂W∂R(W)=−N1n=1∑Nx(n)(y(n)−y^(n))⊤
采用梯度下降法,Softmax回归的训练过程为:初始化𝑾0←0𝑾_0 ← 0W0←0,然后通过下式进行迭代更新:
Wt+1←Wt+α(1N∑n=1Nx(n)(y(n)−y^Wt(n))⊤)\boldsymbol{W}_{t+1} \leftarrow \boldsymbol{W}_{t}+\alpha\left(\frac{1}{N} \sum_{n=1}^{N} \boldsymbol{x}^{(n)}\left(\boldsymbol{y}^{(n)}-\hat{\boldsymbol{y}}_{W_{t}}^{(n)}\right)^{\top}\right) Wt+1←Wt+α(N1n=1∑Nx(n)(y(n)−y^Wt(n))⊤)
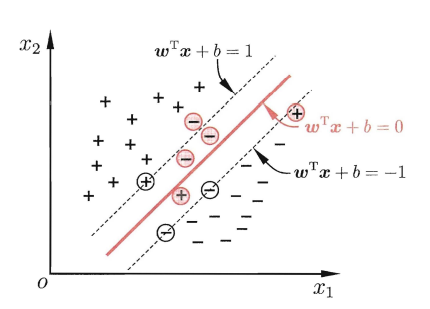
4.4 支持向量机
支持向量机(SVM)是一个经典的二分类算法,其找到的分割超平面具有更好的鲁棒性。
给定一个二分类器数据集D={(x(n),y(n))}n=1N\mathcal{D}=\left\{\left(\boldsymbol{x}^{(n)}, y^{(n)}\right)\right\}_{n=1}^{N}D={(x(n),y(n))}n=1N,其中yn∈{+1,−1}y_{n} \in\{+1,-1\}{\scriptsize }yn∈{+1,−1},如果两类样本是线性可分的,即存在一个超平面
w⊤x+b=0\boldsymbol{w}^{\top} \boldsymbol{x}+b=0w⊤x+b=0将两类样本分开,那么对于每个样本都有y(n)(w⊤x(n)+b)>0y^{(n)}\left(\boldsymbol{w}^{\top} \boldsymbol{x}^{(n)}+b\right)>0y(n)(w⊤x(n)+b)>0,数据集𝒟 中每个样本𝒙(𝑛)𝒙^{(𝑛)}x(n)到分割超平面的距离为:
γ(n)=∣w⊤x(n)+b∣∥w∥=y(n)(w⊤x(n)+b)∥w∥.\gamma^{(n)}=\frac{\left|\boldsymbol{w}^{\top} \boldsymbol{x}^{(n)}+b\right|}{\|\boldsymbol{w}\|}=\frac{y^{(n)}\left(\boldsymbol{w}^{\top} \boldsymbol{x}^{(n)}+b\right)}{\|\boldsymbol{w}\|} .γ(n)=∥w∥∣∣w⊤x(n)+b∣∣=∥w∥y(n)(w⊤x(n)+b).
我们定义间隔 𝛾 为整个数据集 𝐷 中所有样本到分割超平面的最短距离:γ=minnγ(n)\gamma=\min _{n} \gamma^{(n)}γ=nminγ(n)如下图所示,我们可以找到很多点来分隔,但能将训练样本分开的划分超平面可能有很多,我们要找到哪一个呢?
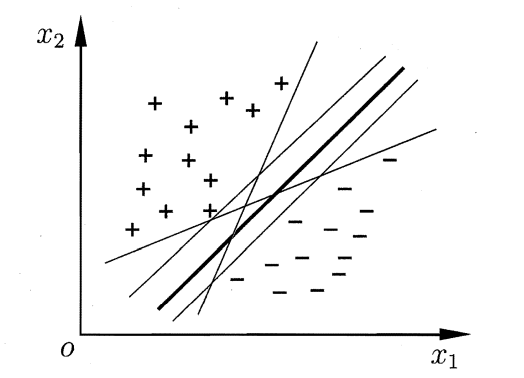
显然,我们要找到一个最稳定的平面。如果间隔𝛾越大,其分割超平面对两个数据集的划分越稳定,不容易受噪声等因素影响.支持向量机的目标是寻找一个超平面(𝒘∗, 𝑏∗)使得𝛾最大,即
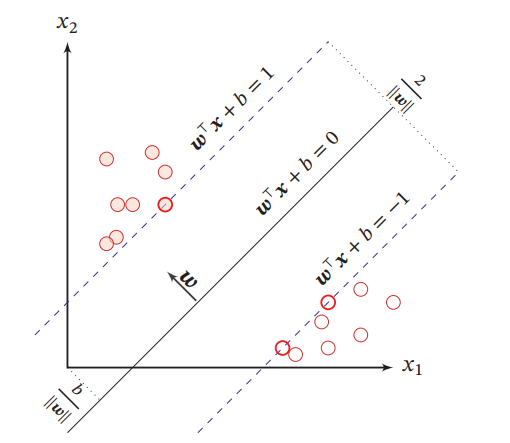
maxw,bγs.t. y(n)(w⊤x(n)+b)∥w∥≥γ,∀n∈{1,⋯,N}.\begin{aligned} \max _{\boldsymbol{w}, b} & \gamma \\ \text { s.t. } & \frac{y^{(n)}\left(\boldsymbol{w}^{\top} \boldsymbol{x}^{(n)}+b\right)}{\|\boldsymbol{w}\|} \geq \gamma, \forall n \in\{1, \cdots, N\} . \end{aligned} w,bmax s.t. γ∥w∥y(n)(w⊤x(n)+b)≥γ,∀n∈{1,⋯,N}.由于同时缩放𝒘 → 𝑘𝒘和𝑏 → 𝑘𝑏不会改变样本𝒙(𝑛)𝒙^{(𝑛)}x(n) 到分割超平面的距离,我们可以限制‖𝒘‖ ⋅ 𝛾 = 1,则上述公式等价于
maxw,b1∥w∥2s.t. y(n)(w⊤x(n)+b)≥1,∀n∈{1,⋯,N}.\begin{aligned} \max _{\boldsymbol{w}, b} & \frac{1}{\|\boldsymbol{w}\|^{2}} \\ \text { s.t. } & y^{(n)}\left(\boldsymbol{w}^{\top} \boldsymbol{x}^{(n)}+b\right) \geq 1, \forall n \in\{1, \cdots, N\} . \end{aligned} w,bmax s.t. ∥w∥21y(n)(w⊤x(n)+b)≥1,∀n∈{1,⋯,N}.数据集中所有满足y(n)(w⊤x(n)+b)=1y^{(n)}\left(\boldsymbol{w}^{\top} \boldsymbol{x}^{(n)}+b\right)=1y(n)(w⊤x(n)+b)=1 的样本点,都称为支持向量
如图支持向量机的最大间隔分割超平面的示例,其中轮廓线加粗的样本点为支持向量.
4.4.1 参数学习
为了找到最大间隔分割超平面,将目标函数写为凸优化问题
minw,b12∥w∥2s.t. 1−y(n)(w⊤x(n)+b)≤0,∀n∈{1,⋯,N}.\begin{aligned} \min _{\boldsymbol{w}, b} & \frac{1}{2}\|\boldsymbol{w}\|^{2} \\ \text { s.t. } & 1-y^{(n)}\left(\boldsymbol{w}^{\top} \boldsymbol{x}^{(n)}+b\right) \leq 0, \quad \forall n \in\{1, \cdots, N\} . \end{aligned}w,bmin s.t. 21∥w∥21−y(n)(w⊤x(n)+b)≤0,∀n∈{1,⋯,N}.
这时候可能又有疑问了,什么是凸优化问题呢?
先记住凸优化问题一个重要的特点:局部最优是全局最优
凸优化问题是想要找到一个酱紫的解:
minf0(x)subject to fi(x)≤0,i=1,⋯,mhi(x)=0,i=1,⋯,p\begin{array}{ll} min & f_0(x)\\ \text { subject to } & f_{i}(x) \leq 0, \quad i=1, \cdots, m \\ & h_{i}(x)=0, \quad i=1, \cdots, p \end{array}min subject to f0(x)fi(x)≤0,i=1,⋯,mhi(x)=0,i=1,⋯,p
下面两个式子分别表示不等式约束和等式约束下面两个式子分别表示不等式约束和等式约束下面两个式子分别表示不等式约束和等式约束
其中 f0为凸函数, fi为凸函数, hi为仿射函数, x为优化变量。 \text {其中 } f_0 \text { 为凸函数, } f_{i} \text { 为凸函数, } h_{i} \text { 为仿射函数, } x \text { 为优化变量。 }其中 f0 为凸函数, fi 为凸函数, hi 为仿射函数, x 为优化变量。
注意上面的min以及约束条件的符号均要符合规定!!!注意上面的 min 以及约束条件的符号均要符合规定!!!注意上面的min以及约束条件的符号均要符合规定!!!
仿射函数::aTx+b: a^{T} x+b:aTx+b,它同时满足凸函数和凹函数
在上面学习正则化的时候,我们讲了拉格朗日乘数法的几何意义,下面我们来数学证明一下。
根据上面的在约束条件求最值的条件下,我们化成拉格朗日函数
L(x,λ,v)=f0(x)+∑λifi(x)+∑vihi(x)L(\boldsymbol{x}, \boldsymbol{\lambda}, \boldsymbol{v})=f_{0}(\boldsymbol{x})+\sum \lambda_{i} f_{i}(\boldsymbol{x})+\sum v_{i} h_{i}(\boldsymbol{x})L(x,λ,v)=f0(x)+∑λifi(x)+∑vihi(x)
然后我们化成原问题(即先将λ\lambdaλ和vvv看成变量,xxx看成常量求最大值,再把xxx看成变量求最小值):
minxmaxλ,vL(x,λ,v)s.t. λ≥0\begin{array}{l} \min _{\boldsymbol{x}} \max _{\lambda, v} L(\boldsymbol{x}, \boldsymbol{\lambda}, \boldsymbol{v}) \\ \text { s.t. } \lambda \geq 0 \end{array}minxmaxλ,vL(x,λ,v) s.t. λ≥0
然后我们证明一下为什么可以化成这样:
{x不在可行域内: maxλ,vL(x,λ,v)=f0(x)+∞+∞=∞x在可行域内 :maxλ,vL(x,λ,v)=f0(x)+0+0=f0(x)\left\{\begin{array}{l} \boldsymbol{x} \text { 不在可行域内: } \max _{\lambda, v} L(\boldsymbol{x}, \boldsymbol{\lambda}, \boldsymbol{v})=f_{0}(\boldsymbol{x})+\infty+\infty=\infty \\ \boldsymbol{x} \text { 在可行域内 }: \max _{\lambda, v} L(\boldsymbol{x}, \boldsymbol{\lambda}, \boldsymbol{v})=f_{0}(\boldsymbol{x})+0+0=f_{0}(\boldsymbol{x}) \end{array}\right.{x 不在可行域内: maxλ,vL(x,λ,v)=f0(x)+∞+∞=∞x 在可行域内 :maxλ,vL(x,λ,v)=f0(x)+0+0=f0(x)minxmaxλ,vL(x,λ,v)=minx{f0(x),∞}=minf0(x)\min _{\boldsymbol{x}} \max _{\lambda, \boldsymbol{v}} L(\boldsymbol{x}, \boldsymbol{\lambda}, \boldsymbol{v})=\min _{\boldsymbol{x}}\left\{f_{0}(\boldsymbol{x}), \infty\right\}= \min f_0(x)xminλ,vmaxL(x,λ,v)=xmin{f0(x),∞}=minf0(x)
下面再来介绍一下
对偶函数和对偶问题:
对偶函数:
g(λ,v)=minxL(x,λ,v)g(\boldsymbol{\lambda}, \boldsymbol{v})=\min _{\boldsymbol{x}} L(\boldsymbol{x}, \boldsymbol{\lambda}, \boldsymbol{v})g(λ,v)=xminL(x,λ,v)
对偶问题(即先将xxx看成变量,把λ\lambdaλ和vvv看成常量求最小值,再把λ\lambdaλ和vvv看成变量求最大值:
maxλ,vg(λ,v)=maxλ,vminxL(x,λ,v)s.t. λ≥0\begin{array}{l} \max _{\lambda, v} g(\boldsymbol{\lambda}, \boldsymbol{v})=\max _{\lambda, v} \min _{x} L(\boldsymbol{x}, \boldsymbol{\lambda}, \boldsymbol{v}) \\ \text { s.t. } \lambda \geq \mathbf{0} \end{array}maxλ,vg(λ,v)=maxλ,vminxL(x,λ,v) s.t. λ≥0上式等价于:
maxλ,vg(λ,v)s.t.∇xL(x,λ,v)=0λ≥0\begin{array}{ll} \max _{\boldsymbol{\lambda}, \boldsymbol{v}} g(\boldsymbol{\lambda}, \boldsymbol{v}) \\ \text { s.t.} &\nabla_{\boldsymbol{x}} L(\boldsymbol{x}, \boldsymbol{\lambda}, \boldsymbol{v})=\mathbf{0} \\ &\boldsymbol{\lambda} \geq \mathbf{0} \end{array}maxλ,vg(λ,v) s.t.∇xL(x,λ,v)=0λ≥0
看完后是不是觉得像上面的原问题反过来换种方法求解嘞?
对偶问题有一个重要的特性:无论原问题是什么,对偶问题都是一个凸问题!!(注意,原问题化成对偶问题的方向是单向的!)
我超!!这也太神奇了吧,为什么无论什么问题的对偶问题都是凸问题呢??
我们先来看一下这个对偶函数,我们假设x∗x^*x∗是找到的拉格朗日函数的最小值:
g(λ,v)=f0(x⋆)+∑λifi(x⋆)+∑vihi(x⋆)g(\boldsymbol{\lambda}, \boldsymbol{v})=f_{0}\left(x^{\star}\right)+\sum \lambda_{i} f_{i}\left(x^{\star}\right)+\sum v_{i} h_{i}\left(x^{\star}\right)g(λ,v)=f0(x⋆)+∑λifi(x⋆)+∑vihi(x⋆)这时候只有λ\lambdaλ和vvv是变量,这时候g(λ,v)g(\boldsymbol{\lambda}, \boldsymbol{v})g(λ,v)就是一阶线性关系的,它可以看成是一条直线,这时候它既是凹函数又是凸函数,求它的最大值就是凸优化问题。
我们很容易得到,原问题的解是大于等于对偶问题的解的(弱对偶定理),即:
minxmaxλ,vL(x,λ,v)≥maxλ,vminxL(x,λ,v)\min _{x} \max _{\lambda, v} L(x, \lambda, v) \geq \max _{\lambda, v} \min _{x} L(x, \lambda, v)xminλ,vmaxL(x,λ,v)≥λ,vmaxxminL(x,λ,v)
当然,我们肯定想要原问题的解是等于对偶问题的解的(强对偶定理),这时候我们就要用KKT条件进行约束了:
KKT条件:
fi(x)≤0hi(x)=0}原问题可行条件\left.\begin{array}{l}f_{i}(\boldsymbol{x}) \leq 0 \\ h_{i}(\boldsymbol{x})=0\end{array}\right\} 原问题可行条件 fi(x)≤0hi(x)=0}原问题可行条件∇xL(x,λ,v)=0λ≥0}对偶可行条件\left.\begin{array}{l}\nabla_{x} L(x, \lambda, v)=0 \\ \lambda \geq 0\end{array}\right\} 对偶可行条件∇xL(x,λ,v)=0λ≥0}对偶可行条件λifi(x)=0互补松弛条件 \lambda_{i} f_{i}(\boldsymbol{x})=0 \quad \text {互补松弛条件 }λifi(x)=0互补松弛条件
使用拉格朗日乘数法,将公式化为拉格朗日函数:
Λ(w,b,λ)=12∥w∥2+∑n=1Nλn(1−y(n)(w⊤x(n)+b))\Lambda(\boldsymbol{w}, b, \lambda)=\frac{1}{2}\|\boldsymbol{w}\|^{2}+\sum_{n=1}^{N} \lambda_{n}\left(1-y^{(n)}\left(\boldsymbol{w}^{\top} \boldsymbol{x}^{(n)}+b\right)\right)Λ(w,b,λ)=21∥w∥2+n=1∑Nλn(1−y(n)(w⊤x(n)+b))
其中λ1≥0,⋯,λ𝑁≥0\lambda_1 ≥ 0, ⋯ , \lambda_𝑁 ≥ 0λ1≥0,⋯,λN≥0为拉格朗日乘数.计算Λ(𝒘, 𝑏, 𝜆)关于𝒘和𝑏的导数,并令其等于0,得到
w=∑n=1Nλny(n)x(n),0=∑n=1Nλny(n)\begin{aligned} \boldsymbol{w} &=\sum_{n=1}^{N} \lambda_{n} y^{(n)} \boldsymbol{x}^{(n)}, \\ 0 &=\sum_{n=1}^{N} \lambda_{n} y^{(n)} \end{aligned} w0=n=1∑Nλny(n)x(n),=n=1∑Nλny(n)
公式代换,得到拉格朗日对偶函数:
Γ(λ)=−12∑n=1N∑m=1Nλmλny(m)y(n)(x(m))⊤x(n)+∑n=1Nλn.\Gamma(\lambda)=-\frac{1}{2} \sum_{n=1}^{N} \sum_{m=1}^{N} \lambda_{m} \lambda_{n} y^{(m)} y^{(n)}\left(\boldsymbol{x}^{(m)}\right)^{\top} \boldsymbol{x}^{(n)}+\sum_{n=1}^{N} \lambda_{n} .Γ(λ)=−21n=1∑Nm=1∑Nλmλny(m)y(n)(x(m))⊤x(n)+n=1∑Nλn.
根据KKT条件中的互补松弛条件,最优解满足λn∗(1−y(n)(w∗⊤x(n)+b∗))=0\lambda_{n}^{*}\left(1-y^{(n)}\left(\boldsymbol{w}^{* \top} \boldsymbol{x}^{(n)}+b^{*}\right)\right)=0λn∗(1−y(n)(w∗⊤x(n)+b∗))=0
在计算出 𝜆∗ 后,根据公式 w=∑n=1Nλny(n)x(n)\boldsymbol{w} =\sum_{n=1}^{N} \lambda_{n} y^{(n)} \boldsymbol{x}^{(n)}w=∑n=1Nλny(n)x(n) 计算出最优权重 𝒘∗,最优偏置 𝑏∗ 可以通过任选一个支持向量(𝒙,̃𝑦)̃计算得到
b∗=y~−w∗⊤x~.b^{*}=\tilde{y}-\boldsymbol{w}^{*^{\top}} \tilde{\boldsymbol{x}} .b∗=y~−w∗⊤x~.
最优参数的支持向量机的决策函数为
f(x)=sgn(w∗⊤x+b∗)=sgn(∑n=1Nλn∗y(n)(x(n))⊤x+b∗)\begin{aligned} f(\boldsymbol{x}) &=\operatorname{sgn}\left(\boldsymbol{w}^{*^{\top}} \boldsymbol{x}+b^{*}\right) \\ &=\operatorname{sgn}\left(\sum_{n=1}^{N} \lambda_{n}^{*} y^{(n)}\left(\boldsymbol{x}^{(n)}\right)^{\top} \boldsymbol{x}+b^{*}\right) \end{aligned}f(x)=sgn(w∗⊤x+b∗)=sgn(n=1∑Nλn∗y(n)(x(n))⊤x+b∗)
4.4.2 核函数
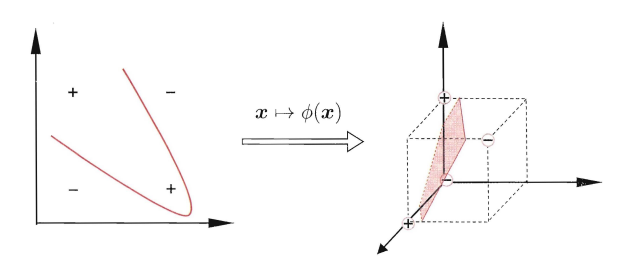
支持向量机还有一个重要的优点是可以使用核函数隐式地将样本从原始特征空间映射到更高维的空间,并解决原始特征空间中的线性不可分问题。面例如图中左边的"异或“问题就不是线性可分的,但将其映射到如图右的高维空间是可以变成线性可分的。
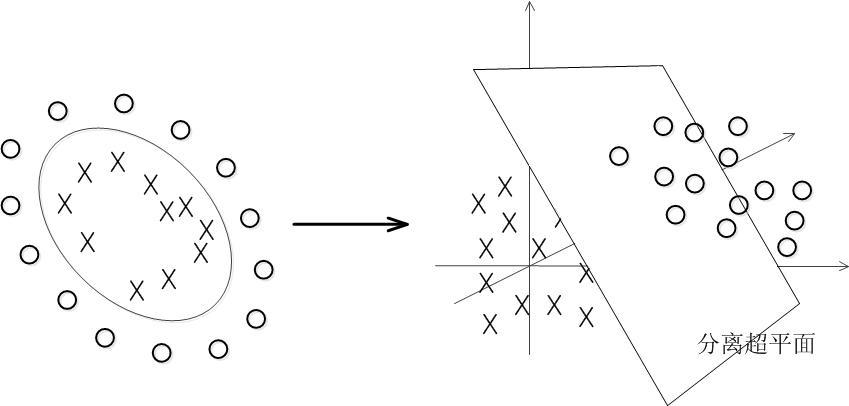
再比如这样:
比如在一个变换后的特征空间𝜙中,支持向量机的决策函数为:
f(x)=sgn(w∗⊤ϕ(x)+b∗)=sgn(∑n=1Nλn∗y(n)k(x(n),x)+b∗)\begin{aligned} f(\boldsymbol{x}) &=\operatorname{sgn}\left(\boldsymbol{w}^{* \top} \phi(\boldsymbol{x})+b^{*}\right) \\ &=\operatorname{sgn}\left(\sum_{n=1}^{N} \lambda_{n}^{*} y^{(n)} k\left(\boldsymbol{x}^{(n)}, \boldsymbol{x}\right)+b^{*}\right) \end{aligned} f(x)=sgn(w∗⊤ϕ(x)+b∗)=sgn(n=1∑Nλn∗y(n)k(x(n),x)+b∗)
其中 𝑘(𝒙,𝒛)=ϕ(𝒙)Tϕ(𝒛)𝑘(𝒙, 𝒛) = \phi(𝒙)^T\phi(𝒛)k(x,z)=ϕ(x)Tϕ(z) 为核函数.
"核函数选择"成为支持向量机的最大变数.若核函数选择不合适,则意味着将样本映射到了一个不合适的特征空间,很可能导致性能不佳。
以下是一些常用的核函数:
| 名称 | 表达式 | 参数 |
|---|---|---|
| 线性核 | κ(xi,xj)=xiTxj\kappa\left(\boldsymbol{x}_{i}, \boldsymbol{x}_{j}\right)=\boldsymbol{x}_{i}^{\mathrm{T}} \boldsymbol{x}_{j}κ(xi,xj)=xiTxj | |
| 多项式核 | κ(xi,xj)=(xiTxj)d\kappa\left(x_{i}, x_{j}\right)=\left(x_{i}^{\mathrm{T}} x_{j}\right)^{d}κ(xi,xj)=(xiTxj)d | d≥1d\ge1d≥1为多项式的次数 |
| 高斯核 | κ(xi,xj)=exp(−∣xi−xj∣22σ2)\kappa\left(\boldsymbol{x}_{i}, \boldsymbol{x}_{j}\right)=\exp \left(-\frac{\left|\boldsymbol{x}_{i}-\boldsymbol{x}_{j}\right|^{2}}{2 \sigma^{2}}\right)κ(xi,xj)=exp(−2σ2∣xi−xj∣2) | σ>0σ>0σ>0 为高斯核的带宽(width) |
| 拉普拉斯核 | κ(xi,xj)=exp(−∣xi−xj∣σ)\kappa\left(\boldsymbol{x}_{i}, \boldsymbol{x}_{j}\right)=\exp \left(-\frac{\left|\boldsymbol{x}_{i}-\boldsymbol{x}_{j}\right|}{\sigma}\right)κ(xi,xj)=exp(−σ∣xi−xj∣) | σ>0σ>0σ>0 |
| Sigmoid核 | κ(xi,xj)=tanh(βxiTxj+θ)\kappa\left(\boldsymbol{x}_{i}, \boldsymbol{x}_{j}\right)=\tanh \left(\beta \boldsymbol{x}_{i}^{\mathrm{T}} \boldsymbol{x}_{j}+\theta\right)κ(xi,xj)=tanh(βxiTxj+θ) | tanh 为双曲正切函数,β>0,θ<0\beta>0, \theta<0β>0,θ<0 |
4.4.3 软间隔
在支持向量机的优化问题中,约束条件比较严格.如果训练集中的样本在特征空间中不是线性可分的,就无法找到最优解.为了能够容忍部分不满足约束的样本,我们可以引入松弛变量 𝜉,将优化问题变为
minw,b12∥w∥2+C∑n=1Nξns.t.1−y(n)(w⊤x(n)+b)−ξn≤0,∀n∈{1,⋯,N}ξn≥0,∀n∈{1,⋯,N}\min _{\boldsymbol{w}, b} \frac{1}{2}\|\boldsymbol{w}\|^{2}+C \sum_{n=1}^{N} \xi_{n}\\ s.t. \quad1-y^{(n)}\left(\boldsymbol{w}^{\top} \boldsymbol{x}^{(n)}+b\right)-\xi_{n} \leq 0,\quad \forall n \in\{1, \cdots, N\} \\ \xi_{n} \geq 0, \quad \forall n \in\{1, \cdots, N\} w,bmin21∥w∥2+Cn=1∑Nξns.t.1−y(n)(w⊤x(n)+b)−ξn≤0,∀n∈{1,⋯,N}ξn≥0,∀n∈{1,⋯,N}
如图所示:红色圈出了一些不满足约束的样本.
4.5 损失函数对比
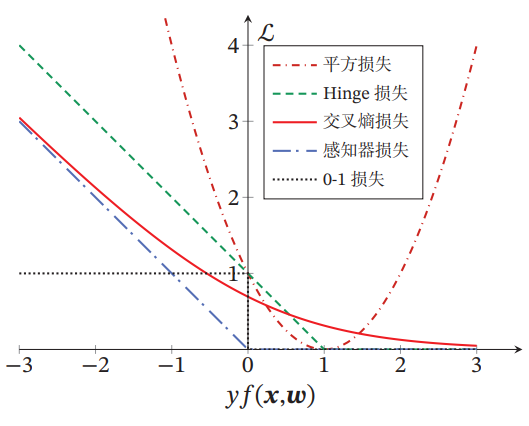
损失函数的不同,会让模型它们在实际任务上的表现存在一定的差异。
下图给出了不同损失函数的对比.对于二分类来说,当𝑦𝑓(𝒙; 𝒘) > 0时,分类器预测正确,并且𝑦𝑓(𝒙; 𝒘)越大,模型的预测越正确;当𝑦𝑓(𝒙; 𝒘) < 0时,分类器预测错误,并且𝑦𝑓(𝒙; 𝒘)越小,模型的预测越错误.因此,一个好的损失函数应该随着𝑦𝑓(𝒙; 𝒘)的增大而减少.
从下图中看出,除了平方损失,其他损失函数都比较适合于二分类问题.
5. 写在最后
好了,今天的机器学习的内容就分享到这里了
哈哈,是不是看到这一堆公式就头昏脑胀的。但我告诉你,这只是开始。
继续加油叭!!!
