python:基础知识
环境:
- window11
- python 3.10.6
- vscode
- javascript、c/c++/java/c#基础(与这些语言对比)
注释
一、数据类型
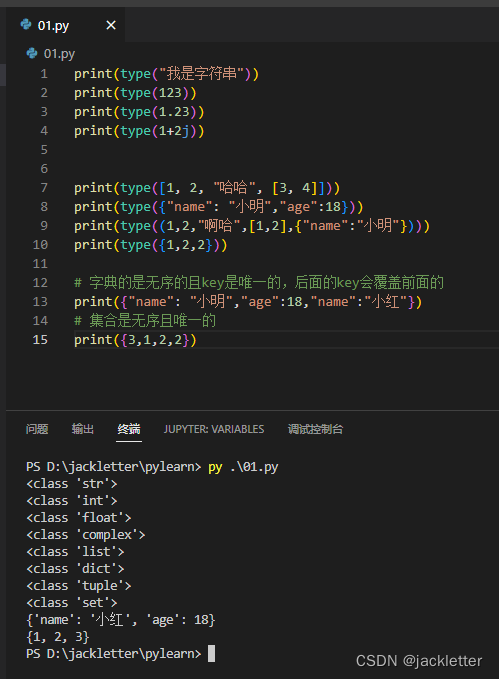
基础六大数据类型,可以使用 type()查看,如下图:
1.1 数字(Number)
支持
- 整数(int)
- 浮点数(float)
- 复数(complex),如:4+3j,以j结尾表示复数
- 布尔(bool)True用1表示,False用0表示,反之,1表示True,其他表示False
1.2 字符串(String)
1.3 列表(List)
有序的可变列表
1.4 元组(Tuple)
有序的不可变序列,可有序记录一堆不可变的Python数据集合
1.5 集合(Set)
无序不重复结合
可无序记录一堆不重复的Python数据集合
1.6 字典(Dictionary)
无序Key-Value集合
可无序记录一堆Key-Value型的Python数据集合
1.7 数据类型转换
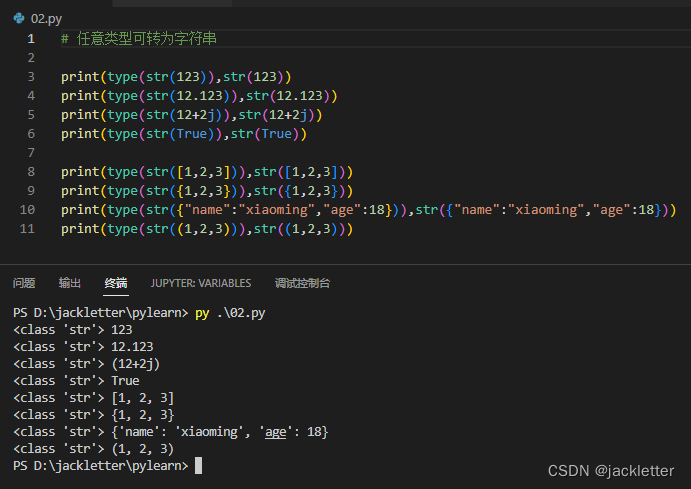
可以将任意类型转为字符串,如:数字/字符串/列表/元组/集合/字典 => 字符串,如下图:
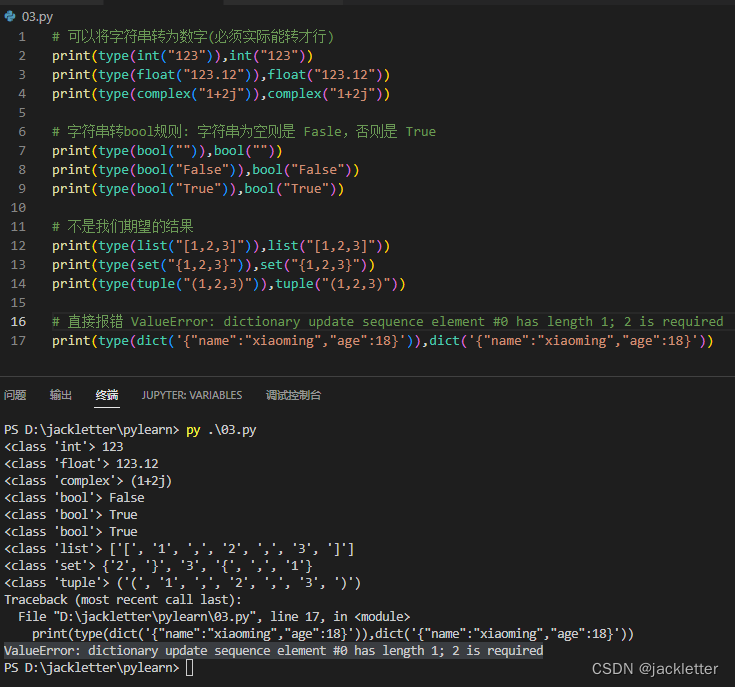
但字符串并不能转到任意其他类型,因为字符串本质是一个字符列表,下面看转换的效果:
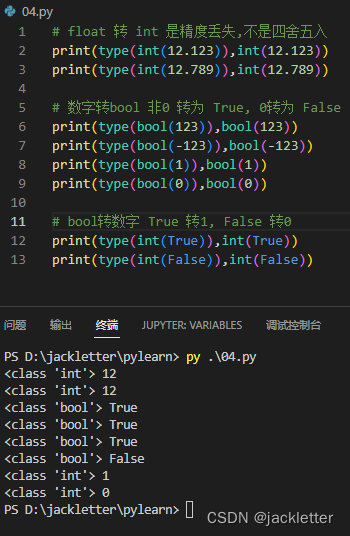
其他的转换,如:int <=>float吗,需要注意:float转int会有精度丢失(注意是精度丢失,不是四舍五入),看下图:
二、变量
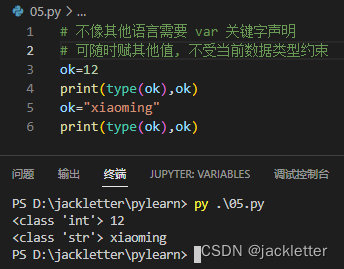
python是脚本语言,弱类型,所以一个变量可以随便赋其他的值,甚至变更数据类型,这点和javascript类似。
另外,python中不用定义变量,直接使用即可,如下:
三、运算符
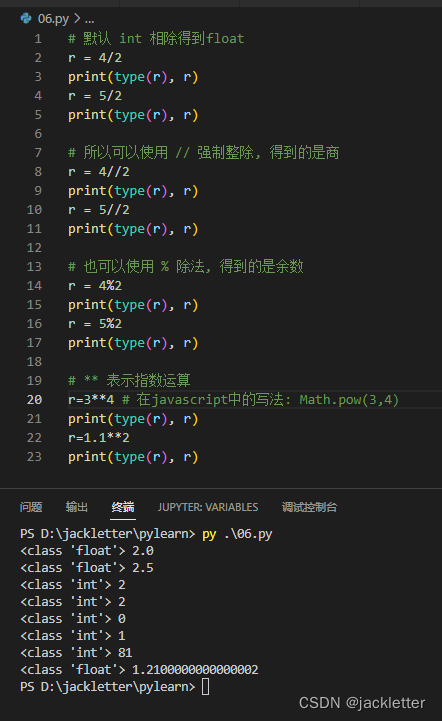
常见运算符 :+ 加法,- 减法,* 乘法,/ 除法,// 整除,% 取余,**指数
下面列出重点关注的几项:
四、字符串扩展
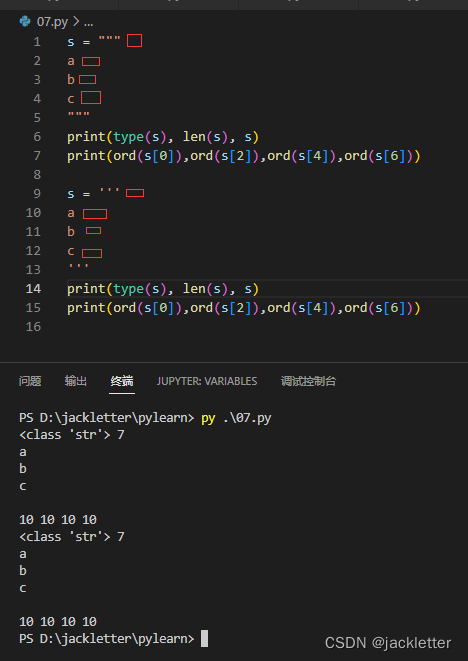
4.1 定义的三种方式:
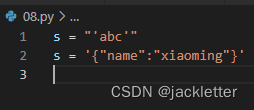
- 使用单引号
' abc' - 使用双引号
"abc" - 使用
"""abc"""或'''abc'''
特点总结:
- 单引号和双引号的作用类似,支持这两种方式就给了我们不写转移字符的可能 \,如:
- 使用
"""abc"""或'''abc''',就可以让我们省去表示换行符合\的苦恼,看下面对比效果:
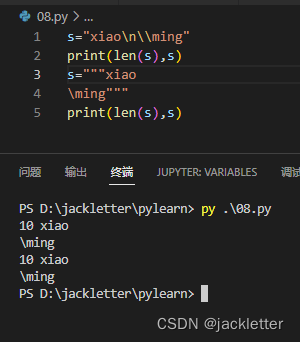
另外,我们需要注意,"""abc"""和'''abc'''的开头和结尾不想有换行的话,要紧贴这写,否则会产生换行符,如下:
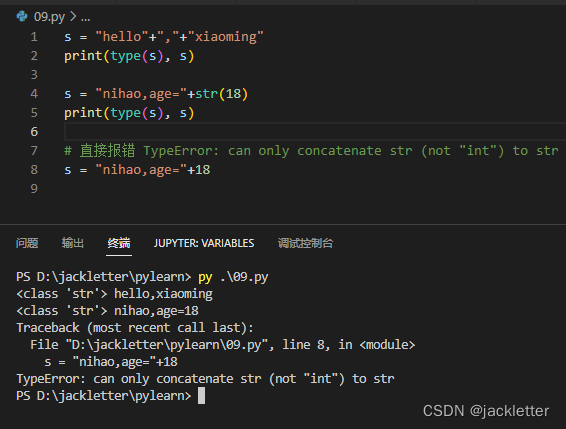
4.2 字符串的拼接
使用 + 可进行拼接,但不同于其他语言,我们不能将字符串和其他类型(如:int)进行相加,如下:
javascript是允许的,这点得注意下:
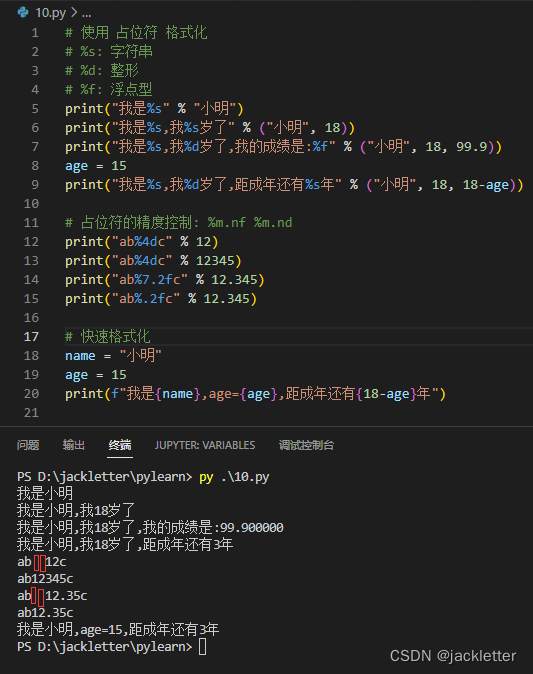
4.3 字符串格式化
上面使用+对字符串拼接简单的还行,当相加内容很多的话就不易读了,而且还不支持其他数据类型(比如: int/float)自动转字符串,所以就有了下面两种字符串格式化方法:
- %d, %f, %s:类似c语言
- f"{exp}{exp2}"
下面是效果:
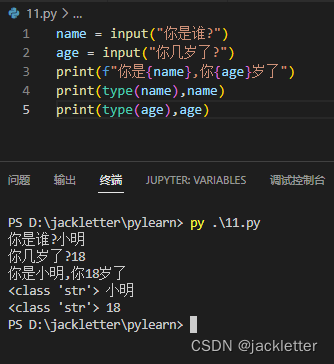
五、交互式输入
可以使用input(prompt)获取用户控制台的输入,回车后,用户输入的字符串就传到了程序中,如下:
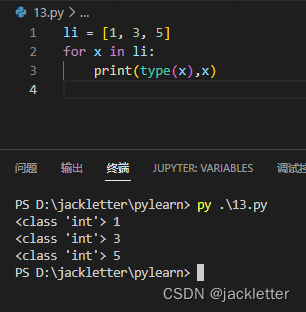
六、for循环和range
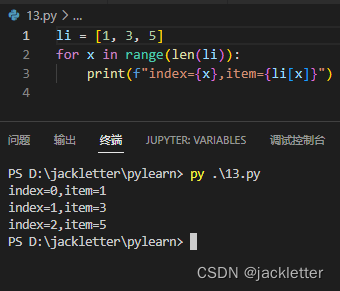
python中的for循环没有 for(int x=0;x<10;x++)这种格式,只有: for x in li:这种,如下:
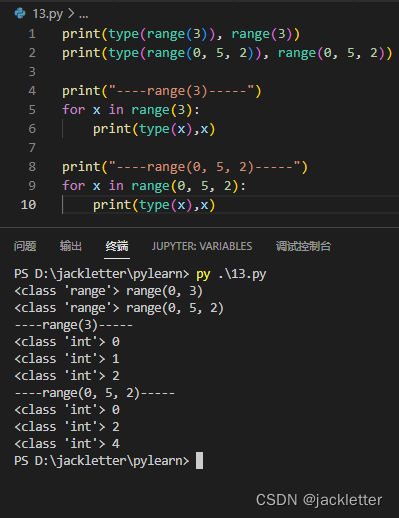
这种方式,是没办法这循环体中获取当前进度的,但我们可以借助range
range函数本身是生成一个范围,格式为:range(start,end,step) 注意:包含start,不包含end,看下面的示例:
那么,组合range和for循环如下:
七、函数
7.1 简单函数
直接看下面的使用示例:
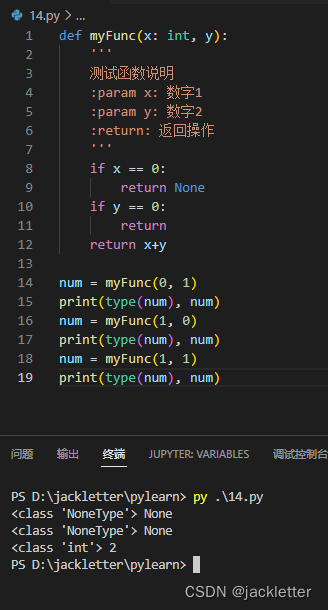
返回的None可以用于if判断中,表示False
return和return None 是一样的。
7.2 函数中的参数和返回值
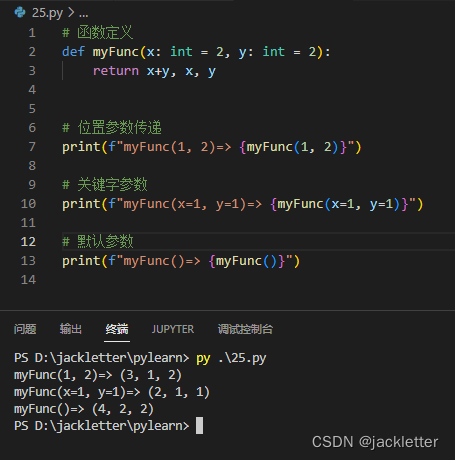
另外,python中的函数还有一些特点,如:
- 支持返回多个值
- 支持默认参数、关键字参数、不定长参数(*和**)
直接看示例:
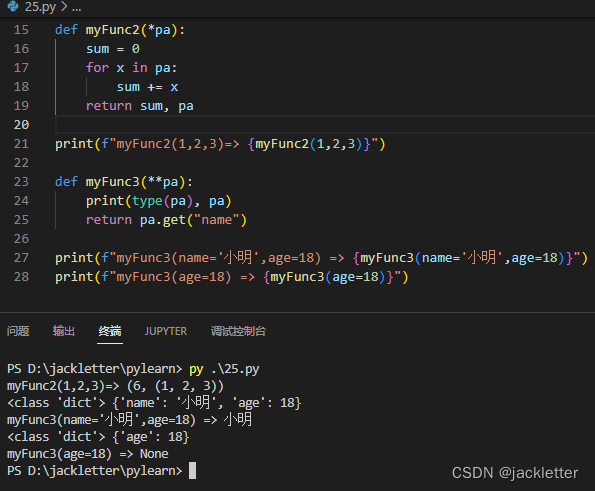
不定长参数示例:
7.3 函数做参数/匿名函数/lambda函数
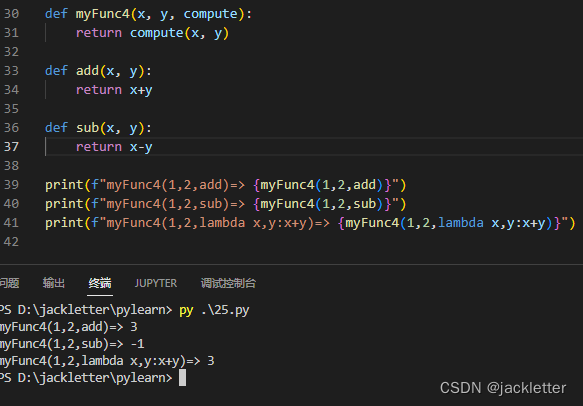
八、容器之列表
8.1 概念和操作
python中的list类似javascript中的数组, c#中的list,常见操作如下:
- 获取列表长度:
len(li) - 获取指定索引元素:
li[index] - 遍历:
for x in li: - 获取值所在索引:
li.index(ele) - 插入:
li.insert(index,ele) - 追加:
li.apped(ele) - 追加另一个容器:
li.extend(li2) - 移除指定元素:
li.remove(ele) - 根据下标移除:
dele li[index] - 从末尾弹出:
delEle=li.pop() - 清空列表:
li.clear() - 统计列表中某个元素的数量:
li.count(ele) - 列表排序:
li.sort(key=lambda: x: x"age"], reverse=True)
看下面的示例:
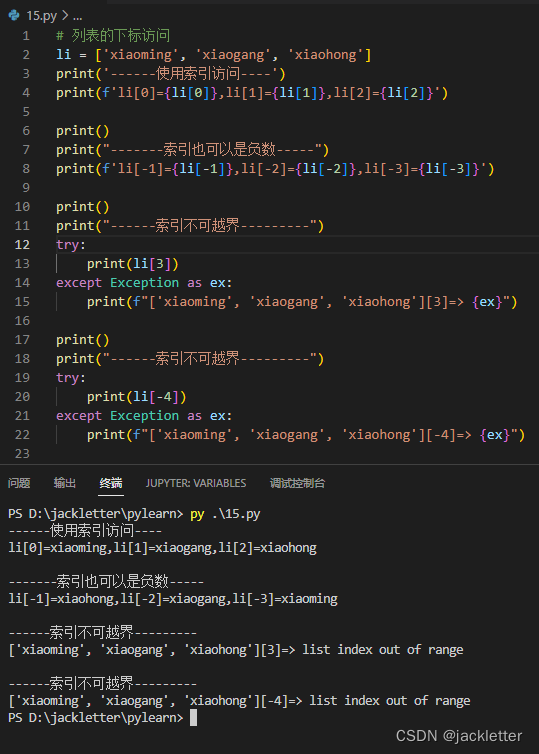
8.2 通过下标访问列表
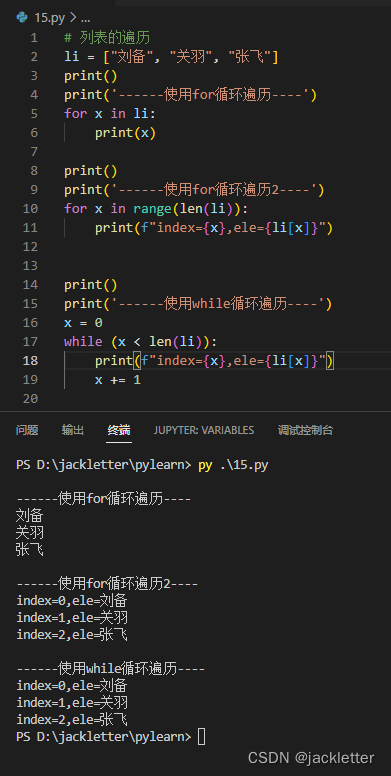
8.3 循环遍历列表
8.4 常见函数用法(增删改查、排序、统计)
# 插入到指定位置
print()
print("------li.insert()-------")
li = ["刘备", "关羽", "张飞"]
li.insert(0, '曹操')
print(f'["刘备", "关羽", "张飞"].insert(0,"曹操")=> {li}')# 追加元素
print()
print("--------append()------")
li = ["刘备", "关羽", "张飞"]
li.append("孔明")
print(f'["刘备", "关羽", "张飞"].append("孔明")=> {li}')# 追加另一个容器
print()
print("--------extend()------")
li = ["刘备", "关羽", "张飞"]
li.extend(["孙策", "孙权"])
print(f'["刘备", "关羽", "张飞"].append(["孙策", "孙权"])=> {li}')# 移除指定元素
print()
print("--------remove(): 只移除第一个------")
li = ["刘备", "关羽", "张飞", "关羽"]
li.remove('关羽')
print(f'["刘备", "关羽", "张飞","关羽"].remove("关羽")=> {li}')# 根据下标移除
print()
print("--------del list[index]: 根据下标移除------")
li = ["刘备", "关羽", "张飞"]
del li[1]
print(f'["刘备", "关羽", "张飞"] del li[1]=> {li}')# 从末尾移除一个
print()
print("--------pop(): 从末尾弹出一个------")
li = ["刘备", "关羽", "张飞"]
ele = li.pop()
print(f'["刘备", "关羽", "张飞"].pop()=> {li}, ele={ele}')# 清空列表
print()
print("--------clear(): 清空列表------")
li = ["刘备", "关羽", "张飞"]
li.clear()
print(f'["刘备", "关羽", "张飞"].clear()=> {li}')# 获取列表长度
print()
print("--------len(li): 获取列表长度------")
li = ["刘备", "关羽", "张飞"]
count = len(li)
print(f'len(["刘备", "关羽", "张飞"])=> {count}')# 统计列表元素数量
print()
print("--------count(ele): 统计列表某个元素数量------")
li = ["刘备", "关羽", "张飞", "关羽"]
count = li.count("关羽")
print(f'["刘备", "关羽", "张飞","关羽"].count("关羽")=> {count}')# 列表排序
print()
print("--------sort(): 列表排序------")
li = ["a", "c", "b"]
li.sort()
print(f'["a","c","b"].sort()=> {li}')
li = ["a", "c", "b"]
li.sort(reverse=True)
print(f'["a","c","b"].sort(reverse=True)=> {li}')
li = [{"name": "小明", "age": 18},{"name": "小花", "age": 16},{"name": "小刚", "age": 20}]
li.sort(key=lambda x: x["age"], reverse=True)
print(f'[dict1,dict2,dict3].sort(key=lambda x: x["age"])=> {li}')""" 输出如下:
PS D:\jackletter\pylearn> py .\15.py------li.insert()-------
["刘备", "关羽", "张飞"].insert(0,"曹操")=> ['曹操', '刘备', '关羽', '张飞']--------append()------
["刘备", "关羽", "张飞"].append("孔明")=> ['刘备', '关羽', '张飞', '孔明']--------extend()------
["刘备", "关羽", "张飞"].append(["孙策", "孙权"])=> ['刘备', '关羽', '张飞', '孙策', '孙权']--------remove(): 只移除第一个------
["刘备", "关羽", "张飞","关羽"].remove("关羽")=> ['刘备', '张飞', '关羽']--------del list[index]: 根据下标移除------
["刘备", "关羽", "张飞"] del li[1]=> ['刘备', '张飞']--------pop(): 从末尾弹出一个------
["刘备", "关羽", "张飞"].pop()=> ['刘备', '关羽'], ele=张飞--------clear(): 清空列表------
["刘备", "关羽", "张飞"].clear()=> []--------len(li): 获取列表长度------
len(["刘备", "关羽", "张飞"])=> 3--------count(ele): 统计列表某个元素数量------
["刘备", "关羽", "张飞","关羽"].count("关羽")=> 2--------sort(): 列表排序------
["a","c","b"].sort()=> ['a', 'b', 'c']
["a","c","b"].sort(reverse=True)=> ['c', 'b', 'a']
[dict1,dict2,dict3].sort(key=lambda x: x["age"])=> [{'name': '小刚', 'age': 20}, {'name': '小明', 'age': 18}, {'name': '小花', 'age': 16}]
PS D:\jackletter\pylearn>
"""
九、容器之元组
python中除了list还有tuple,元组是只读的,所以没有增删改等操作。
直接看下面:
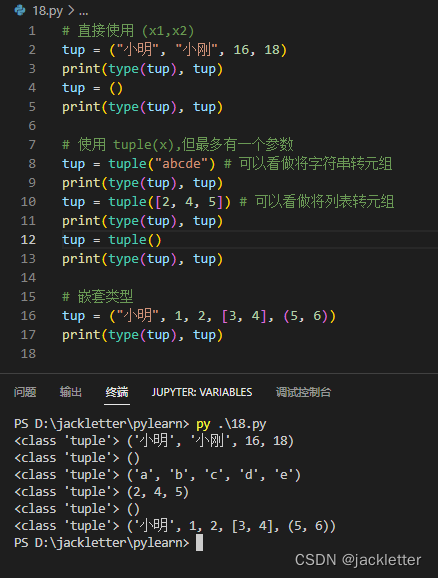
9.1 元组的定义
9.2 元组的访问和遍历
因为元组是按顺序存储,所以支持按照索引访问,同时支持for循环,如下:
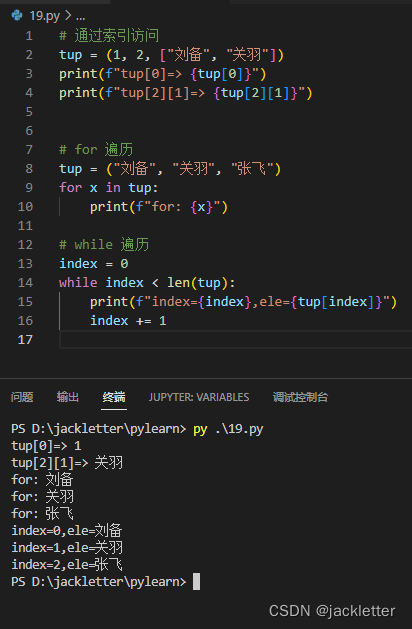
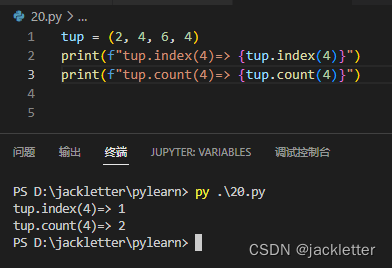
9.3 元组函数 index 和 count
这个和list的用法类似,如下:
十、容器之字符串
字符串可以看做是字符的只读容器,类似list
10.1 字符串的下标访问和遍历
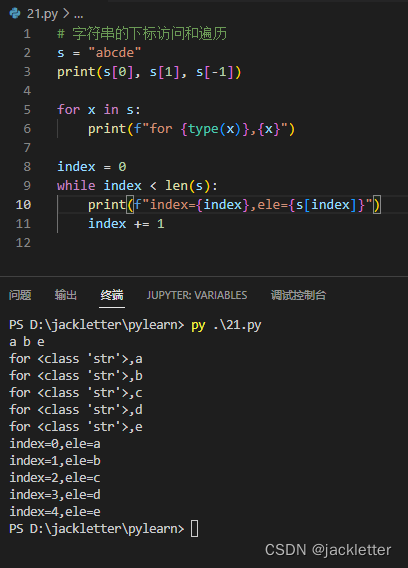
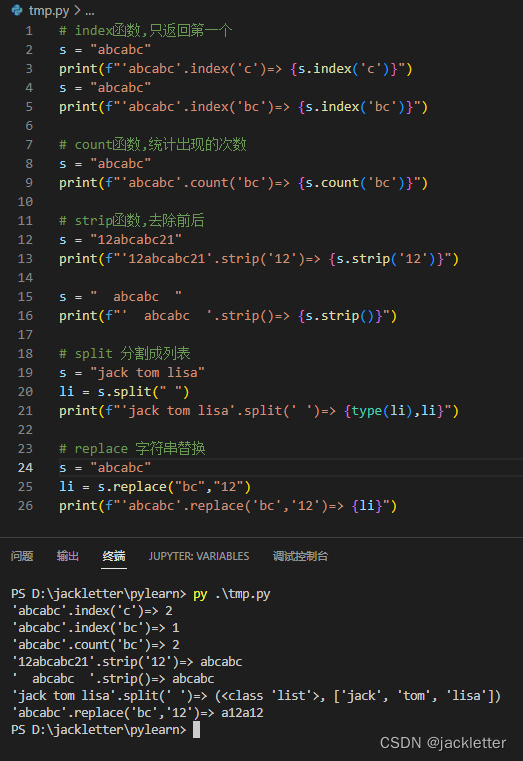
10.1 常见函数
十一、容器(序列)的切片
列表(list)、元组(tuple)、字符串(str) 这三个都是序列,它们支持切片操作。
切片的语法为:seq[start:end:step],其中,start/end/step的默认值分别为:0/len(seq)/1
下面以列表为例,看下它的效果: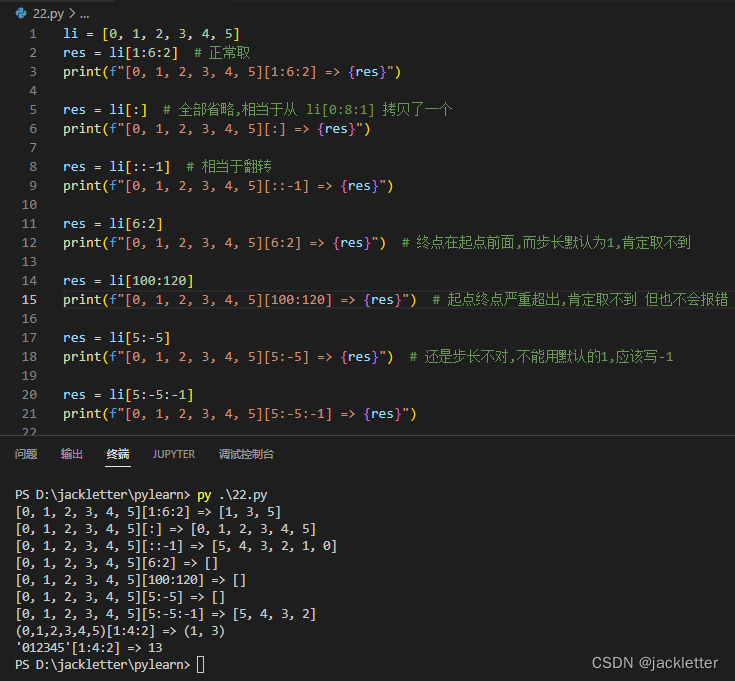
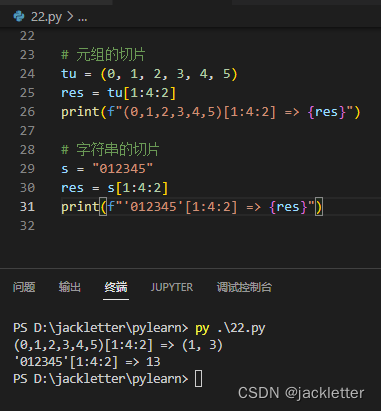
对元组和字符串也是一样的,如下:
十二、容器之集合
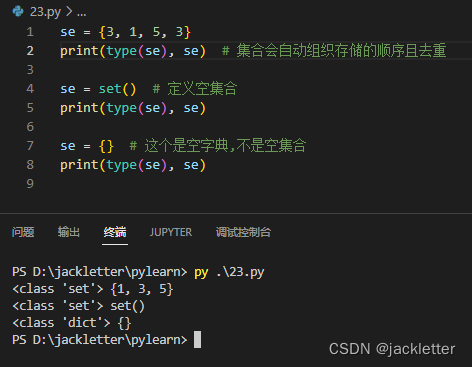
集合相对于列表、元组、字符串的特点是:无序且唯一。
因为无序自然不能用下标访问,也不能用于切片。
唯一是集合自动去重的。
12.1 集合的定义
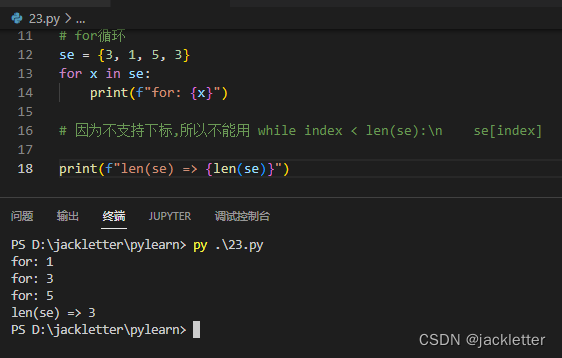
12.2 集合的遍历
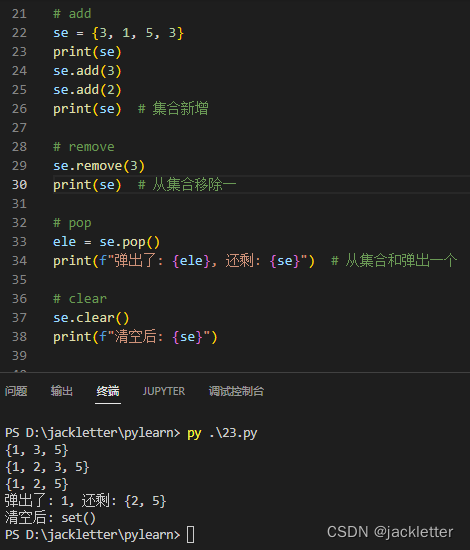
12.3 集合的常见操作
- 添加
se.add(ele) - 移除/弹出
se.remove(ele)/ele = se.pop() - 清空
se.clear()
如下图:
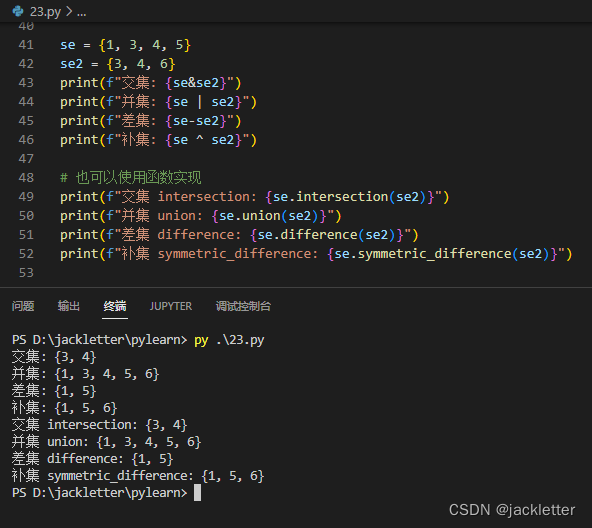
还有集合运算
- 求交集
se & se2 - 求并集
se | se2 - 求差集
se - se2 - 求补集
se ^ se2
如下图:
还有集合运算后将结果覆盖第一个集合的,如:
se.intersection_update(se2)
se.difference_update(se2)
不再实验
十三、容器之字典
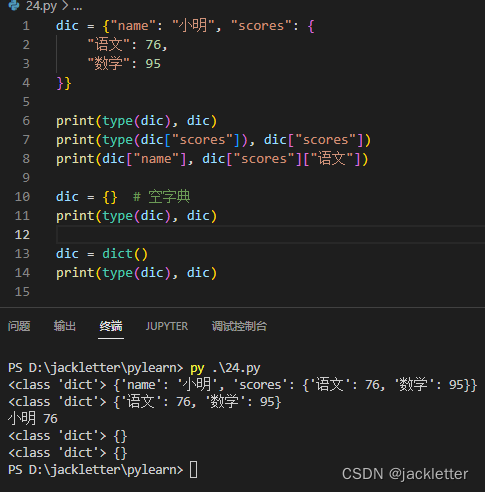
python中的字典和javascript的对象一个意思,直接看下面的示例:
字典的定义:
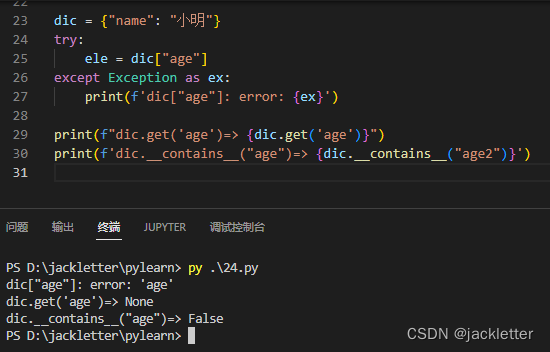
注意:我们如果 dic[key] 如果不存在的话会报错,但我们可以使用 dic.get(key),当然我们也可以使用__contains__去判断,如下:
字典的遍历:
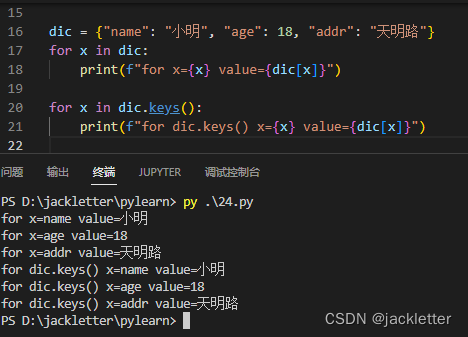
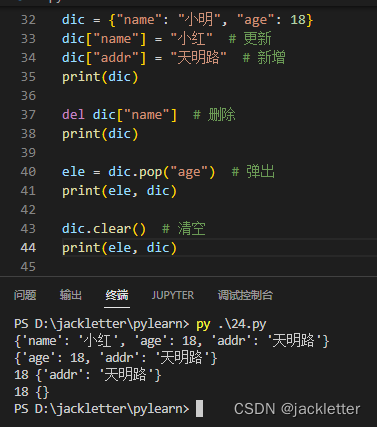
字典改数据:
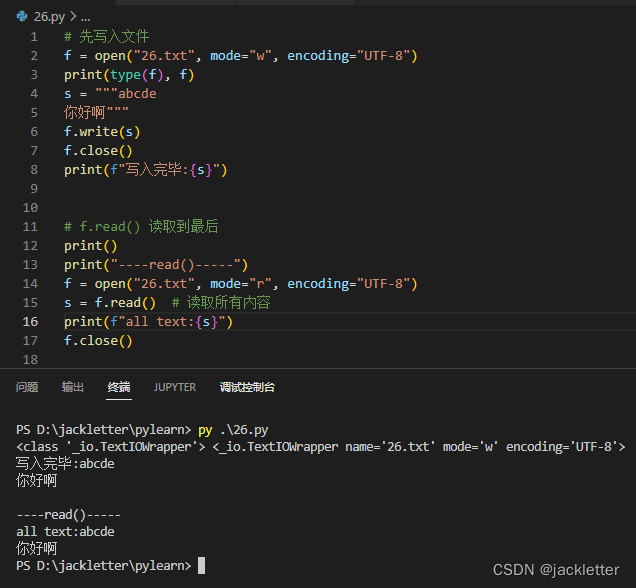
十四、文件操作
文件模式:
r 只读
w:存在则覆盖,不存在则新建
a:存在则追加,不存在则新建追加
简单的写入和读写示例:
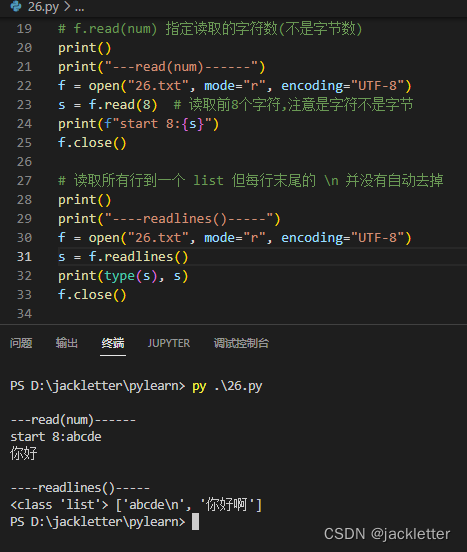
我们也可以指定读取的字符数(注意:不是字节数)或读取一行,如下(还是用上面创建的txt):
我们也可以使用for循环读取,另外,我们可以使用with关键字以防止忘记写close()
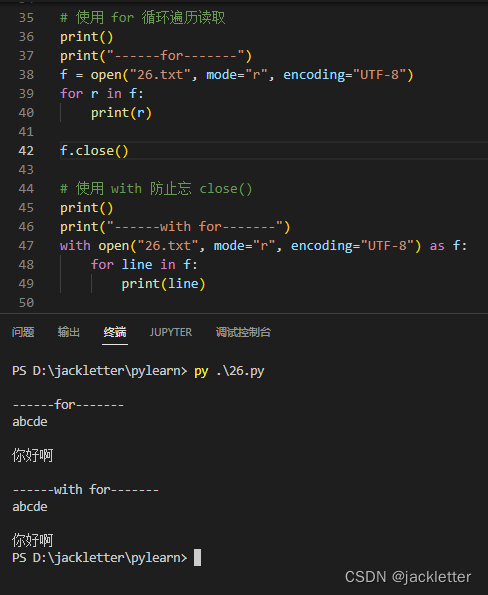
十五、异常
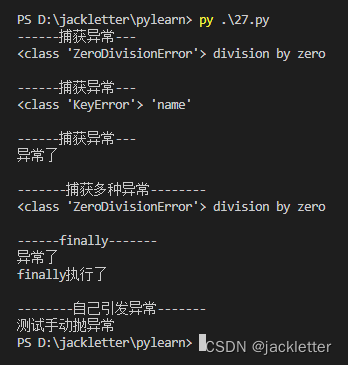
直接看下面的示例:
print("------捕获异常---")
try:i = 5/0
except Exception as ex:print(type(ex), ex)print()
print("------捕获异常---")
try:dic = {"age": 18}i = dic["name"]
except Exception as ex:print(type(ex), ex)print()
print("------捕获异常---")
try:i = 5/0
except:print("异常了")print()
print("-------捕获多种异常--------")
try:i = 5/0
except (KeyError, ZeroDivisionError) as ex:print(type(ex), ex)print()
print("------finally-------")
try:i = 5/0
except:print("异常了")
finally:print("finally执行了")print()
print("--------自己引发异常-------")
try:raise Exception("测试手动抛异常")
except Exception as ex:print(ex)
输出如下:
十六、模块和包
概念:在python中简单理解,一个文件就是一个模块
导入模块的语法:
[from 模块名] import [ 模块 | 类 | 变量 | 函数 | * ] [as 别名]
常用形式:
import 模块名from 模块名 import 类、变量、方法等from 模块名 import *import 模块名 as 别名from 模块名 import 功能名 as 别名
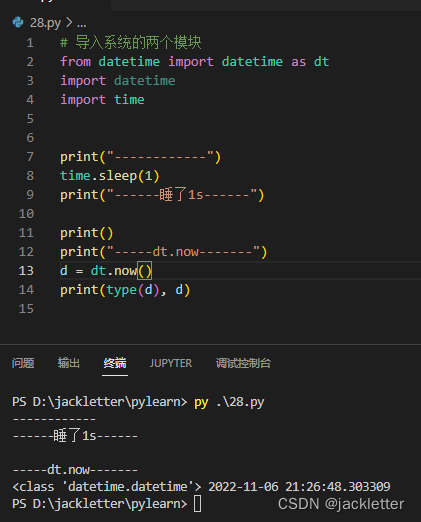
看一个简单的示例(导入系统提供的):
16.1 自定义模块
我们可以自定义模块,然后导入,如下:
# 路径: /cc/c_28.py# 默认定义的都可以被导出, 可以使用 __all__指定仅导出哪些,但仅限定在 import *
__all__ = ["funcSub"]def funcSub(x, y):return x-yprint()
print("-------------")
print(f"__file__:{__file__}")
print(f"__name__:{__name__}")
if (__name__ == "__main__"):print(f"直接运行脚本: {__file__}")
else:print(f"导入了脚本: {__file__}")
# 路径: /pp/test.py
import sys
import os
sys.path.append(os.path.join(os.path.dirname(__file__), '..'))from cc.c_28 import funcSubprint()
print("-----------")
print(f"funcSub(1, 2)=>{funcSub(1, 2)}")
运行如下:
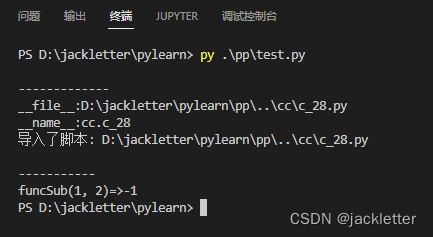
上面有几点需要注意下:
__name__可以用来判断当前模块是被导入的还是直接运行的__all__可以用来限制导入时(import *) 只能导入指定的模块(注意,只有在 import * 时有效)- 可以使用
sys.path.append(xx)将指定的路径加入到模块搜索中去
16.2 包和自定义包
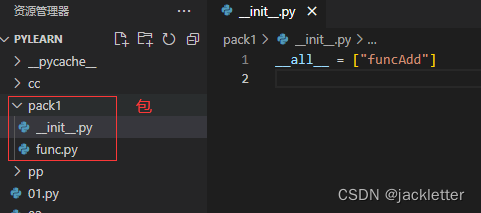
在python中包其实就是一个文件夹,里面可以放许多的模块(代码文件),通过包进行归类,方便管理。
但python包和普通文件夹又有区别:包下面有一个 __init__.py 文件来标识这是一个包,通常会在这个文件中使用`all``来限制导出的内容。
如:
十七、pip和国内源
参考:《python配置国内镜像源操作步骤》
类似 java中的maven,javascript中的npm,python中也有pip管理包的程序。
我们可以通过它方便的引用三方包,如下:
我们可以先通过命令查看配置:
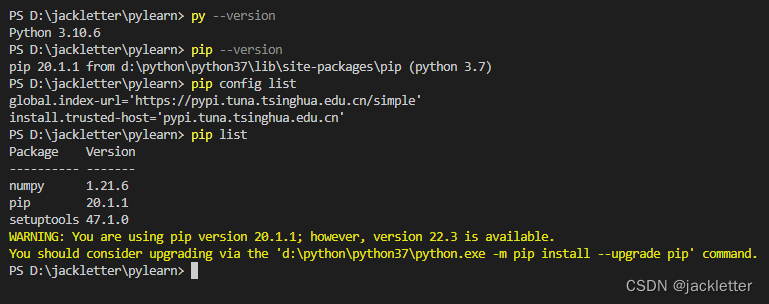
来解释下:
-
pip config list显示所有的配置,当前已设置了国内源,如果没有的话可以参考:
pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple
pip config set install.trusted-host='pypi.tuna.tsinghua.edu.cn'其他常用的源还有:
1、华南理工大学镜像源
http://pypi.hustunique.com/simple/%29
2、清华大学
https://pypi.tuna.tsinghua.edu.cn/simple
3、豆瓣
http://pypi.douban.com/simple/
4、清华大学开源镜像站
https://mirrors.tuna.tsinghua.edu.cn/
5、网易开源
http://mirrors.163.com/
6、华为
https://mirrors.huaweicloud.com/
7、阿里巴巴
https://opsx.alibaba.com/mirror/ -
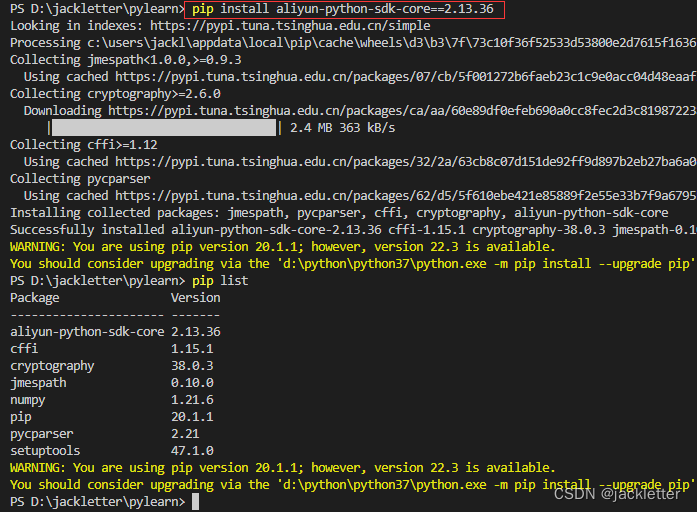
pip list显示当前安装的三方包
可以看到,当前我安装了一个numpy,另外两个是自带的,安装命令为:
pip install aliyun-python-sdk-core==2.13.36(也可以不指定版本)
如下:
十八、虚拟环境
18.1 概念
python 和 java、c#这种语言不一样:
java和c#都是静态语言,安装的都是别人编译好的包,它们可以将一个包的各个版本缓存起来,然后加入到项目的引用即可;- 而
python是解释性语言,安装的都是源码,没有将包的某个版本加入到项目引用这种说法,所以管理起来就麻烦很多;
javascript也是解释性语言,它也有同样的问题,不过npm是将本项目引用的包都放在node_moudules文件夹下面。缺点就是每个新项目都得重新下,即使我们用的是xxxx包的同一个版本。
python为了解决这个问题,提出了虚拟环境的概念,就是将python拷贝一份作为新的环境,这样我们在新的环境里安装包不会影响其他环境里的,做到了隔离。比如:
- 我们在环境A里导入了xxxx包的1.0版本,在环境B里导入了xxxx包的2.0版本。它们互不影响;
- 项目A和项目B使用环境A,因为它们都会导入相同版本的包,项目C和项目D使用环境B,因为它们也会使用相同环境的包;
18.2 创建和使用虚拟环境
我们先选择一个目录,如 D:\jackletter\my-venv,然后执行如下:py -m venv my-venv
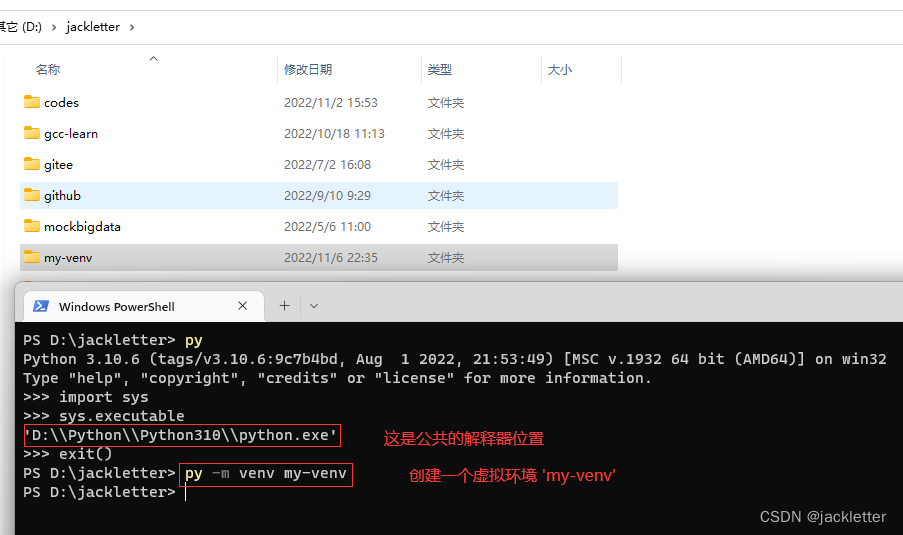
执行完成后,看看里面的东西:
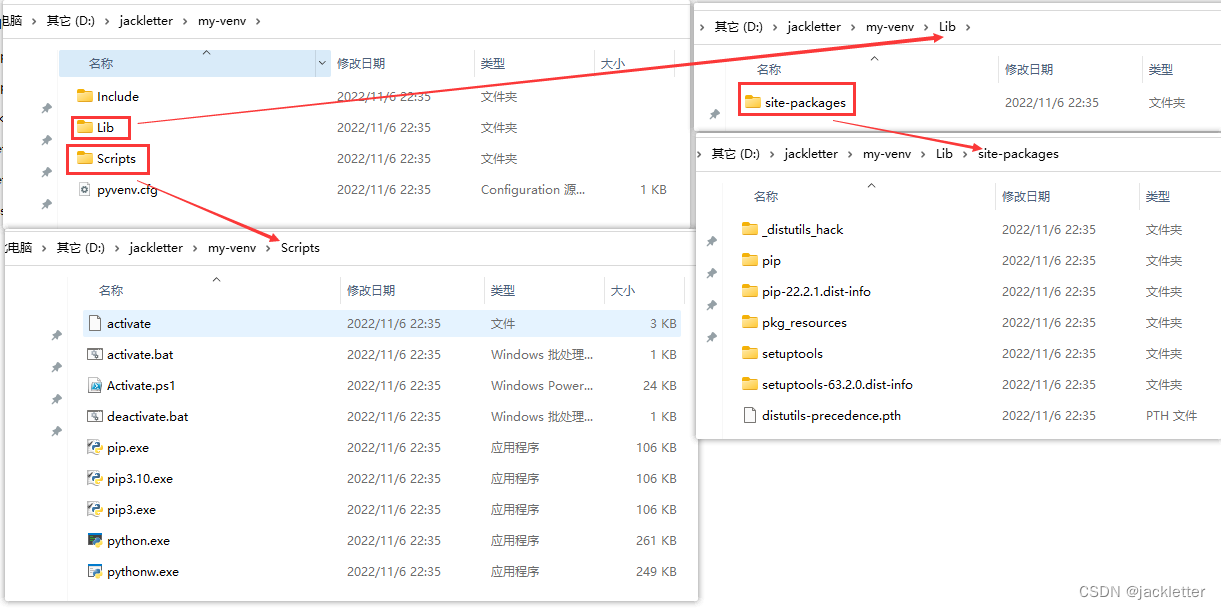
我们需要激活这个环境,如下:
.\Scripts\Activate.ps1
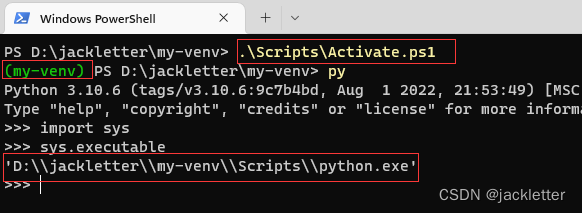
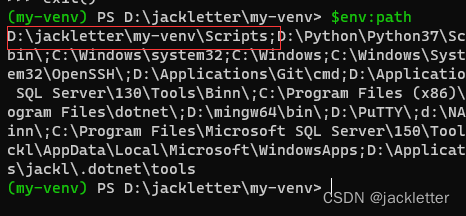
其实激活就是将my-venv的路径配置到path里面,如下:
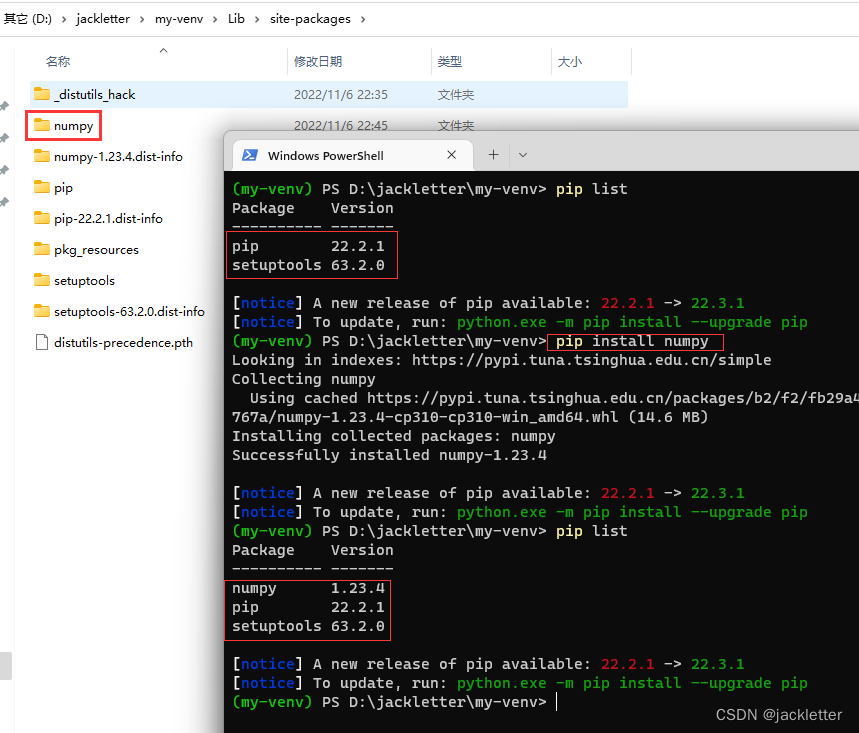
在虚拟环境里,我们安装的包都在 my-venv\Lib\site-packages下,如下:
退出虚拟环境的命令是:.\Scripts\deactivate.bat,不过在powershell中不好用。。。但在cmd里是可以的。。。