HashMap的面试题
目录
1、底层数据结构 1.7和1.8有何不同
2、为什么用红黑树,为何不一上来就树化,树化阈值为何是8,何时会树化,何时会退化为链表
3、索引如何计算?hashCode都有了,为何还要提供hash()方法?数组容量为何是2的n次幂
4、HashMap的put方法流程 1.7和1.8有何不同
5、加载因子为何默认是0.75
6、多线程下操作HashMap(线程不安全的)会有什么问题
7、key是否能为null,作为key的对象有什么要求?
8、String对象的hashCode()如何设计的,为啥每次乘的是31
1、底层数据结构 1.7和1.8有何不同
1.7 数组+链表
1.8 数组+链表+红黑树
2、为什么用红黑树,为何不一上来就树化,树化阈值为何是8,何时会树化,何时会退化为链表
① 红黑树是用来避免DOS攻击,防止链表超长时性能下降,树化应该是偶然情况 1.hash表的查询,时间复杂度是O(1),而红黑树的查找,时间复杂度是O(log2(n)),并且树化占用的空间也普遍比链表大,如非必要,尽量还是使用链表 2.hash值如果只够水机,则在hash表内按照泊松分布,在负载因子是0.75的情况下,长度超过8的链表出现的概率是0.00000006,选择8就是为了让树化的几率足够小
② 树化的两个条件 链表长度大于8 数组容量大于等于64
③ 退化链表的两种情况 1.在扩容的时候,如果拆分树时,树元素个数<=6 则会退化链表(如果是7的话,会频繁进行红黑树和链表的转换,影响性能,所以退了一位,使得不那么容易变回红黑树) 2.remove树结点的时候,如果root,root.left,root.right,root.left.left有一个为null,也会退化为链表
3、索引如何计算?hashCode都有了,为何还要提供hash()方法?数组容量为何是2的n次幂
① 首先计算对象的hashCode(),在调用HashMap的hash()方法进行二次哈希,最后 &(capacity-1)得到索引
// key就是hashCode()的值public V put(K key, V value) {return putVal(hash(key), key, value, false, true);}//hash(key) 是进行二次哈希static final int hash(Object key) {int h;return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);}// n是capacity 数组容量 hahs是二次哈希得到的值p = tab[i = (n - 1) & hash]② 二次哈希 hash() 是为了综合高位数据,让哈希分布更均匀,防止哈希冲突,使得计算索引的时候,出现相同的概率降低防止出现链表过长的情况
1. HashMap容量较小而hash值比较大的时候,哈希冲突容易变多2. 假设容量为16,那么二进制(0000 1111)进行按位与操作,hash值的高28位不会参与(因为0000 1111前的28位都是0,32位,其中4位符号),所以哈希冲突就会变多3. 进行右移获取的hash值就会让二进制的高位尽可能多地参与按位与操作,从而减少哈希冲突
③ 计算索引的时候 如果是2的n次幂
好处
1.可以使用位运算代替求模运行
(求索引位置是 hash&容量 变成(容量-1)& hash), 因为 &的效率是大于/
2.扩容的时候hash& oldCap == 0 元素就留在原来位置
否则新位置= 旧位置 + oldCap
//扩容的方法中 resize()中 每次都判断
if (oldTab != null) {for (int j = 0; j < oldCap; ++j) {else { // preserve order //维持排序Node loHead = null, loTail = null;Node hiHead = null, hiTail = null;Node next;do {next = e.next;//判断hash& oldCap == 0if ((e.hash & oldCap) == 0) {if (loTail == null)loHead = e;elseloTail.next = e;loTail = e;}//否则else {if (hiTail == null)hiHead = e;elsehiTail.next = e;hiTail = e;}} while ((e = next) != null);//hash& oldCap == 0 loTail 不等于空//保持原来位置if (loTail != null) {loTail.next = null;newTab[j] = loHead;}//否则hiTail 不等于空 新位置 = 原来位置+oldCap(原来的容量)if (hiTail != null) {hiTail.next = null;newTab[j + oldCap] = hiHead;}}}}} 缺点
当例如都是偶数的时候,在如何摸容量 都索引位置都不是奇数,造成哈希表分布性不好
因此 如果追求性能就使用2的n次幂 如果追求哈希表的分布性就使用质数容量
①②③都是配合容量为2的n次幂的优化手段,但是并不能说那种设计更优,应该是设计者综合了各种因素,最终选择了2的n次幂作为容量(HashTable就是不是2的n次幂 扩容长度原来二倍+1)
4、HashMap的put方法流程 1.7和1.8有何不同
-
HashMap是懒惰创建数组的,首次使用put方法才创建数组(创建对象的时候数组是为空的)
-
计算索引(桶下标)
-
如果桶的下标还没人占用,创建Node占位返回
-
如果桶下标已经有人占用了
-
已经是红黑树走红黑树的添加或者更新逻辑
-
普通的链表,走链表的添加或者更新逻辑,如果链表长度超过树化的阈值(8) ,数组容量大于等于64就进行树化逻辑
-
其中添加和更新逻辑,是看equals是否相等,相等就是更新逻辑,不相等就是添加逻辑
-
-
返回前检查容量是否超过阈值(容量*0.75),一旦超过进行扩容
-
不同
-
链表的插入节点,1.7是头插法,1.8是尾插法
-
1.7是大于等于阈值且没有空位(就是计算的索引位置有元素)的时候才扩容,而1.8是大于阈值就扩容
-
1.8扩容计算Node索引的时候,会优化
-
5、加载因子为何默认是0.75
-
在空间占用与查询时间之间取得较好的权衡
-
大于这个值,空间节省了,但是链表长度就会比较长影响性能
-
小于这个值,冲突减少了,但是扩容就会更加频繁,空间占用多
6、多线程下操作HashMap(线程不安全的)会有什么问题
①扩容死链(1.7)
多线程的情况会出现这种死链的情况
数组是固定长度,链表太长就需要扩充数组长度进行rehash减少链表长度。如果两个线程同时触发扩容,在移动节点时会导致一个链表中的2个节点相互引用,从而生成环链表
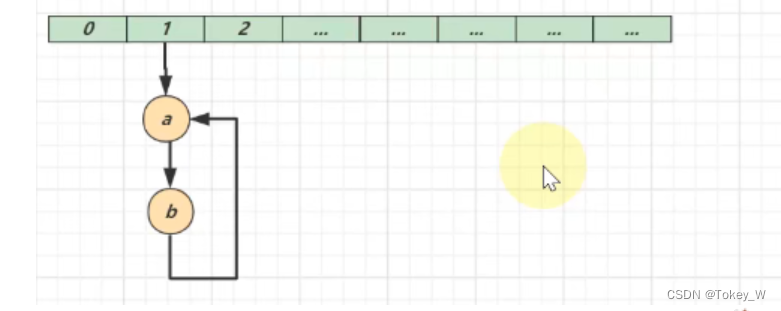
②数据错乱(1.7 1.8)
当进行添加的时候

线程1添加 a 取得索引为1 线程2添加1 取得索引也为1
例如线程1 进入到630行 执行为null,准备执行631的时候
线程2 进入630行执行也为null 执行631行,结束后 数组索引为1的位置元素为1
然后线程1这个时候已经if 判断完毕了,也执行631行,这个时候就将a放入到数组索引为1的位置
最终出现数据的丢失问题
7、key是否能为null,作为key的对象有什么要求?
-
HashMap的key可以为null,但是Map的其他实现则不然,会出现空指针异常
-
作为key对象,必须实现hashCode和equals ,并且key的内容不能修改(不可变)
否则修改后hashCode改变了,索引位置改变了,就会出现不同的情况
8、String对象的hashCode()如何设计的,为啥每次乘的是31
public int hashCode() {int var1 = this.hash;if (var1 == 0 && this.value.length > 0) {char[] var2 = this.value;for(int var3 = 0; var3 < this.value.length; ++var3) {var1 = 31 * var1 + var2[var3];}this.hash = var1;}return var1;}