MYSQL索引查询问题质疑
前言
我们在写mysql查询语句的时候,尤其是经验不足的同学肯定会想要怎么使用索引加快查询,或是我这样写到底会不会命中索引。那么现在我就列举几个常见的索引查询问题进行简单说明一下。(欢迎互怼!)
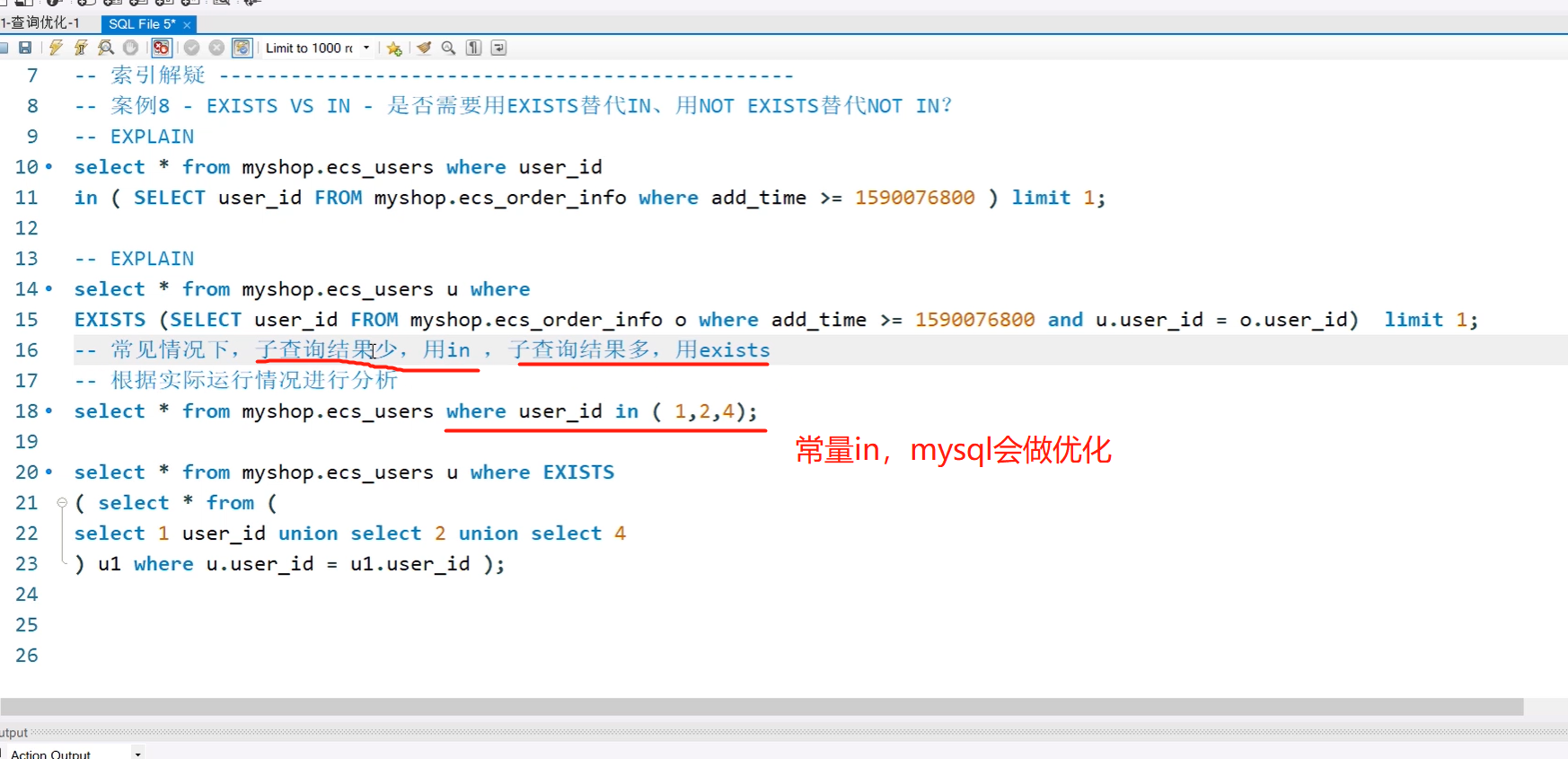
1.问:使用like会不会走索引
答:使用like走索引,只是模糊查%不能位于左边,这样索引表不知道你现在要查什么数据
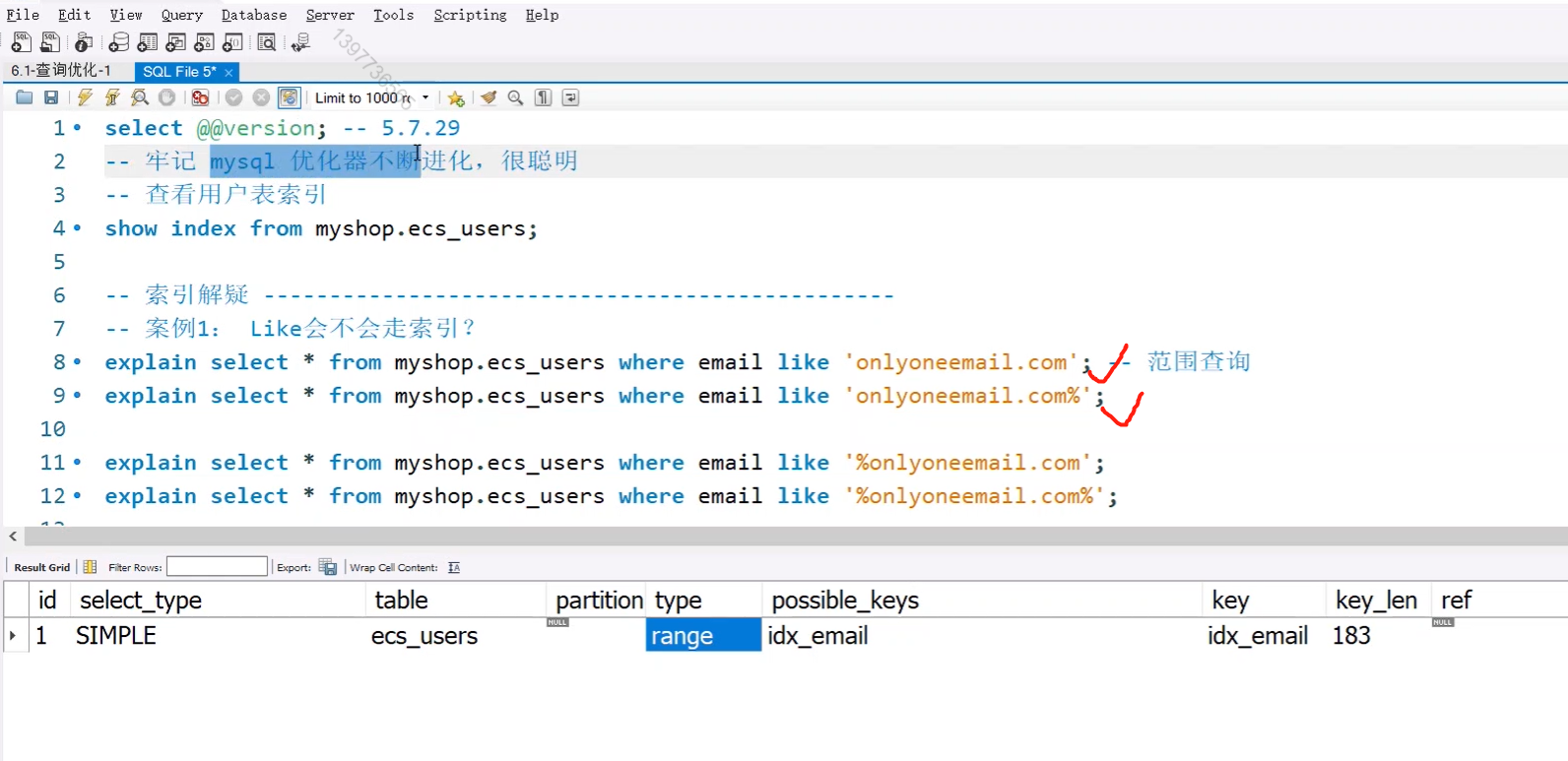
2.问:索引列能不能为空
答:使用 is not null不走索引,并且如果索引列大量数据为空,也没必要建立索引。
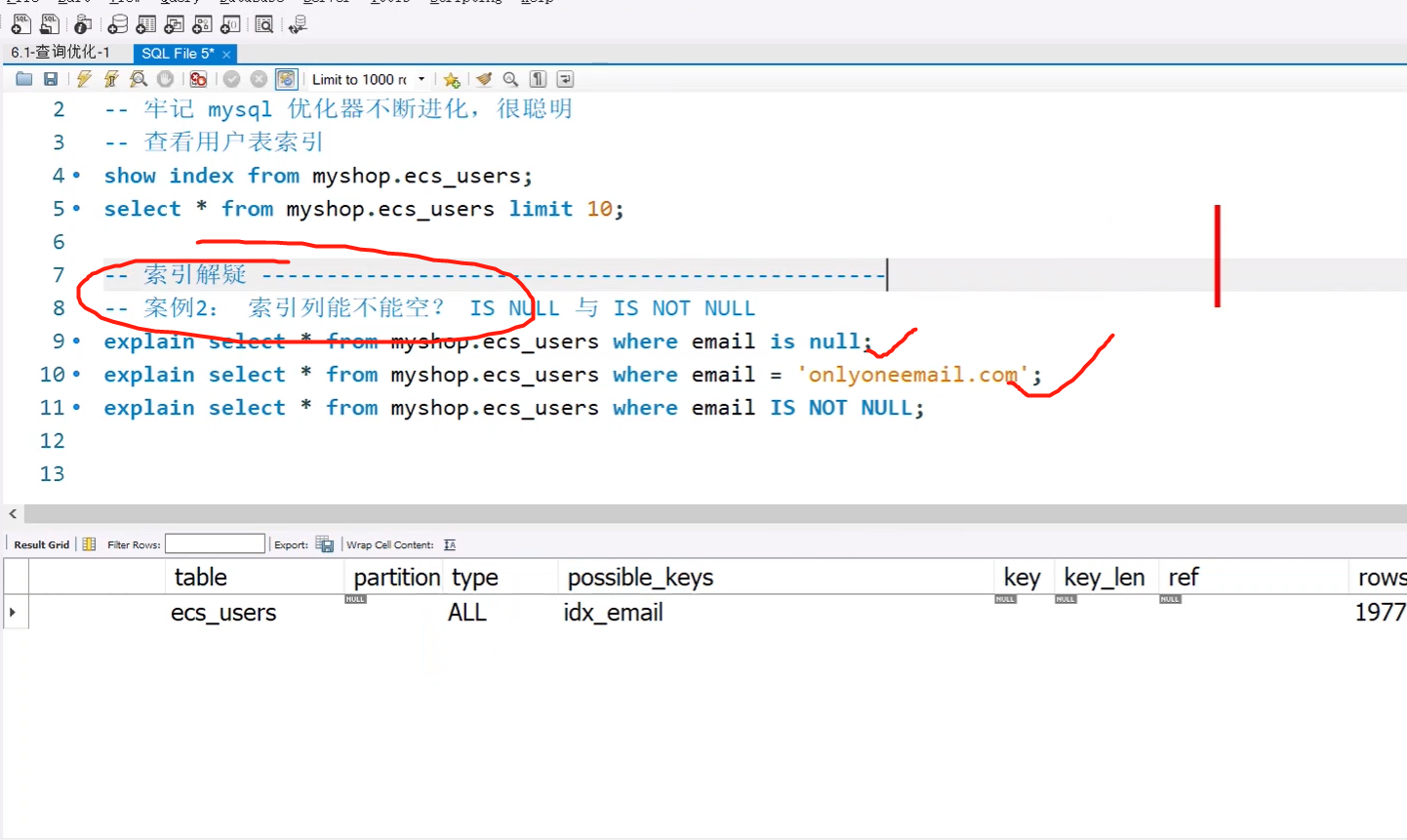
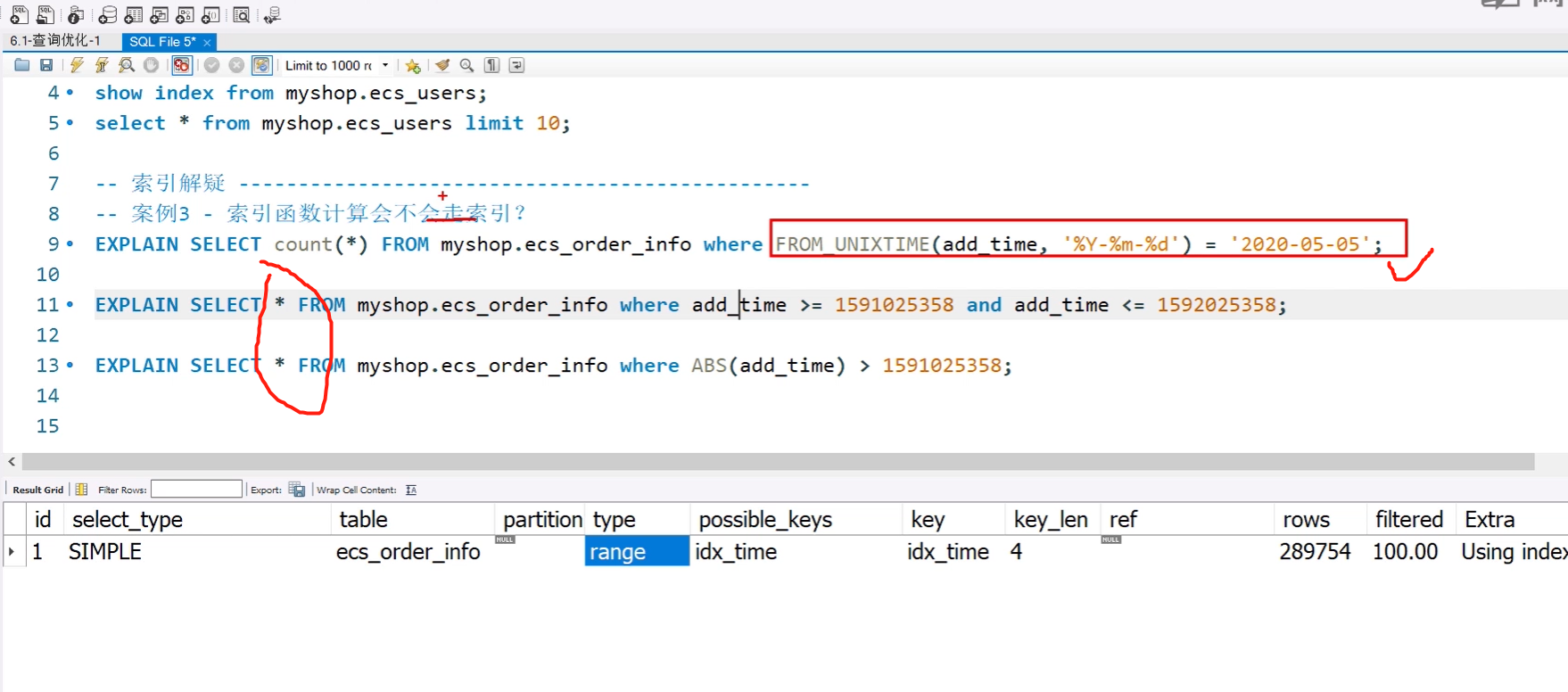
3. 问:索引函数计算会不会走索引
答:索引列使用函数计算会走索引,可是如果select 不是查询单纯的总数的话,就会进行全表扫描,就不会走索引。
如果索引列不用函数计算,单纯的用大于小于的话,会走索引
4.问:索引列查询类型跟字段类型不一致会不会走索引
答:会,因为mysql优化器会对查询语句进行优化,所以会走索引
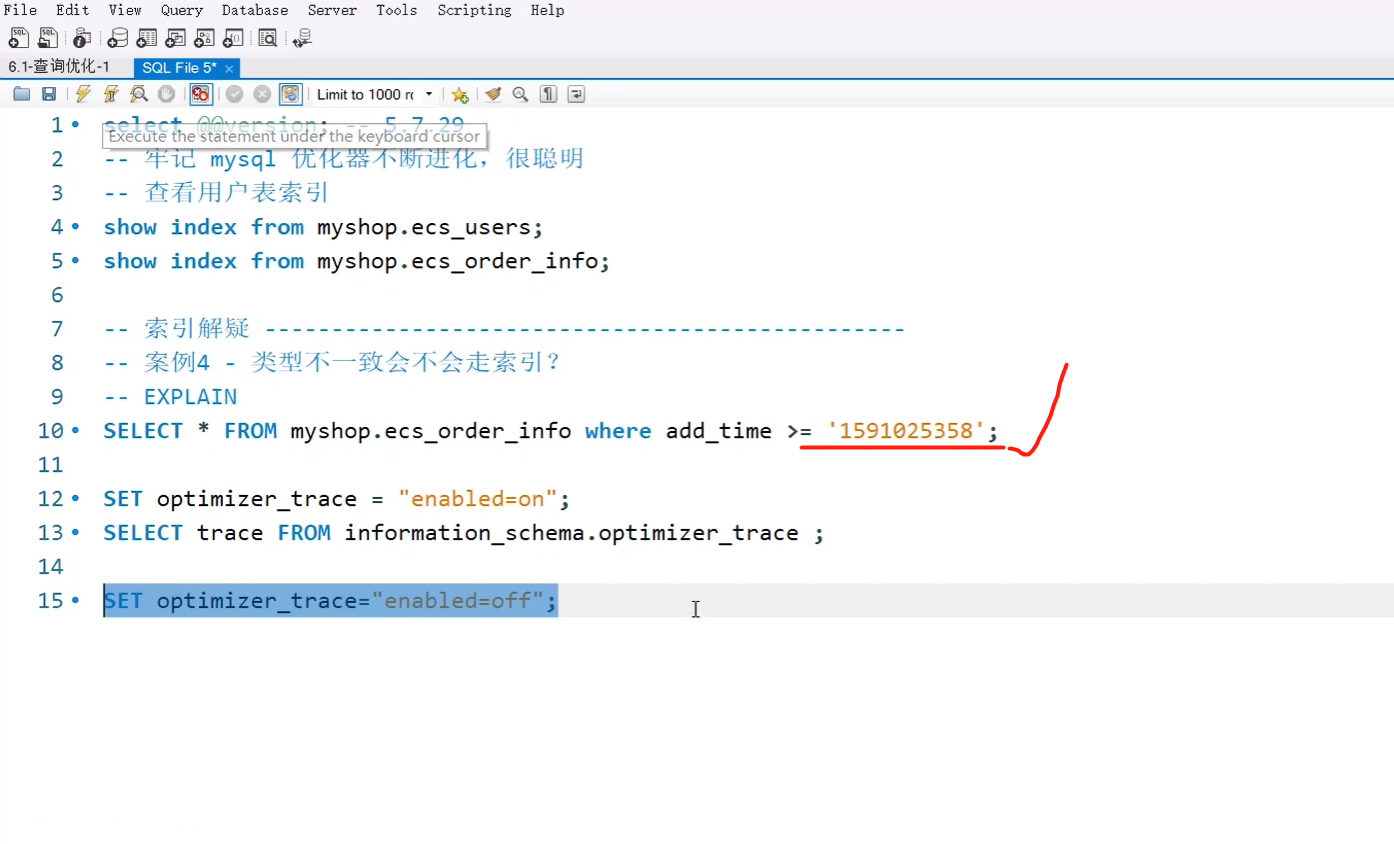
5.问:建立联合索引,顺序反了会不会走索引(从左自右命中)
只要保证命中(包含)联合索引最左边一个字段,就能命中该联合索引。
如果你的查询项没有包含索引最左边的字段,mysql不知道你要走哪个索引,所以没办法命中。
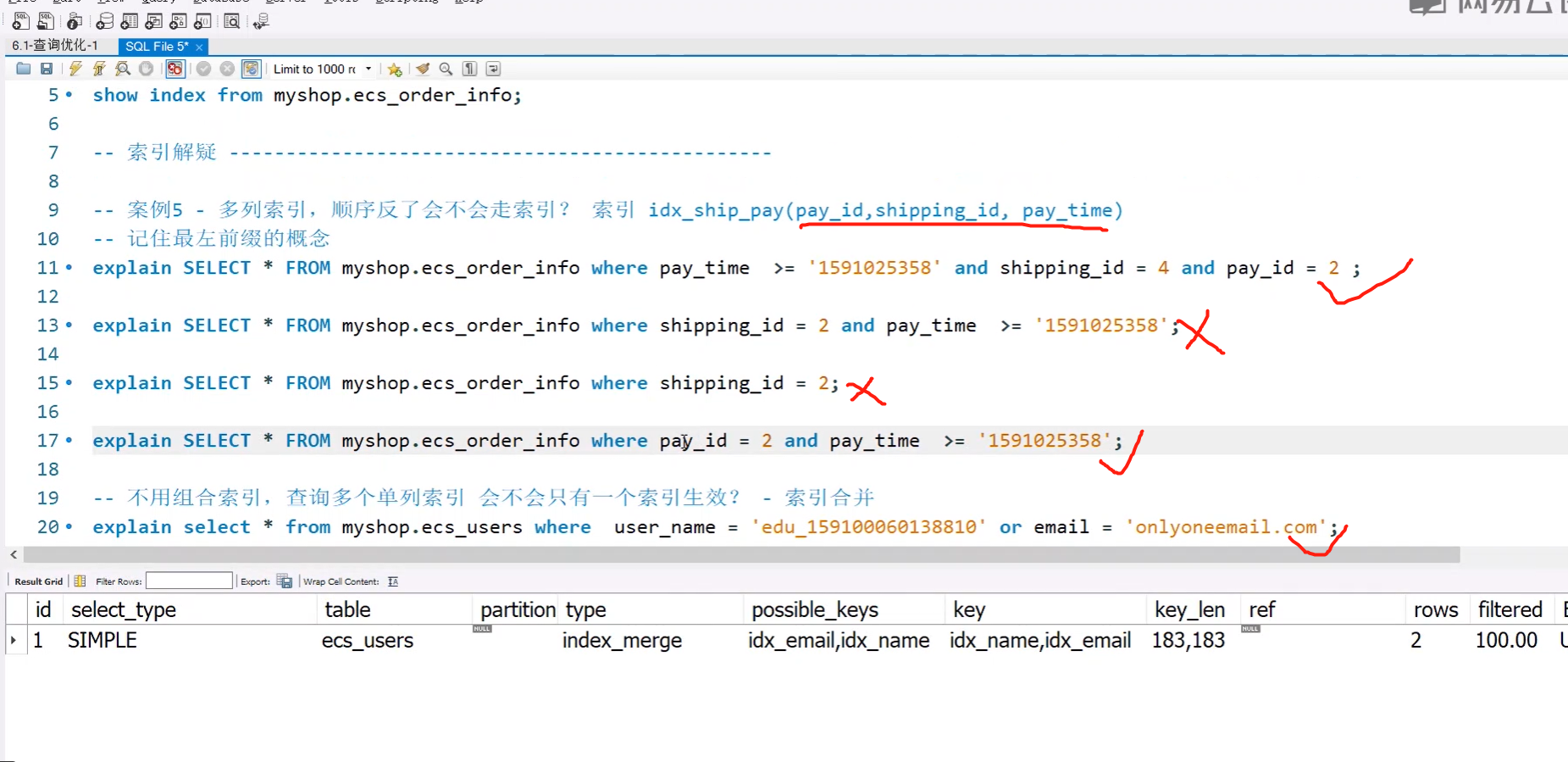
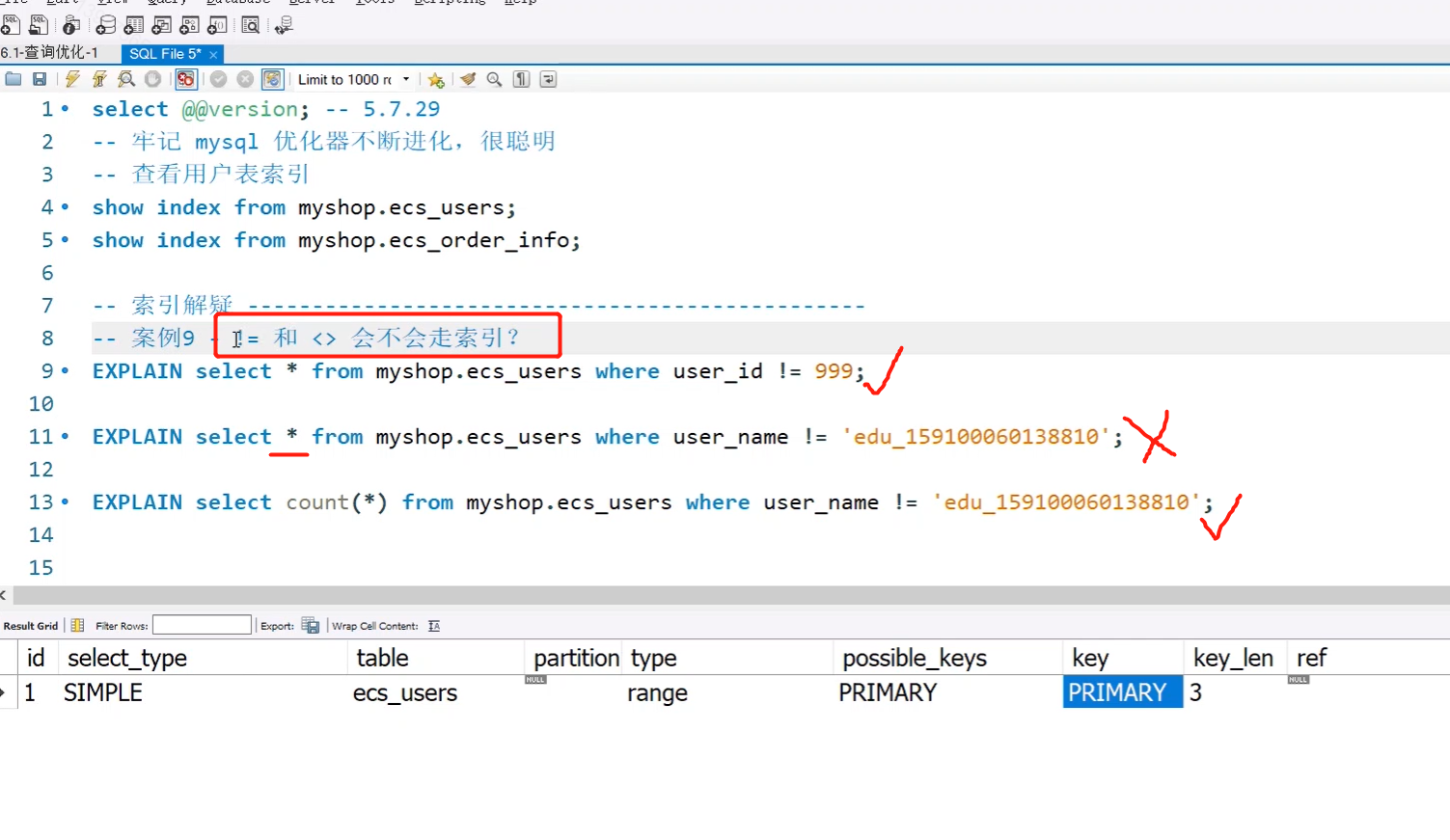
6.问:!=和<>会不会走所有
没有绝对的概念
1.在使用主键!=会走索引
2.在使用其他列并且查询的是总数的时候!=会走索引
3.在使用其他列并且查询是*的时候,不走索引,例如用户姓名,假设200w数据,有199.99万用户都不等于这个姓名,那mysql会觉得你没有必要走索引,不如进行全表扫描。
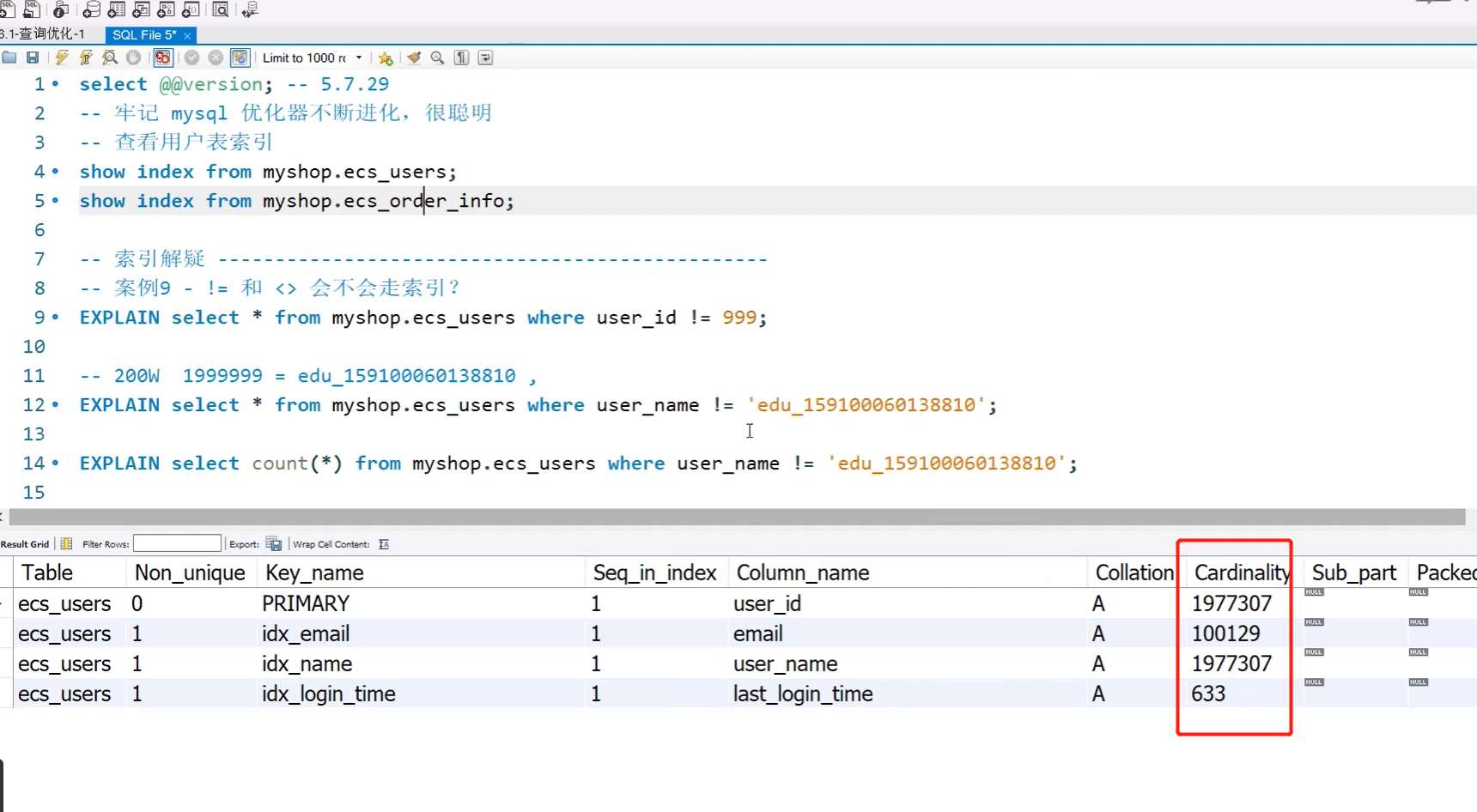
小结
所以这就是mysql优化器的作用,会对索引表不断地进行分析,通过不断分析计算每个索引的一个基数,基数越大说明这个索引列的差异度越大,基数越小说明这个索引的差异度越小。
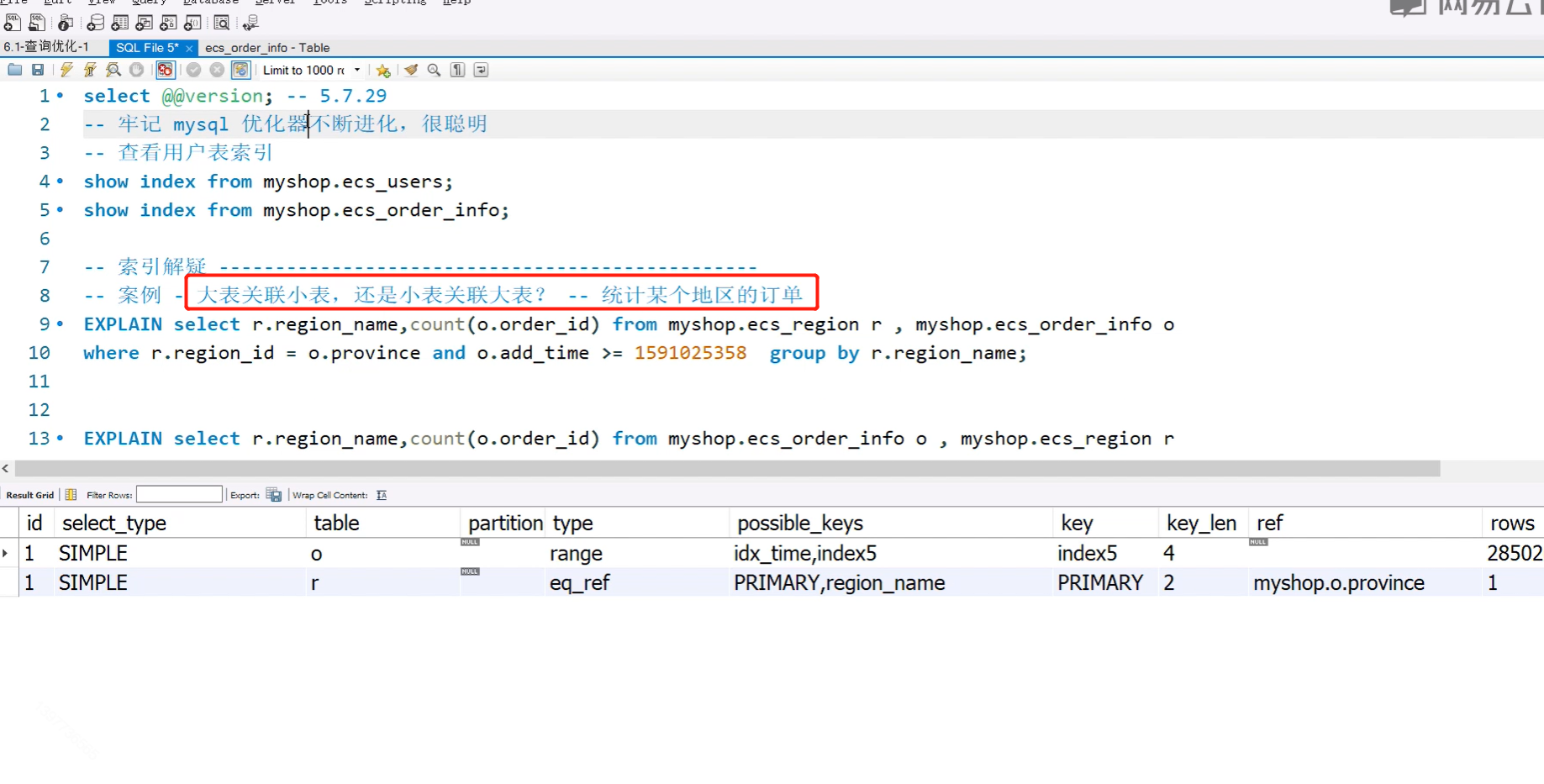
7. 表关联的时候是大表关联小表还是小表关联大表呢
还是那句话,这种事情mysql优化器会帮我们进行考虑,所以不用纠结写sql语句的时候该怎么去关联表,因为mysql优化器已经收集到了所有的数据,并且会不停的进行分析,所以它已经很聪明了。
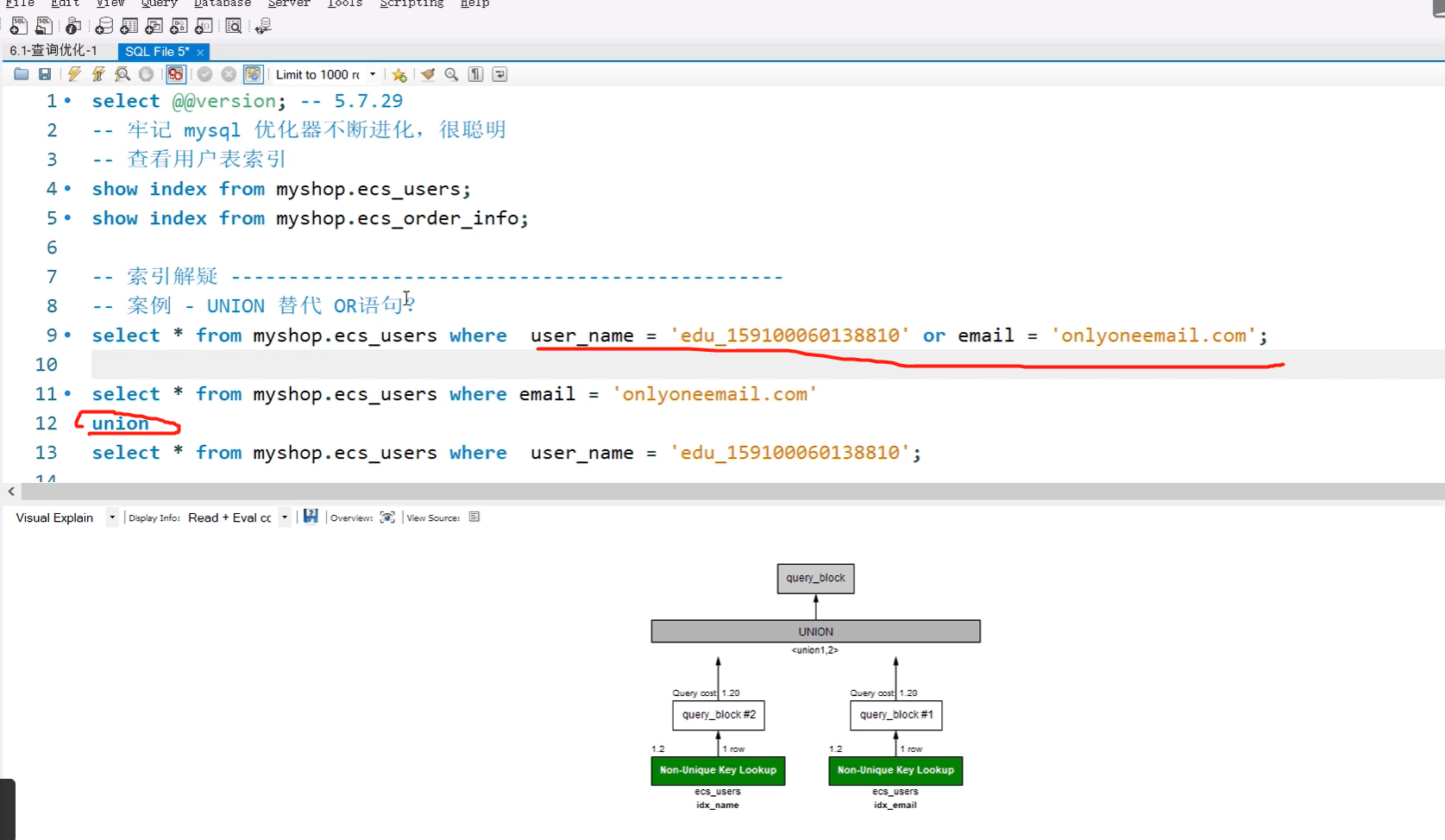
8.如果数据量特别大,可以将单条查询语句拆为两条,通过union来进行拼接,替代or进行查询
9.EXISTS 和 in的性能比较
子查询结果少,或者子查询是常量,用in
子查询结果过多,用exists
exists的原理就是遍历主查询结果集,然后一条条记录跟子查询条件进行比较。
in的原理就是先进行子查询,然后再扫描主查询表,再进行匹配