初步认识系统调用
目录
- 前言
- 一、什么是进程?
- 1、进程与程序的区别?
- 2、什么是进程的控制块
- 二、什么是系统调用?
- 三、认识几个比较简单的系统调用接口
- 1、查看进程
- 2、获取进程的pid/ppid
- (1).getpid/getppid
- (2)getpid/getppid的使用
- 3、创建进程的方法
- 总结
前言
之前我们学习的都是Linux中的一些基本的操作和基本的概念,从现在开始,我们要开始接触系统中的一些知识,我们学习Linux操作系统,本质就是要学习其中的系统编程,而系统编程主要就是要学习其中的系统调用接口,因此,我们可以发现,系统调用对于我们来说是非常重要的一项技能,那么从现在开始就让我们开始接触系统调用的相关知识吧!!!
一、什么是进程?
在操作系统中存在一个非常重要的概念,就是进程,很多教材都没有办法讲清楚什么是进程,有的教材说就是当一个程序载入内存时,并上处理机运行的时候就称之为一个进程,或者说形成了一个进程,实际上,在系统中是存在无数的进程的,进程的数量是非常非常多的,那么操作系统就必须将这些进程进行好好地管理,这就是所谓的进程管理。那么问题来了,操作系统是如何对进程进行管理的呢??是直接对运行的程序进行管理吗??显然不是的,首先我们需要知道,在操作系统中,我们需要为每一个进程维护一个数据结构,这个数据结构中应该存放进程的所有相关的信息及属性,比如常见的:进程的pid,进程的状态等等。那么操作系统就是通过每一个进程的数据结构对进程进行管理,我们知道,系统中的进程数量很多,所以直接对进程的数据结构进行管理的话同样也是一件令人头疼的事情,因此我们需要将这些管理对应进程的数据结构先组织起来,让他们有机地组合起来形成一种数据结构,比如常见的可以形成双链表,那么操作系统对这些数据结构的管理就可以转换为对这些链表进行增删查改,因此,我们来回想一下一个程序在形成到被处理机运行的整个过程:首先应该由对应的专业人员将程序文件写好并进行编译形成可执行程序,此时这个可执行程序所处的位置是磁盘,然后当这个程序要进行运行的时候就应该载入内存,根据上面所描述的,操作系统需要为载入内存的程序创建一个数据结构,这个结构中应该存放相应进程的相关属性信息,创建好之后,这个结构就会放到相应的运行队列中准备上处理机进行运行,这个过程就是一个进程的形成过程,所以很明显一个进程所包含的部分应该有两个部分:程序本身的代码和数据和操作系统为之创建的存放进程相关属性信息的结构体(PCB)
1、进程与程序的区别?
- 程序:当程序员写好代码之后在编译器上进行编译通过之后形成的文件就称为可执行程序,这个时候可执行程序存放的位置是磁盘
- 进程:当程序想要被运行的时候需要载入内存,操作系统为之创建一个结构体,这个过程就是进程的形成过程,因此,进程包含程序本身的代码和数据以及管理程序的结构体
2、什么是进程的控制块
操作系统为方便管理内存中的进程而为其创建的结构体,这个结构体中存放大量对应进程的相关属性信息,后面我们会着重进行讲解,也会学习很多获取这个结构体中的属性的相关的系统调用接口,这个结构体称之为进程控制块(PCB),再Linux中,这个结构体有一个具体的称号:task_struct
二、什么是系统调用?
因为操作系统使用起来成本比较大,一般情况人们很难直接对操作系统进行操作,我们知道,操作系统是一款能够管理软硬件资源的软件,它能够合理地管理系统中的软硬件资源,使它们能够正常地为我们提供服务。操作系统为了能够让人们容易地使用系统中的资源,所以操作系统提供了一系列的系统调用接口让我们去调用,我们需要什么服务就可以对应地调用对应的接口就可以完成相应的服务了,这些系统调用接口本质是用C语言写的C语言函数,因为,Linux就是用C语言写的一款操作系统,注意:这里的系统调用和我们平时在写C语言程序时调用的C语言库函数是不一样。
三、认识几个比较简单的系统调用接口
1、查看进程
- 方法一:ps指令
当一个程序运行起来之后,那么在系统中就会有相应的进程形成,那么我们应该怎么查看这个进程呢??我们可以使用ps指令+ajx选项进行查看系统中的进程,需要注意的是:单纯使用ps -ajx命令进行查看系统中的进程的话,会显示出系统中的所有进程,那么就不利用查看我们自己的进程
那么如果想要查看我们自己的进程应该结合grep指令进行查看,如果我们当前的可执行程序叫做process,那么我们可以采用指令ps -ajx|grep process,这样就可以将我们自己的进程筛选出来。
当我们用上面的命令进行操作的时候,带出来的结果还默认具有grep指令,那么如果想要去掉grep指令,我们可以采用:ps -ajx|grep process|grep -v grep,用于去掉grep进程

- 方法二:proc(内存文件系统)
存在的路径:

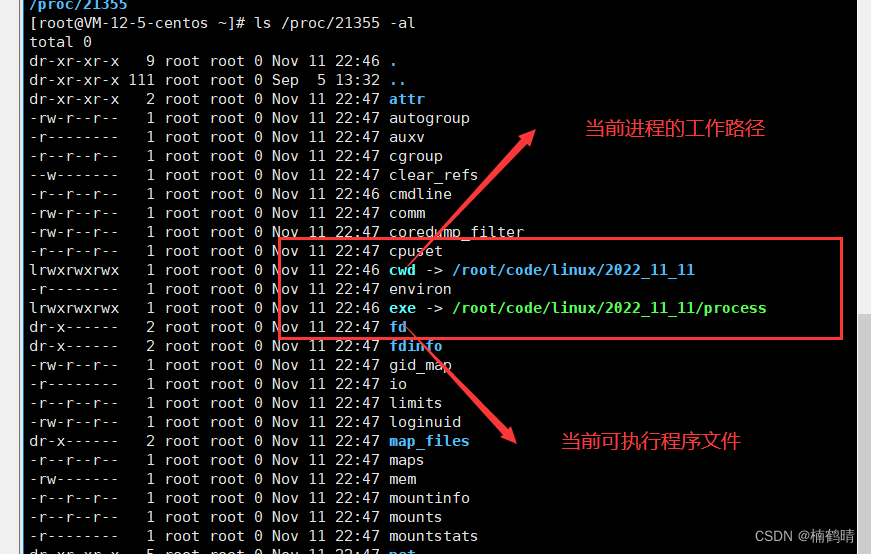
在这里首先我们需要明确一个点:就是一个进程的pid,这个是每一个进程所独有的,就像每一个人都具有独立的身份证号一样,是标识一个进程中的重要信息,proc就是通过一个进程的pid来查看进程,常见的命令:ls /proc/进程的pid,比如:ls /proc/1234,1234为一个进程的pid,如果我们想要查看这个进程的目录,可以加上-d选项,就是:ls /proc/1234 -d,还能够显示出进程中的其他信息,可以加上-al选项,比如:ls /proc/1234 -al,这里面包含这个进程中的可执行程序文件和这个进程的工作目录。
- ls /proc/进程的pid:查看进程中的文件
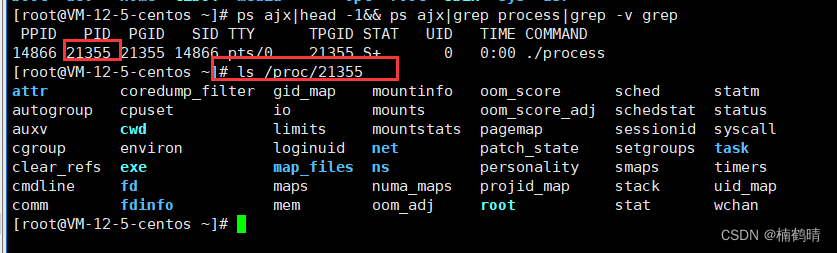
- ls /proc/进程pid -d:查看进程的目录

- ls /proc/进程pid -al:查看进程的其他信息
2、获取进程的pid/ppid
(1).getpid/getppid
- getpid:获取进程的pid
- getppid:获取进程的ppid
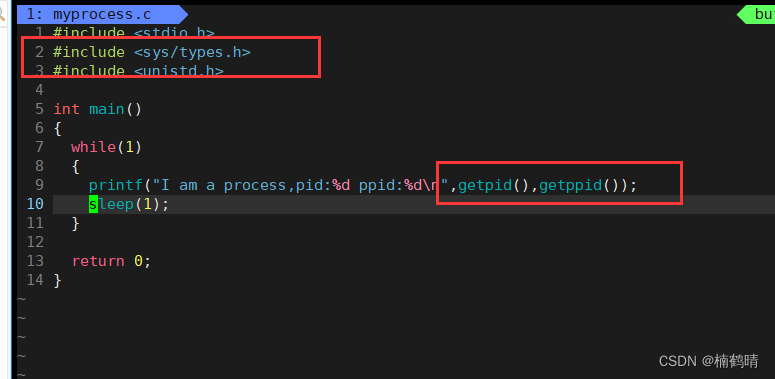
(2)getpid/getppid的使用
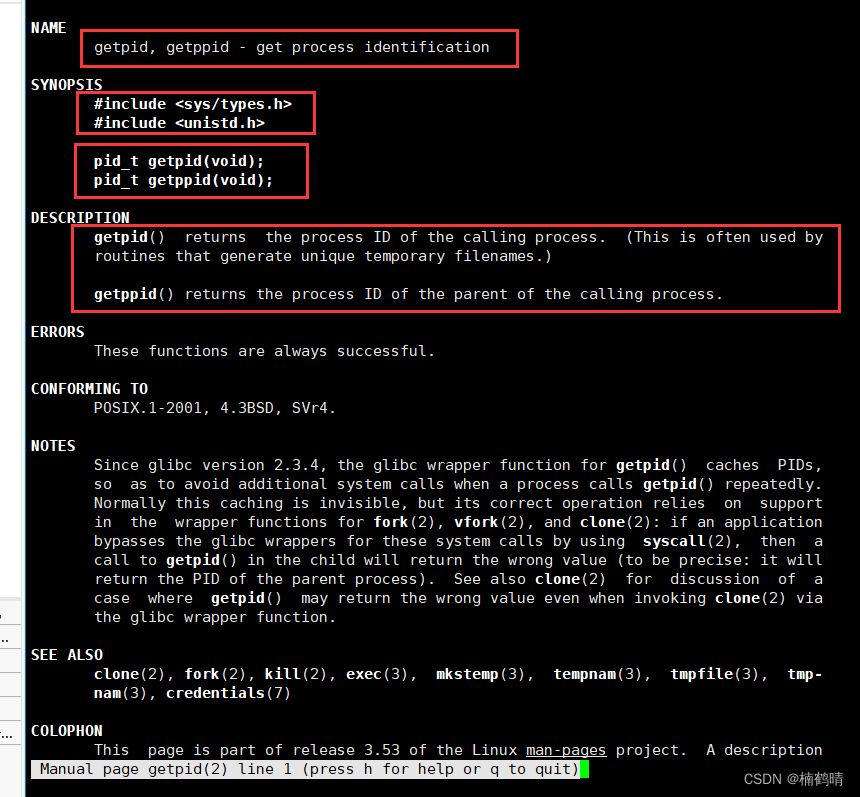
这两个系统调用接口需要在C语言源文件中加入,加入的时候需要包含两个头文件:
#include
#include
结果显示:
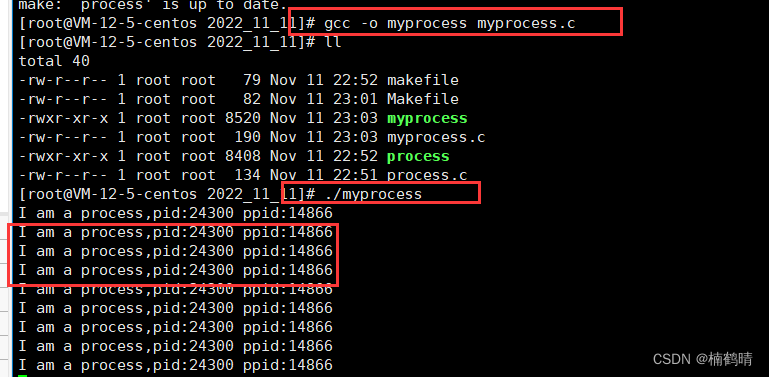
源代码:
3、创建进程的方法
使用fork()
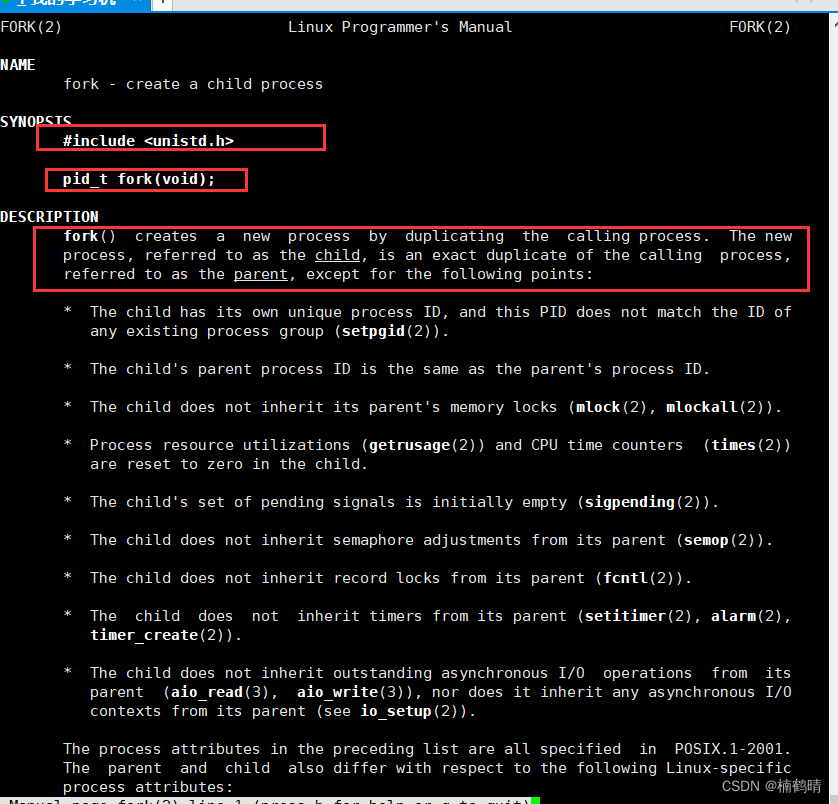
关于fork()的返回值?
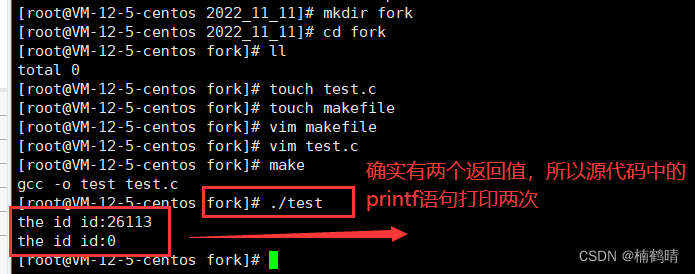
本来在系统中会存在一个进程,这个进程调用fork()之后就会成功创建一个子进程,现在系统中就有两个进程了,返回值的话就是fork()会给子进程返回0,给父进程返回子进程的pid,如果创建进程失败,则会给父进程返回-1
实验验证fork()调用之后确实有两个返回值
我们可以利用fork()函数的两个返回值让父子进程做不同的事

源代码
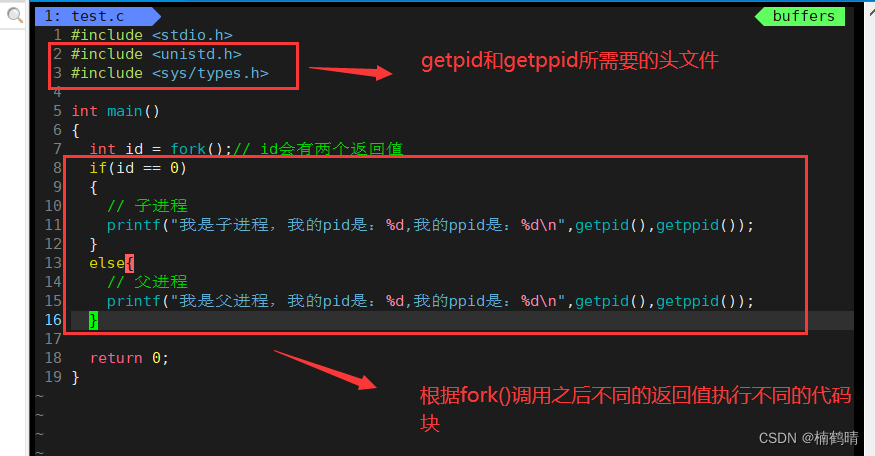
为什么fork()成功创建子进程之后是给父进程返回子进程的pid,给子进程返回0?
因为一个进程只有一个父进程,而一个进程可能有多个子进程,因此,通过父进程去找对应的子进程的成本就会相对而言比较大,通过子进程去找父进程的成本相对而言就会比较小,直接通过getppid()系统调用接口就可以找到其父进程了,因此子进程最重要的是要知道自己已经被创建成功,父进程就需要子进程的pid从而才能够对号入座找到对应的子进程
总结
今天主要认识了系统调用,学习了利用ps -ajx+grep指令和内存文件系统proc来查看进程,使用getpid()和getppid()来获取进程的pid和ppid,使用fork()来创建子进程