今日论文阅读2022-11-10
创始人
2024-01-20 16:07:15
0次
多模态预训练论文
ViLBERT: Pretraining Task-Agnostic Visiolinguistic Representations for Vision-and-Language Tasks
vision-and-language tasks: visual question answering,visual commonsense reasoning, referring expressions, and caption-based image retrieval and a special experiment setting 

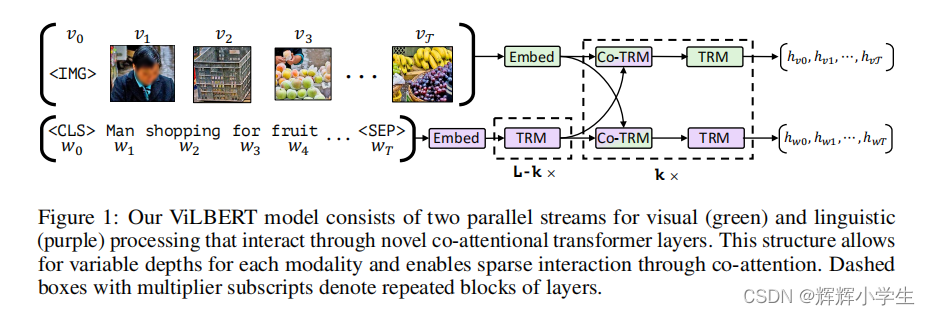 notes: Given an image I represented as a set of region features v1, . . . , vT and a text input w0, . . . , wT , our model outputs fifinal representations hv0, . . . , hvT and hw0, . . . , hwT . Notice that exchange between the two streams is restricted to be between specifific layers and that the text stream has signifificantly more processing before interacting with visual features – matching our intuitions that our chosen visual features are already fairly high-level and require limited context-aggregation compared to words in a sentence.
notes: Given an image I represented as a set of region features v1, . . . , vT and a text input w0, . . . , wT , our model outputs fifinal representations hv0, . . . , hvT and hw0, . . . , hwT . Notice that exchange between the two streams is restricted to be between specifific layers and that the text stream has signifificantly more processing before interacting with visual features – matching our intuitions that our chosen visual features are already fairly high-level and require limited context-aggregation compared to words in a sentence. 

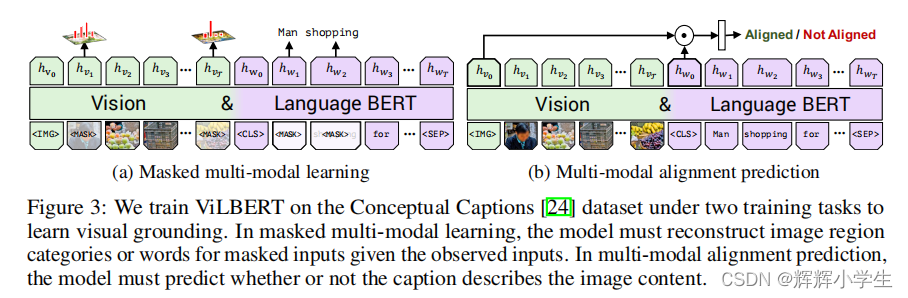

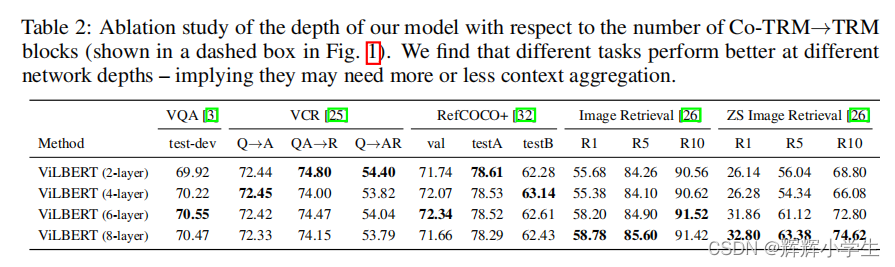
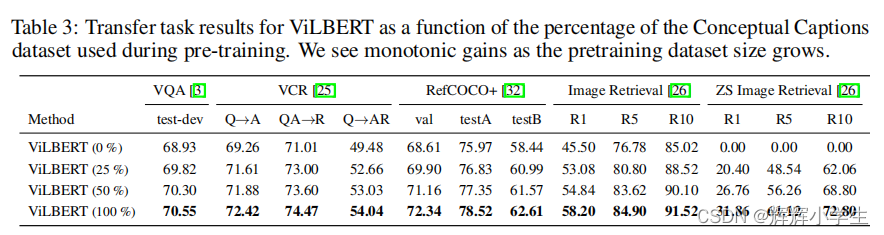 The first work is over.
The first work is over. 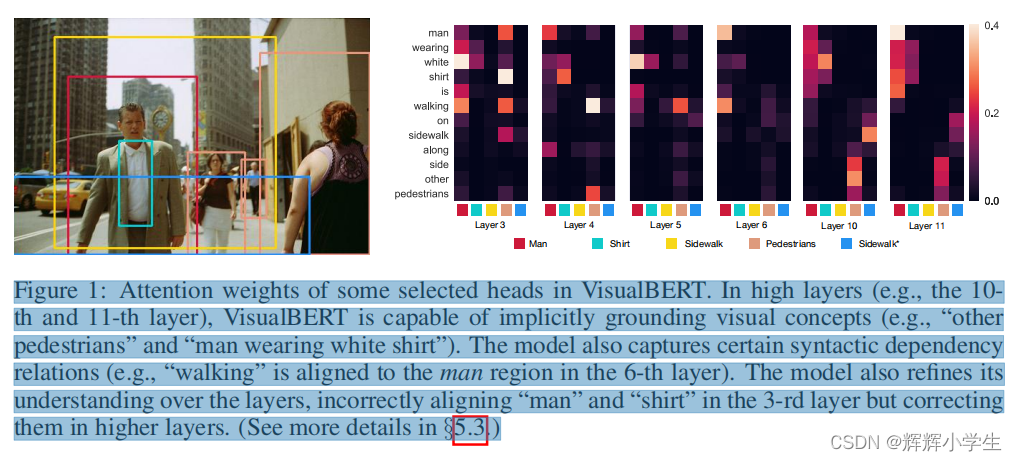






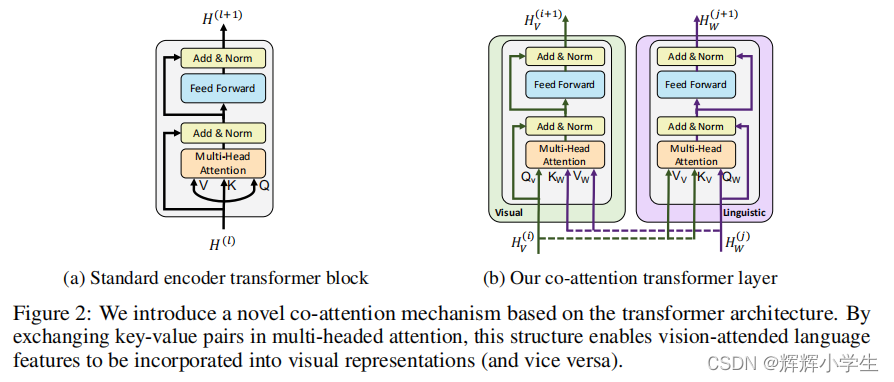
key technical innovation: introducing separate streams for vision and language processing that communicate through co-attentional transformer layers. why two-stream?
notes: Given an image I represented as a set of region features v1, . . . , vT and a text input w0, . . . , wT , our model outputs fifinal representations hv0, . . . , hvT and hw0, . . . , hwT . Notice that exchange between the two streams is restricted to be between specifific layers and that the text stream has signifificantly more processing before interacting with visual features – matching our intuitions that our chosen visual features are already fairly high-level and require limited context-aggregation compared to words in a sentence.
The first work is over.
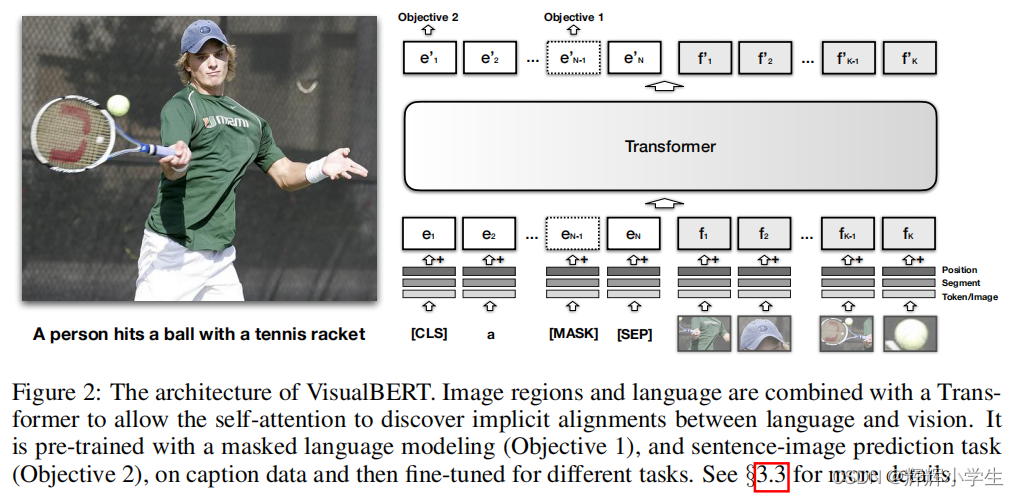
VISUALBERT: A Simple And Performant Baseline For Vision And Language two visually-grounded language model objectives for pre-training: (1) part of the text is masked and the model learns to predict the masked words based on the remaining text and visual context; (2) the model is trained to determine whether the provided text matches the image. We show that such pre-training on image caption data is important for VisualBERT to learn transferable text and visual representations. conduct comprehensive experiments on four vision-and-language tasks:VQA VCR NLVR regionto-phrase grounding


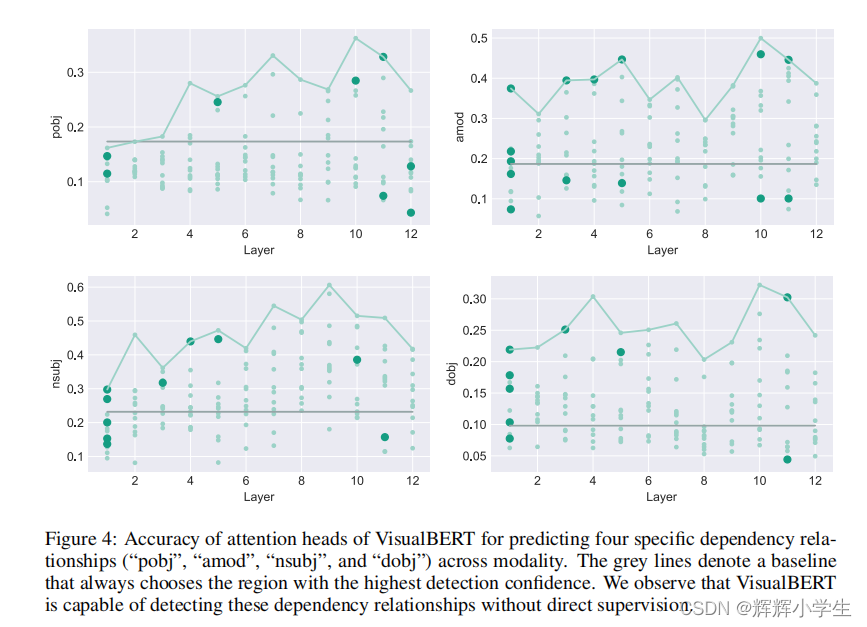

The second work is over.
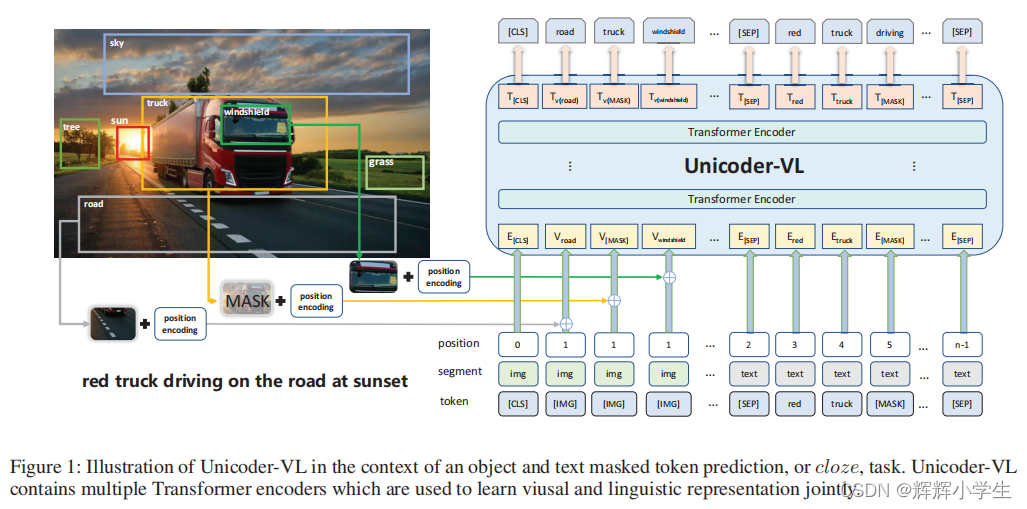
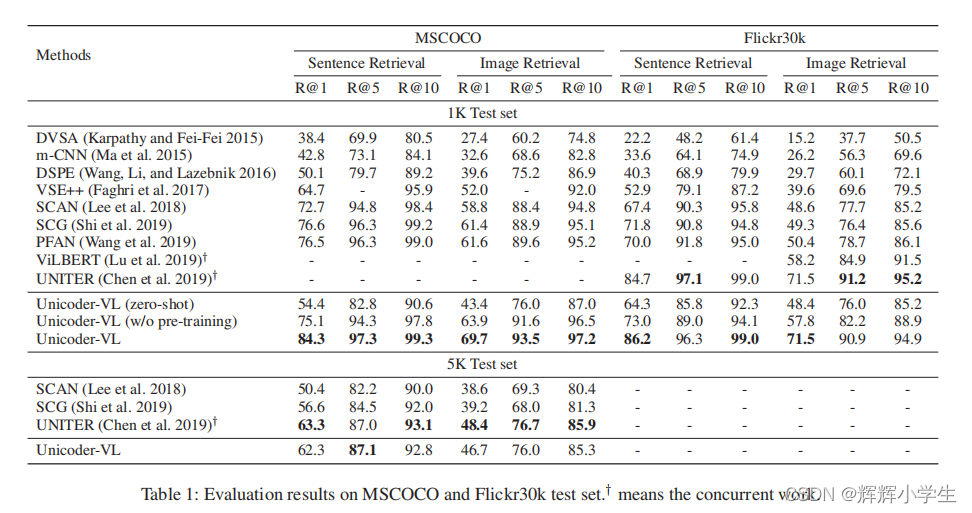
Unicoder-VL: A Universal Encoder for Vision and Language by Cross-Modal Pre-Training 
approach

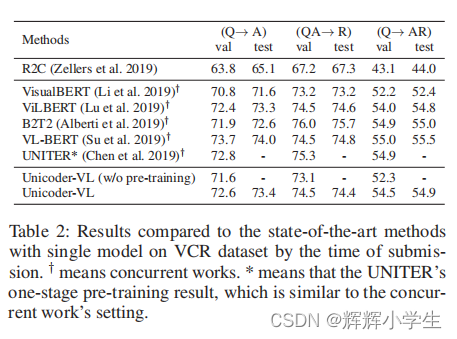
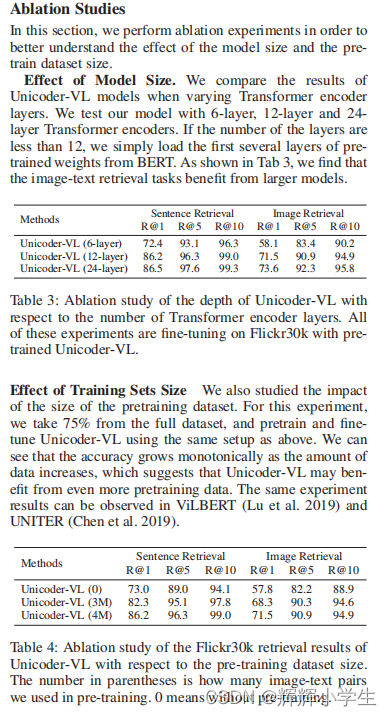
The third word is over.
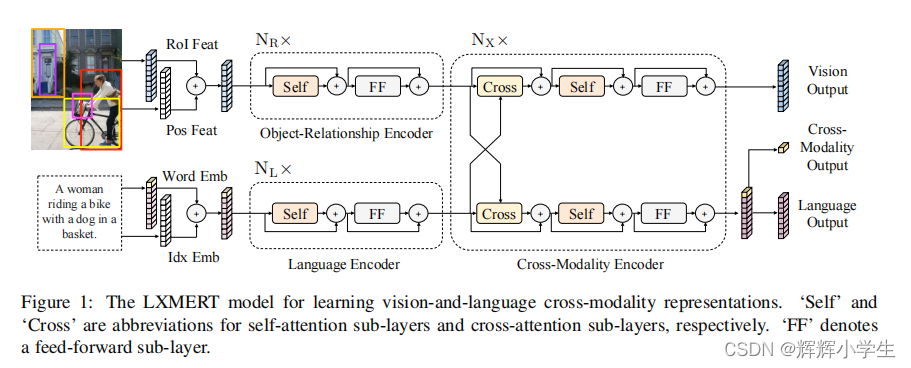
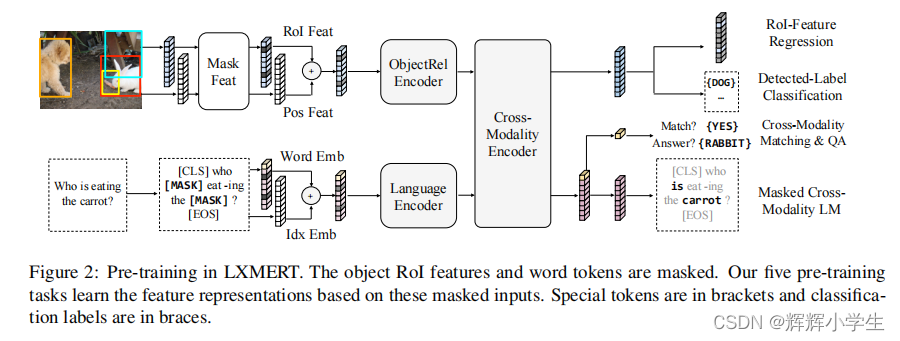
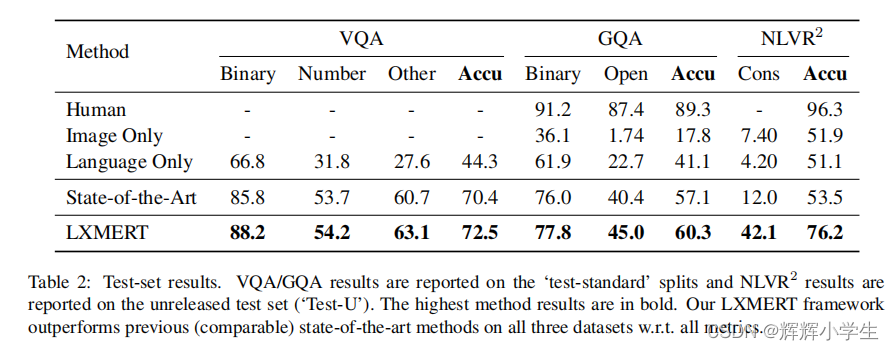
LXMERT: Learning Cross-Modality Encoder Representations from Transformers It consists of three Transformer: encoders: an object relationship encoder, a language encoder, and across-modality encoder.pre-train our model with fifive diverse representative tasks: (1) masked crossmodality language modeling (2) masked object prediction via RoI-feature regression (3) masked object prediction via detected-label classifification, (4) cross-modality matching (5) image question answering.
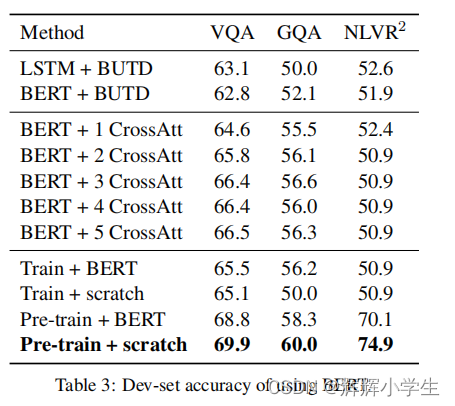
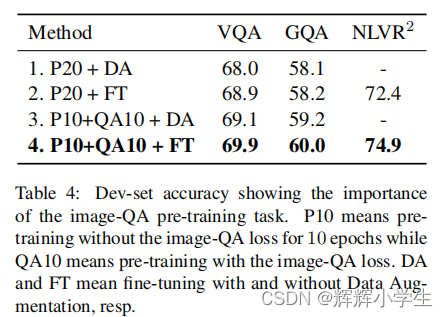
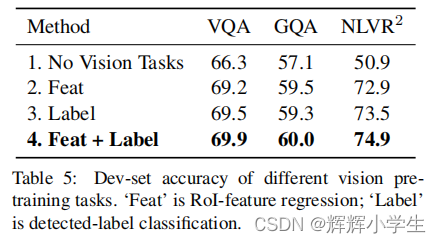
over
相关内容
热门资讯
喜欢穿一身黑的男生性格(喜欢穿...
今天百科达人给各位分享喜欢穿一身黑的男生性格的知识,其中也会对喜欢穿一身黑衣服的男人人好相处吗进行解...
网络用语zl是什么意思(zl是...
今天给各位分享网络用语zl是什么意思的知识,其中也会对zl是啥意思是什么网络用语进行解释,如果能碰巧...
苏州离哪个飞机场近(苏州离哪个...
本篇文章极速百科小编给大家谈谈苏州离哪个飞机场近,以及苏州离哪个飞机场近点对应的知识点,希望对各位有...
发春是什么意思(思春和发春是什...
本篇文章极速百科给大家谈谈发春是什么意思,以及思春和发春是什么意思对应的知识点,希望对各位有所帮助,...
为什么酷狗音乐自己唱的歌不能下...
本篇文章极速百科小编给大家谈谈为什么酷狗音乐自己唱的歌不能下载到本地?,以及为什么酷狗下载的歌曲不是...
家里可以做假山养金鱼吗(假山能...
今天百科达人给各位分享家里可以做假山养金鱼吗的知识,其中也会对假山能放鱼缸里吗进行解释,如果能碰巧解...
四分五裂是什么生肖什么动物(四...
本篇文章极速百科小编给大家谈谈四分五裂是什么生肖什么动物,以及四分五裂打一生肖是什么对应的知识点,希...
华为下载未安装的文件去哪找(华...
今天百科达人给各位分享华为下载未安装的文件去哪找的知识,其中也会对华为下载未安装的文件去哪找到进行解...
怎么往应用助手里添加应用(应用...
今天百科达人给各位分享怎么往应用助手里添加应用的知识,其中也会对应用助手怎么添加微信进行解释,如果能...
客厅放八骏马摆件可以吗(家里摆...
今天给各位分享客厅放八骏马摆件可以吗的知识,其中也会对家里摆八骏马摆件好吗进行解释,如果能碰巧解决你...