ElasticSearch系列——Kibana,核心概念
ElasticSearch系列——Kibana,核心概念
- Kibana
- 下载地址
- Windows安装
- 修改配置文件
- 启动Kibana
- 验证
- ES核心概念
- Index索引
- Mapping映射
- Document文档
- 使用Kibana对ES进行操作
- 查询所有索引
- 查询指定索引
- 创建索引
- 指定分片和副本数
- 删除索引
- 创建映射
- 查看指定索引的映射信息
- 映射无法删除
- 创建文档
- 不指定文档ID
- 指定文档ID
- 文档查询
- 查询所有文档
- 查询指定ID的文档
- 删除文档
- 更新文档
- 覆盖更新(更新整个文档)
- 更新部分字段
- 文档批量操作
- 批量新增
- DSL查询
- 条件查询
- 范围查询
- 前缀查询
- 匹配查询(通配符查询)
- 多ID查询
- 模糊查询
- 多条件查询
- 多字段查询
- 字段分词查询
- 高亮查询
- 自定义高亮标签
- 分页查询
- 排序
- 指定字段查询
Kibana
Kibana 是一个免费且开放的用户界面,能够让您对 Elasticsearch 数据进行可视化,并让您在 Elastic Stack 中进行导航。您可以进行各种操作,从跟踪查询负载,到理解请求如何流经您的整个应用,都能轻松完成。
Kibana Navicat是一个针对Elasticsearch mysql的开源分析及可视化平台,使用Kibana可以查询、查看并与存储在ES索引的数据进行交互操作,使用Kibana能执行高级的数据分析,并能以图表、表格和地图的形式查看数据
下载地址
https://www.elastic.co/cn/downloads/kibana
这里注意一下你的Kibana版本一定要和ES对应起来
Windows安装
下载完后放置目录解压缩即可
修改配置文件
我们需要设置开启远程访问和配置ES的映射地址端口
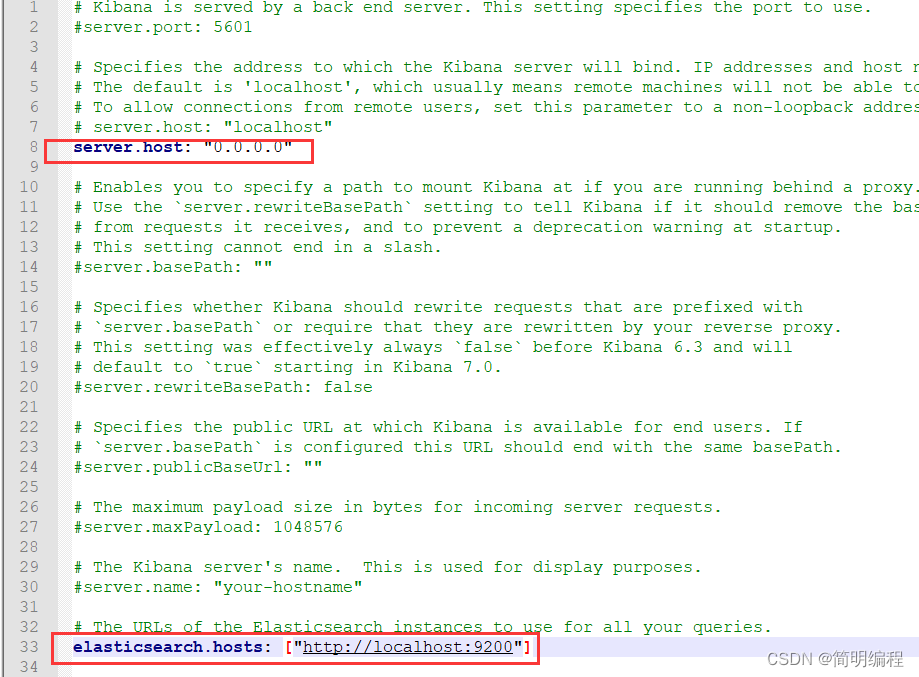
我们找到conf目录下的kibana.yaml文件
添加以下配置
server.host: "0.0.0.0"
elasticsearch.hosts: ["http://localhost:9200"]
启动Kibana
打开bin目录,找到kibana.bat双击启动即可,但是你一定要确保先启动了ES
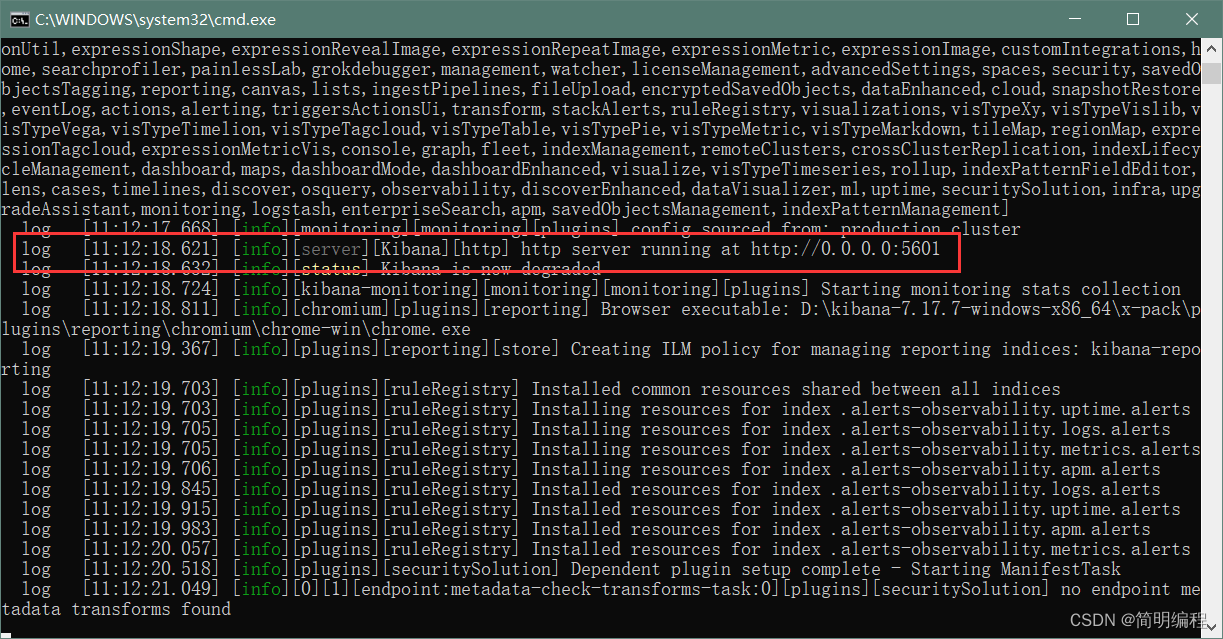
启动后如下图:
我们需要访问5601端口
验证
右击侧边栏,点击Management选择Dev Tools
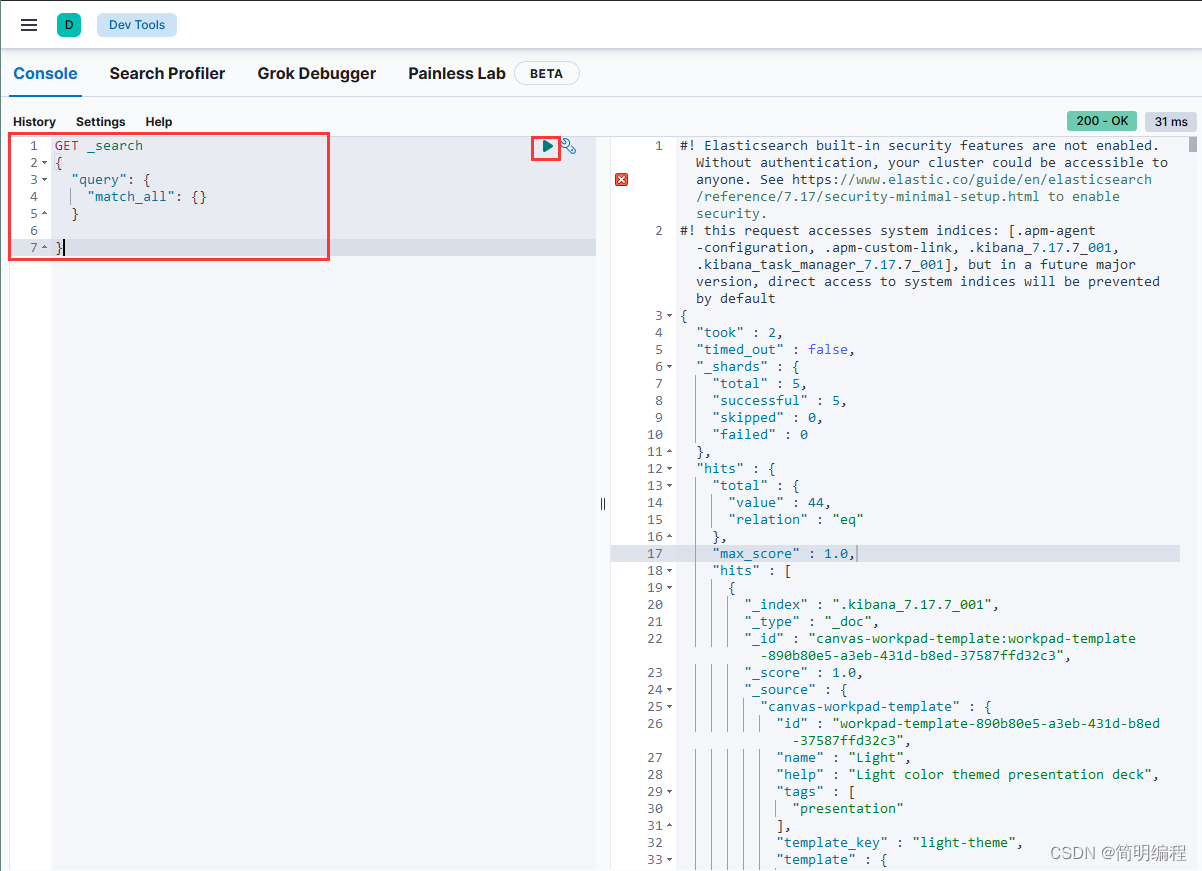
点击按钮执行发现有打印说明连接已经成功
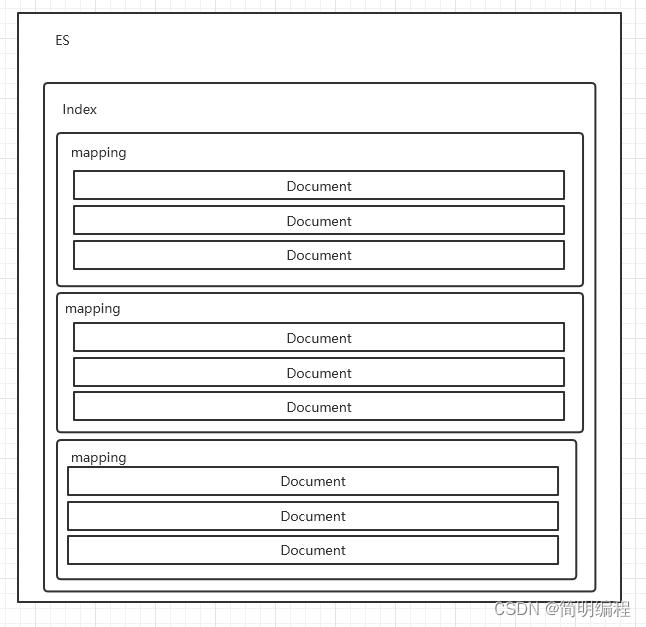
ES核心概念
Index索引
一个索引就是一个拥有几分相似特征的文档的集合。比如说,你可以有一个商品数据的索引,一个订单数据的索引,还有一个用户数据的索引。一个索引由一个名字来标识(必须全部是小写字母的),并且当我们要对这个索引中的文档进行索引、搜索、更新和删除的时候,都要使用到这个名字。
Mapping映射
映射是定义一个文档和它所包含的字段如何被存储和索引的过程。在默认配置下,ES可以根据插入的数据自动地创建mapping,也可以手动创建mapping 。mapping中主要包括字段名、字段类型等
Document文档
文档是索引中存储的一条条数据。一条文档是一个可被索引的最小单元。ES中的文档采用了轻量级的JSON格式数据来表示。
把他作为数据库看
ES——mysql
Index索引——table表
mapping映射——schema数据库字段
document文档——row数据库表的一行

使用Kibana对ES进行操作
查询所有索引
GET /_cat/indices?v

查询指定索引
# 查询某个索引
# products是索引名称
GET /products
创建索引
# 创建索引
# products是索引名称
PUT /products
指定分片和副本数
# 创建索引时指定分片和副本数
# "number_of_shards": 1, 指定分片数为1
# "number_of_replicas": 1 指定副本数为1
PUT /products
{"settings": {"number_of_shards": 1, "number_of_replicas": 1}
}
删除索引
# 删除索引
DELETE /products
创建映射
一般我们在创建索引时同时创建映射
# 创建索引同时创建映射
# mappings表示映射
# properties表示映射中的字段内容,下面是具体的字段以及类型
# 字符串型:keyword(关键词搜索,不分词),text(全文搜索,分词)
# 数字类型:integer,long
# 小数浮点型:float,double
# 布尔类型: boolean
# 日期类型: date
PUT /products
{"settings": {"number_of_replicas": 0,"number_of_shards": 1},"mappings": {"properties": {"name":{"type": "keyword"},"price":{"type": "float"},"create_time":{"type": "date"},"des":{"type": "text"}}}
}
查看指定索引的映射信息
# 查询索引的映射信息
GET /products/_mapping
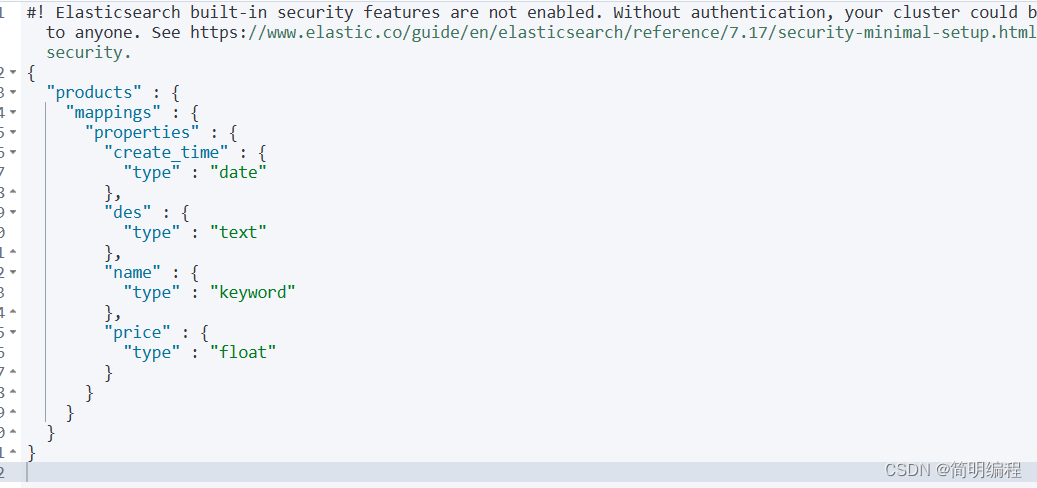
映射无法删除
若要删除请直接删除索引
创建文档
不指定文档ID
POST /products/_doc
{"name":"辣条","price":2.5,"des":"卫龙辣条","create_time":"2022-11-08"
}
指定文档ID
# 创建文档并指定文档的ID
POST /products/_doc/1
{"name":"辣条","price":2.5,"des":"卫龙辣条","create_time":"2022-11-08"
}
文档查询
查询所有文档
# 查询所有文档
GET /products/_search
查询指定ID的文档
# 文档查询
# 1是文档的ID
GET /products/_doc/1
删除文档
# 删除指定文档
DELETE /products/_doc/1
更新文档
覆盖更新(更新整个文档)
# 覆盖更新
# 先删除在创建
PUT /products/_doc/2
{"name":"辣条","price":2.8,"des":"老干妈辣条","create_time":"2022-11-07"
}
更新部分字段
# 更新部分字段
POST /products/_doc/2/_update
{"doc":{"price":5.5}
}
文档批量操作
对应关键字:
- 新增:index(
{"index":{"_id":3}}) - 更新:update(
{"update":{"_id":3}}) - 删除:delete(
{"delete":{"_id":3}})
虽然是批量操作但是每一条都是单独运行的!
批量新增
# 文档批量操作 使用_bluk
# {"index":{"_id":3}}表示指定文档ID为3
POST /products/_doc/_bulk
{"index":{"_id":3}}{"name":"笔记本","price":6.66,"des":"普通笔记本","create_time":"2022-11-08"}
{"index":{"_id":4}}{"name":"舍利子","price":998,"des":"累积功德","create_time":"2022-11-08"}
{"index":{"_id":5}}{"name":"假发","price":32.36,"des":"一发遮秃头","create_time":"2022-11-08"}
DSL查询
ES中提供了一种强大的检索数据方式,这种检索方式称之为Query DSL , Query DSL是利用Rest API传递JSON格式的请求体(RequestBody)数据与ES进行交互,这种方式的丰富查询语法让ES检索变得更强大,更简洁。
有关这部分其实我上篇文章也提到了,不过上篇是基于APIFox的其实查询的JSON就是我们的请求体,大家看请求体就知道了
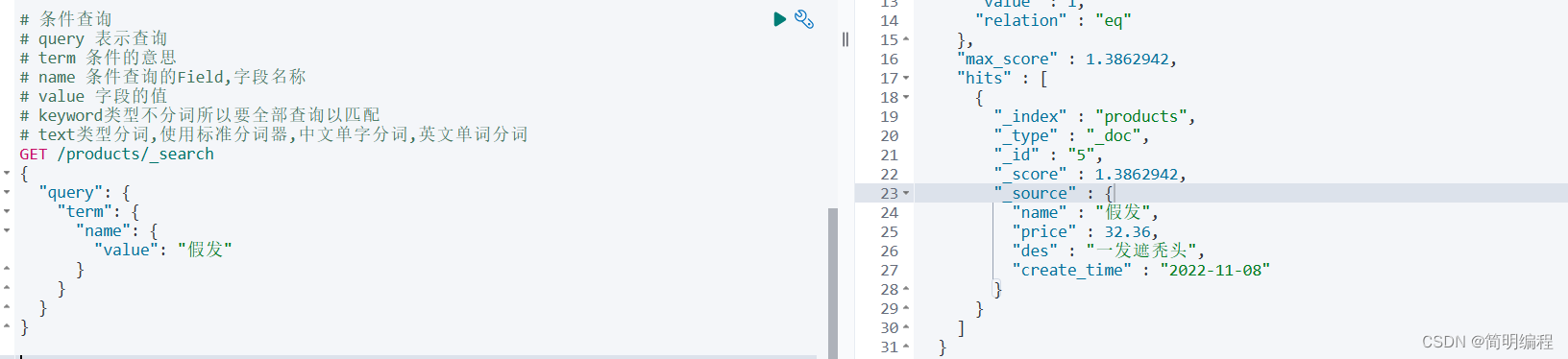
条件查询
# 条件查询
# query 表示查询
# term 条件的意思
# name 条件查询的Field,字段名称
# value 字段的值
# keyword类型不分词所以要全部查询以匹配
# text类型分词,使用标准分词器,中文单字分词,英文单词分词
GET /products/_search
{"query": {"term": {"name": {"value": "假发"}}}
}
范围查询
- gt:大于
- gte:大于或等于
- ne是不等于
- eq是等于
- lt小于
- lte小于或等于
# 范围查询
GET /products/_search
{"query": {"range": {"price": {"gte": 0,"lte": 20}}}
}前缀查询
使用prefix关键字,用于检索含有指定前缀的关键词的相关文档
# 前缀查询
GET /products/_search
{"query": {"prefix": {"name": {"value": "辣"}}}
}
匹配查询(通配符查询)
使用wildcard关键字
?: 用于匹配单个任意字符*: 用于匹配n多个任意字符
# 匹配查询
GET /products/_search
{"query": {"wildcard": {"name": {"value": "辣?"}}}
}
# 匹配查询
GET /products/_search
{"query": {"wildcard": {"name": {"value": "笔*"}}}
}
多ID查询
使用ids关键字,值为数组类型,用来根据一组id获取多个对应的文档
# 多ID查询
GET /products/_search
{"query": {"ids": {"values": ["3","2"]}}
}
模糊查询
使用fuzzy关键字,注意只能用来查询关键字(keyword)
- 搜索关键词长度为2不允许存在模糊
- 搜索关键词长度为3-5允许一次模糊
- 搜索关键词长度大于5允许最大2模糊
# 模糊查询
GET /products/_search
{"query": {"fuzzy": {"name": "b记本"}}
}多条件查询
使用bool关键字配合must,should,must_not
- must:所有条件必须同时成立
- must_not:所有条件必须同时不成立
- should:所有条件中成立一个即可
# 多条件查询
GET /products/_search
{"query": {"bool": {"must": [{"term": {"name": {"value": "辣条"}}},{"term": {"create_time": {"value": "2022-11-07"}}}]}}
}
多字段查询
使用multi_match关键字
query字段会进行分词然后匹配
# 多字段查询
GET /products/_search
{"query": {"multi_match": {"query": "辣条 老干妈","fields": ["name","des"]}}
}
字段分词查询
默认字段分词查询会根据你的字段,若是可以分词的就分词查询,若不能分词就不分
使用query_string关键字
GET /products/_search
{"query": {"query_string": {"default_field": "name","query": "辣条"}}
}
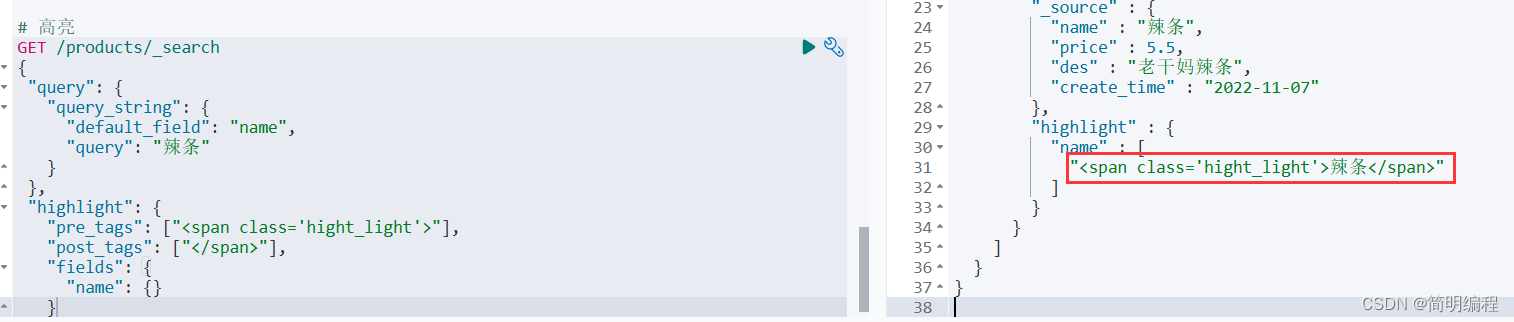
高亮查询
使用highlight关键字指定高亮的字段
若使用*则表示所有都高亮
"highlight": {"fields": {"*": {}}}
# 高亮
GET /products/_search
{"query": {"query_string": {"default_field": "name","query": "辣条"}},"highlight": {"fields": {"name": {}}}
}
自定义高亮标签
由于默认使用标签进行高亮,我们也可以自己定义
使用pre_tags设置前置标签
使用post_tags设置后置标签
GET /products/_search
{"query": {"query_string": {"default_field": "name","query": "辣条"}},"highlight": {"pre_tags": [""],"post_tags": [""], "fields": {"name": {}}}
}
分页查询
我们使用match_all进行全部搜索的时候使用size关键字设置每一页的大小,使用from关键字设置页码
from的计算公式:(页码-1)*size
# 分页查询
GET /products/_search
{"query": {"match_all": {}},"size": 3,"from": 0
}
当我们查询第二页的时候就应该让from设置为3
第三页则是6
排序
使用sort关键字指定需要进行排序的字段设置排序类型即可
- desc:降序
- asc:升序
# 排序
GET /products/_search
{"query": {"match_all": {}},"sort": [{"price": {"order": "desc"}}]
}指定字段查询
使用_source关键字在数组中设置需要展示的字段
# 指定字段查询
GET /products/_search
{"query": {"match_all": {}},"_source": ["name","price"]
}
上一篇:Shell变量的定义及用法
下一篇:ES6的Promise详解