Python BeautifulSoup4 入门使用
创始人
2024-01-22 08:10:16
0次
一、简介
-
BeautifulSoup4与lxml一样,是一个html解析器,主要功能也是解析和提取数据。 -
BeautifulSoup4是爬虫必学的技能。BeautifulSoup最主要的功能是从网页抓取数据,Beautiful Soup自动将输入文档转换为Unicode编码,输出文档转换为utf-8编码,不需要考虑编码方式,除非文档没有指定一个编码方式,这时,Beautiful Soup就不能自动识别编码方式了,然后,仅仅需要说明一下原始编码方式就可以了。 -
BeautifulSoup支持Python标准库中的HTML解析器,还支持一些第三方的解析器,如果不安装它,则Python会使用Python默认的解析器。 -
使用步骤
# 1、安装 $ pip install bs4# 2、导入 from bs4 import BeautifulSoup# 3、创建对象 soup = beautifulsoup(解析内容,解析器)# 服务器响应文件生成对象(注意编码格式) soup = BeautifulSoup(response.read().decode('utf-8'), 'lxml') # 本地文件生成对象(注意编码格式) soup = BeautifulSoup(open('test.html', 'r', encoding='utf-8'), 'lxml') -
常用解析器:
html.parser、lxml、xml、html5lib,其中lxml解析器更强大,速度更快,推荐使用lxml解析器,附 beautifulsoup 菜鸟教程。# 如果解释器不存在,则需要进行安装,其他解释器也一样 $ pip install lxml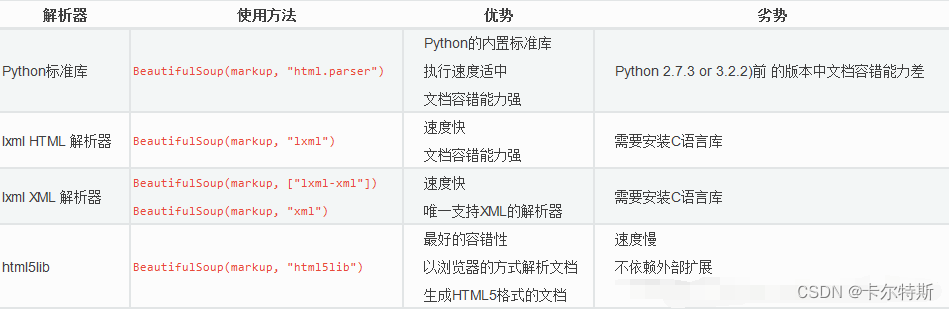
二、案例
-
列举一下比较常用的几个方法
find()、find_all()、select(),推荐使用select()支持选择器写法,还有一些属性的基本获取,更多的方法知道使用在查就行了,懒的列。 -
本地测试数据
Document - 北京
- 上海
- 深圳
- 武汉 新浪微博哈哈哈
- 大连
- 沈阳
- 长沙
-
本地测试代码
# 导入 from bs4 import BeautifulSoup# 本地文件生成对象 soup = BeautifulSoup(open('test.html', 'r', encoding='utf-8'), 'lxml')# 根据标签名查找节点 # 找到第一个符合条件的节点返回 print(soup.a) # 新浪微博# 获取标签的属性和属性值 print(soup.a.attrs) # {'href': '', 'id': 'xlwb'}# soup.find():返回单个对象# 根据 title 值来找到对应的标签对象 print(soup.find('li', title="dzm")) #- 武汉
# 根据 class 值来找到对应的标签对象 # print(soup.find('li', class="c1")) # 关键字 class 存在 python 中会报错无法使用 print(soup.find('li', class_="c1")) # 可以通过加下划线来使用属于系统关键字的属性- 北京
# soup.find_all():返回数组# 查找所有 a 标签 print(soup.find_all('a')) # [新浪微博, 百度一下]# 查找所有 a | span 标签 print(soup.find_all(['a', 'span'])) # [新浪微博, 哈哈哈, 百度一下]# limit 限制查找数量,查找前几个数据 print(soup.find_all('li', limit=2)) # [- 北京
,- 上海
]#【推荐使用】soup.select():返回数组,制成选择器写法# 查找所有 a 标签 print(soup.select('a')) # [新浪微博, 百度一下]# 查找所有 a | span 标签 print(soup.select('a,span')) # [新浪微博, 哈哈哈, 百度一下]# 【类选择器】 # 查找 class 属性为 c2 的标签 print(soup.select('.c2')) # [- 上海
] # 查找 id 属性为 l3 的标签 print(soup.select('#l3')) # [- 深圳
]# 【属性选择器】 # 查找 li 标签中有 id 的标签 print(soup.select('li[id]')) # [- 北京
,- 上海
,- 深圳
,- 武汉
] print(soup.select('li[id="l2"]')) # [- 上海
]# 【后代选择器】 # 找到 div 下的 li print(soup.select('div li')) # [- 北京
,- 上海
,- 深圳
,- 武汉
]# 【子代选择器】 # print(soup.select('div>ul>li')) # 这种格式的,空格写不写都行 print(soup.select('div > ul > li')) # [- 北京
,- 上海
,- 深圳
,- 武汉
]# 【推荐使用】节点属性# 获取节点内容(注意:标签对象中只有内容,那么下面两个都行,如果标签对象中还包含其他标签,那么 string 就获取不到了) # 推荐使用 get_text() print(soup.select('span')[0].string) # 哈哈哈 print(soup.select('span')[0].get_text()) # 哈哈哈# 获得节点 obj = soup.select('#xlwb')[0] # 新浪微博 # 标签名称 print(obj.name) # a # 标签属性json print(obj.attrs) # {'href': '', 'id': 'xlwb'} # 获取属性值 print(obj.attrs['id']) # xlwb print(obj.attrs.get('id')) # xlwb print(obj.get('id')) # xlwb print(obj['id']) # xlwb
相关内容
热门资讯
喜欢穿一身黑的男生性格(喜欢穿...
今天百科达人给各位分享喜欢穿一身黑的男生性格的知识,其中也会对喜欢穿一身黑衣服的男人人好相处吗进行解...
网络用语zl是什么意思(zl是...
今天给各位分享网络用语zl是什么意思的知识,其中也会对zl是啥意思是什么网络用语进行解释,如果能碰巧...
苏州离哪个飞机场近(苏州离哪个...
本篇文章极速百科小编给大家谈谈苏州离哪个飞机场近,以及苏州离哪个飞机场近点对应的知识点,希望对各位有...
发春是什么意思(思春和发春是什...
本篇文章极速百科给大家谈谈发春是什么意思,以及思春和发春是什么意思对应的知识点,希望对各位有所帮助,...
为什么酷狗音乐自己唱的歌不能下...
本篇文章极速百科小编给大家谈谈为什么酷狗音乐自己唱的歌不能下载到本地?,以及为什么酷狗下载的歌曲不是...
家里可以做假山养金鱼吗(假山能...
今天百科达人给各位分享家里可以做假山养金鱼吗的知识,其中也会对假山能放鱼缸里吗进行解释,如果能碰巧解...
四分五裂是什么生肖什么动物(四...
本篇文章极速百科小编给大家谈谈四分五裂是什么生肖什么动物,以及四分五裂打一生肖是什么对应的知识点,希...
华为下载未安装的文件去哪找(华...
今天百科达人给各位分享华为下载未安装的文件去哪找的知识,其中也会对华为下载未安装的文件去哪找到进行解...
怎么往应用助手里添加应用(应用...
今天百科达人给各位分享怎么往应用助手里添加应用的知识,其中也会对应用助手怎么添加微信进行解释,如果能...
客厅放八骏马摆件可以吗(家里摆...
今天给各位分享客厅放八骏马摆件可以吗的知识,其中也会对家里摆八骏马摆件好吗进行解释,如果能碰巧解决你...