[R]第二节 对象介绍与赋值运算
创始人
2024-01-22 06:16:26
0次
前言
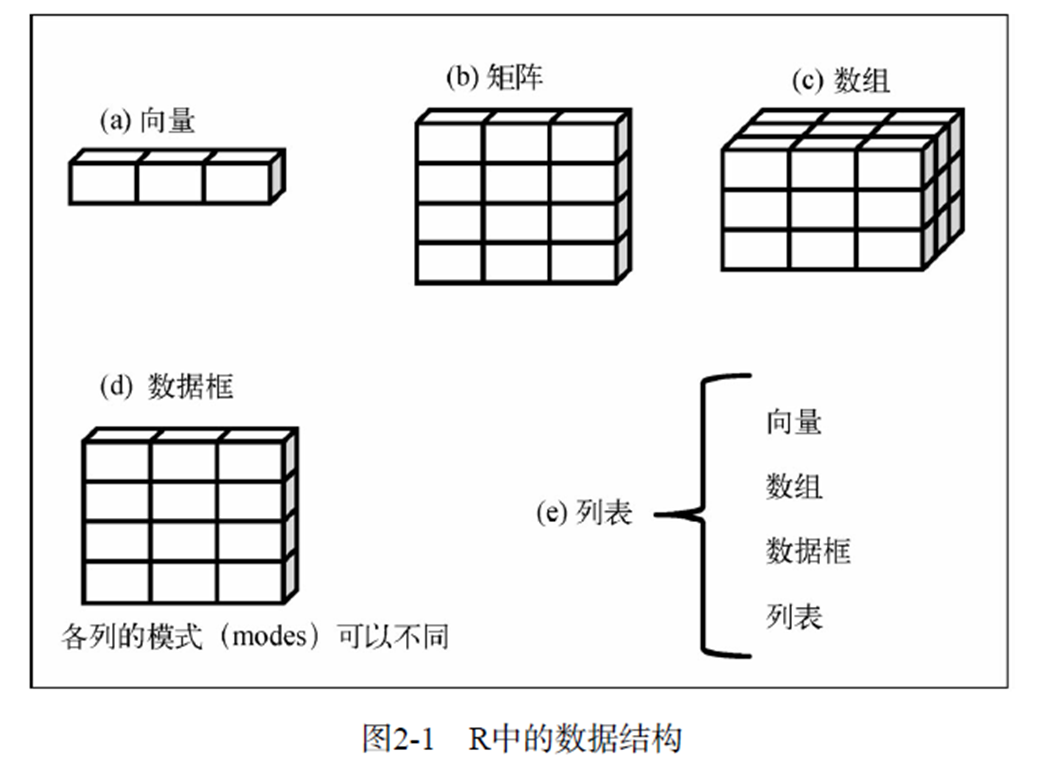
- R 创建、控制的实体(entity)称为对象(object)。
-
- 向量(vector)
- 矩阵(matrix)
- 数组(array)
- 数据框(data frame)
- 列表(list)
- 因子(factor)
- 函数(function)
- 通过以上实体定义的更为一般性的结构(structures)
数据的存储形式
- R语言进行数据存储
-
- 选择一种合适的数据结构
- 将已有的数据输入或者导入到这个数据结构中
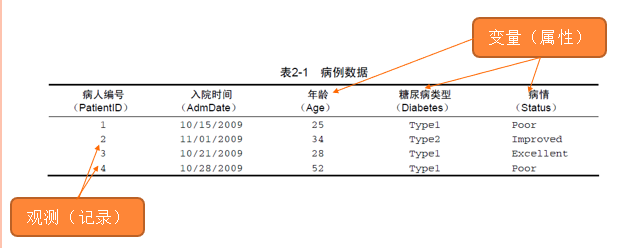
- 通常看到的数据结构(如Excel):
2.1 向量-向量元素必须相同类型
2.1.1数值向量
- 向量赋值
> x<-c(1,2,3,4,5)
> y<-c(1:5)
> z<-seq(from=1,by=1,to=5)
> m=c(1:5)
> assign("n",c(1:5))
> p<-c(x,88,y)
> q<-rep(c(88,99),3)
- "<-"是赋值符号。在多数情况下,可用"="替代。函数c()是赋值语句,其返回值为向量。
- 也可以采用以下语句进行赋值。
> c(1:5)->k
- 若不将采用赋值符号,则结果直接显示在屏幕上。
> 1/x
- 引用元素
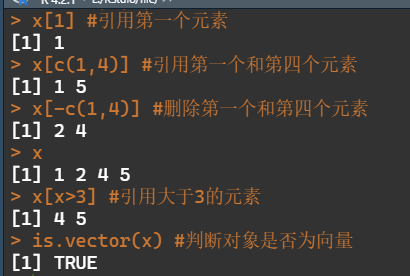
> x<-c(1,2,4,5) #赋值
> x[1] #引用第1个元素
> x[c(1,4)] #引用第1个和第4个元素
> x[-c(1,4)] #删除第1个和第4个元素
> x[x>3] #引用大于3的元素
> is.vector(x) #判断对象是否为向量
2.1.2字符向量
- 元素必须用双引号或者单引号
- 当字符向量以没有引号的形式显示时,缺失值以
形式显示
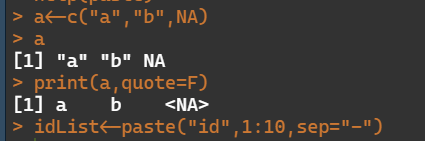
a<-c("a","b",NA)
a
print(a,quote=F) #quote=F用于将字符向量的双引号去掉#产生字符序列
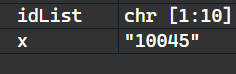
idList<-paste("id",1:10,sep="-")
#一个简单的paste()将多个元素作为输入,
#并将这些输入连接到一个字符串中。
#元素将以空格分隔作为默认选项。
#但是您也可以使用'sep'参数更改分隔符值。

- 取出第二个到第三个字符
substr("12345",2,3)
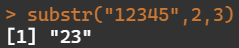
- 替换第二个到第三个字符
x<-"12345" substr(x,2,3)<-"00"
substr(x,2,3)<-"1"

所以我们可以看到,如果后面赋给前面字符串中多个引用的变量,一个"1"不能赋给"2"和"3"两个位置的变量,所以只能给2位置的变量赋值1.
- 判断字符元素的长度
nchar(x)
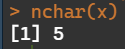
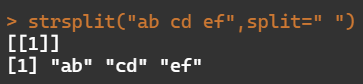
- 分隔字符
strsplit("ab cd ef",split=" ")
- 转换成大小写字符
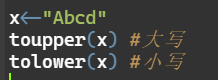
toupper(x) #大写 tolower(x) #小写
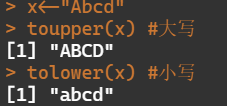
x<-c("this","isis","an","apple")
- 返回匹配元素位置
grep("is",x)
[1] 1 2
- 返回等长的数值向量。不匹配则-1,匹配则为第一个匹配的位置
regexpr("is",x)
[1] 3 1 -1 -1
- 替换字符,仅替换元素第一个匹配值
sub("is","QQ",x)
[1] "thQQ","QQis","an","apple"

- 替换字符,替换元素所有匹配值
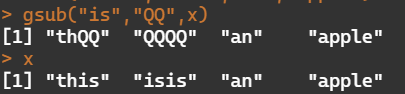
gsub("is","QQ",x)
[1] "thQQ","QQQQ","an","apple"
2.1.3缺失值
- 当一个元素在统计的时候不可获得(not available)或者元素是缺失值(missing value),则相关位置会被保留并赋予一个特定值NA。
- 任何含有NA数据的运算结果都将是NA
x<-c(1:100,NA) res1<-sum(x) res2<-sum(x,na.rm=T)
- 数值运算会产生另一种缺失值NaN,表示非数值(Not a Number)。
res1 <- 0/0 res1 <- Inf - Inf
- is.na()判断NA和NaN都是TRUE。
- is.nan()仅对NaN判断为TRUE
相关内容
热门资讯
喜欢穿一身黑的男生性格(喜欢穿...
今天百科达人给各位分享喜欢穿一身黑的男生性格的知识,其中也会对喜欢穿一身黑衣服的男人人好相处吗进行解...
网络用语zl是什么意思(zl是...
今天给各位分享网络用语zl是什么意思的知识,其中也会对zl是啥意思是什么网络用语进行解释,如果能碰巧...
苏州离哪个飞机场近(苏州离哪个...
本篇文章极速百科小编给大家谈谈苏州离哪个飞机场近,以及苏州离哪个飞机场近点对应的知识点,希望对各位有...
发春是什么意思(思春和发春是什...
本篇文章极速百科给大家谈谈发春是什么意思,以及思春和发春是什么意思对应的知识点,希望对各位有所帮助,...
为什么酷狗音乐自己唱的歌不能下...
本篇文章极速百科小编给大家谈谈为什么酷狗音乐自己唱的歌不能下载到本地?,以及为什么酷狗下载的歌曲不是...
家里可以做假山养金鱼吗(假山能...
今天百科达人给各位分享家里可以做假山养金鱼吗的知识,其中也会对假山能放鱼缸里吗进行解释,如果能碰巧解...
四分五裂是什么生肖什么动物(四...
本篇文章极速百科小编给大家谈谈四分五裂是什么生肖什么动物,以及四分五裂打一生肖是什么对应的知识点,希...
华为下载未安装的文件去哪找(华...
今天百科达人给各位分享华为下载未安装的文件去哪找的知识,其中也会对华为下载未安装的文件去哪找到进行解...
怎么往应用助手里添加应用(应用...
今天百科达人给各位分享怎么往应用助手里添加应用的知识,其中也会对应用助手怎么添加微信进行解释,如果能...
客厅放八骏马摆件可以吗(家里摆...
今天给各位分享客厅放八骏马摆件可以吗的知识,其中也会对家里摆八骏马摆件好吗进行解释,如果能碰巧解决你...